CoW帮我成为时间管理大师后,被封号了
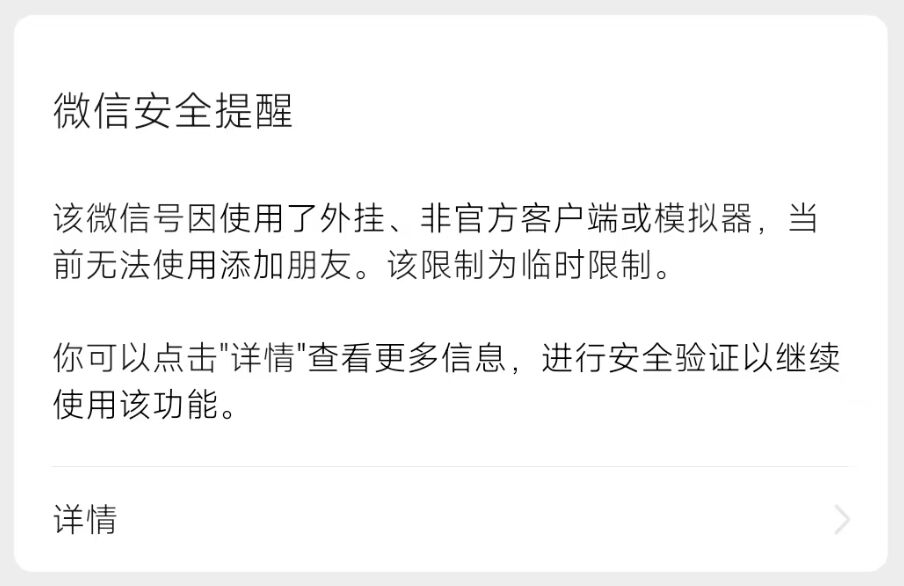
我的微信机器人挂了,用chatgpt-on-wechat项目,这个项目使用的itchat接入微信,这个项目果然很容易被查啊。
1、又双叒叕忘了事情
经常被客户支配的打工人一定有过同样的感受:
↑生成的界面图,非真实发生,但是也差不多。到达约定时间的时候才想起来有这么回事,免不了要道歉+赶工。
为了拯救自己被工作掏空的身体,
以前用的记录日程工具,得在记录的时候打开APP、填写内容、选择时间,做一堆操作设置一个日程,太麻烦了,用不了多长时间就弃用了,直到我看到了Dola。

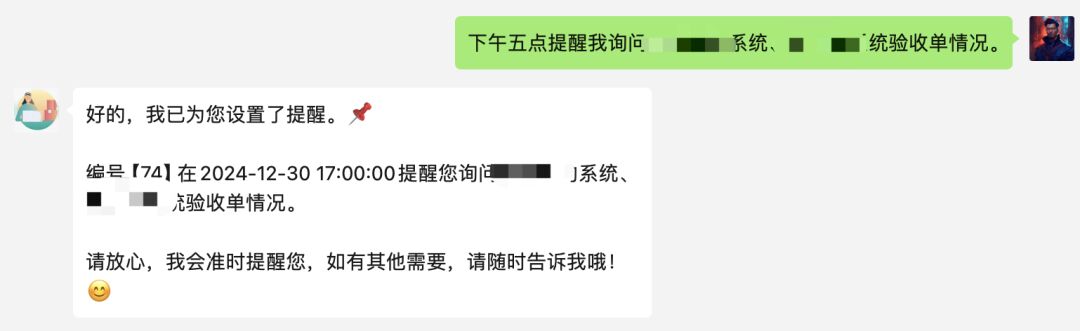
↑就是它,工作中很多日程都是在和客户沟通中定下来的,跟客户约定好时间,把内容直接转发给Dola,它会帮我设置日程,并到时间发消息提醒我,而且支持将日程同步到电脑日历上。
但是... 就在我已经养成使用Dola做日程提醒、工作记录时,Dola发布公告,微信端下线。
一、我的AI助理初建
chatgpt-on-wechat(简称CoW)项目是基于大模型的智能对话机器人,支持微信公众号、企业微信应用、飞书、钉钉接入,支持主流的大模型,能处理文本、语音和图片,通过插件访问操作系统和互联网等外部资源,支持基于自有知识库定制企业AI应用。
CoW中Plugin模块是一个特别棒的设计,可以过滤用户的输入输出,根据设定的规则触发不同的Plugin,本身项目已经内置了有很多Plugin,但是作为AI助理来说还是不够。
为了复刻Dola的日程能力,我在Plugin中新增了日程模块:
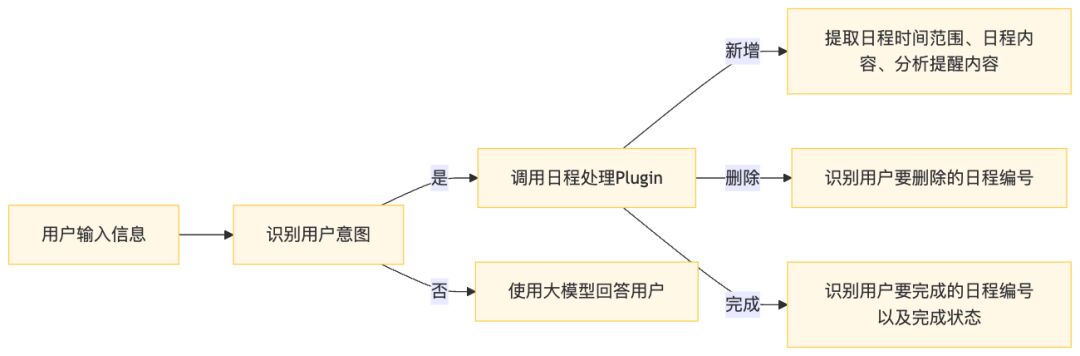
实现的方法很简单,从对话记录中截取最后3轮对话内容,将对话内容发给大模型,让大模型提取内容中的日程意图、日程信息。
schedule_intention_prompt ="""
```
{content}
```
从上面对话中分析用户用户意图:添加日程、删除日程、查询日程、更新日程状态(完成\未完成)
执行要求:
0 **根据不同意图在输出时使用不同前缀**,前缀信息(添加:add、删除:del、查询:query、更新/完成:update),例如add八点钟提醒我联系张明明
1 分析对话内容中的用户的真实意图,提取日程相关信息;
2.1 例如添加日程应包含时间、事件,例如:后天早上九点去上班,如果有多个时间、事件,需要换行输入。
2.2 删除日程需要用户内容中包含“取消”、“删除”、“删”等明确的删除要求
2.3 查询日程需要有明确的查询要求
2.4 用户提出完成/未完成的意图
你的输出:
"""
schedule_add_prompt ="""
```
{content}
```
分析用户意图,You need to format the output as JSON Array:
[{"type":"[type]","event":"[event]","start_time":"[start_time]","message":"[message]"}]
type:add
event:事件说明
start_time:时间必须为YYYY-MM-DD HH:mm:ss格式,时间并非必须,如果用户没有要求,则不包含start_time
message:在到达日程时间时需要提醒用户的消息(不要包含时间),如果是腾讯会议,内容中必须有会议编号,语气为{role}
当前时间:{now_time}
you output:
"""
schedule_del_prompt ="""
```
{content}
```
分析用户意图,You need to format the output as JSON Array:
[{"type":"[type]","id":"[id]"}]
type:del
id:需要删除日程的编号,如果输入信息中没有则返回0
you output:
"""
schedule_query_prompt ="""
```
{content}
```
分析用户意图,You need to format the output as JSON Array:
[{"type":"[type]","start_time":"[start_time]","end_time":"[end_time]"}]
type:query
start_time:时间必须为YYYY-MM-DD HH:mm:ss格式
end_time: 查询时间范围,例如27日,需要start_time:2024-11-27 00:00:00,end_time:2024-11-28 00:00:00 **时间范围必须跨天**
当前时间:{now_time}
you output:
"""
schedule_update_prompt ="""
```
{content}
```
分析用户意图,You need to format the output as JSON Array:
[{"type":"[type]","id":"[id]","status":"[status]"}]
type:update
id:获取需要更新的日程编号数字,必须为数字,多个id需要返回JSON数组,如果输入信息中没有则返回0
status:更新意图,从“完成”、“未完成中选择
you output:
"""二、增加了更多能力
在初步构建了AI助理的基础功能后,我意识到在实际工作中,还需要更多的辅助功能来提升效率和用户体验。于是,我开始着手扩展机器人的能力,具体包括以下几个方面:
1.销售问答记录在与客户的互动过程中,销售团队经常会将客户提问转述给我或者其他技术团队成员,因为涉及到的产品多而且杂乱,客户的问题有时既具体又复杂,难以立即解答。有些问题涉及技术细节、产品使用场景,或者是服务条款的解释,这些都需要深入沟通并提供详细解答。为了确保所有客户的疑问都能得到及时和准确的回答,团队需要对这些提问进行跟踪和整理,避免重复解答并提高问题响应效率。于是我在机器人中加入了销售问答记录模块。每当与客户的对话中涉及到关键问题或解答时,@机器人,机器人会自动保存这些内容,并按照客户分类整理,方便日后查阅和分析。
2.客户意向记录我们团队有非常多的软件产品,但由于演示资源有限(如服务器资源、小程序资源等),只能根据客户的具体需求来切换演示环境。为了更好地管理这些有限的资源,团队依赖于一套CRM系统来记录客户的演示需求,并根据这些需求调整销售策略。然而,现有的记录方式存在一定的不便之处,偶尔会出现错记或漏记的情况,导致团队在后续的客户跟进中出现信息不准确或响应不及时的情况。为了解决这一问题,为机器人增加了客户意向记录功能。当销售团队接到客户关于查看演示系统的意向时,销售人员只需要通过发送系统名称的消息给机器人,机器人会记录需求,并自动通知相关的运维成员。
3.接入飞书,提升数据收集和分析能力为了更高效地管理和分析机器人记录的数据,我将机器人的记录功能接入了飞书(Feishu)。通过与飞书的集成,所有销售问答记录、客户意向记录、日程记录以及订阅消息等数据都能自动同步到飞书的多维表格中。这不仅简化了数据的集中管理流程,还利用飞书多维表格的数据分析工具,对收集到的信息进行深入分析和可视化展示。
分享一些飞书多维表格的操作工具:
import json
from lark_oapi import Client,LogLevel,JSON
from lark_oapi.api.bitable.v1 import CreateAppTableRecordRequest,AppTableRecord,CreateAppTableRecordResponse,\
DeleteAppTableRecordRequest,DeleteAppTableRecordResponse,SearchAppTableRecordRequest,\
SearchAppTableRecordRequestBody,Sort,SearchAppTableRecordResponse,FilterInfo,Condition,\
UpdateAppTableRecordResponse,UpdateAppTableRecordRequest,BatchGetAppTableRecordRequest,\
BatchGetAppTableRecordRequestBody,BatchGetAppTableRecordResponse
from common.log import logger
class FeishuBitable:
def __init__(self,app_id,app_secret):
self.app_id = app_id
self.app_secret = app_secret
# 创建client
self.client = Client.builder() \
.app_id(self.app_id) \
.app_secret(self.app_secret) \
.log_level(LogLevel.DEBUG) \
.build()
def insert_record(self,app_token,table_id,fields):
# 构造请求对象
request:CreateAppTableRecordRequest = (CreateAppTableRecordRequest.builder() \
.app_token(app_token).table_id(table_id) \
.request_body(AppTableRecord.builder()
.fields(fields)
.build()) \
.build())
# 发起请求
response:CreateAppTableRecordResponse = self.client.bitable.v1.app_table_record.create(request)
# 处理失败返回
if not response.success():
logger.error(
f"client.bitable.v1.app_table_record.create failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}, resp: \n{json.dumps(json.loads(response.raw.content), indent=4, ensure_ascii=False)}")
return None
# 处理业务结果
logger.info(JSON.marshal(response.data,indent=4))
record = response.data.record
search_record = self.read_by_record_id(app_token,table_id,record.record_id)
if not search_record:
search_record = record
return search_record
def read_by_record_id(self,app_token,table_id,record_id):
"""
读取记录
"""
records = self.read_by_record_ids(app_token,table_id,[record_id])
if not records or len(records) ==0:
return None
return records[0]
def read_by_record_ids(self,app_token,table_id,record_ids):
"""
读取记录
"""
# records = self.query_record(app_token,table_id,query_config=FilterInfo.builder().conditions(
#[Condition.builder().field_name("record_id").operator("is").value([record_id]).build()]).conjunction(
#"and").build())
request:BatchGetAppTableRecordRequest = BatchGetAppTableRecordRequest.builder() \
.app_token(app_token).table_id(table_id) \
.request_body(BatchGetAppTableRecordRequestBody.builder()
.record_ids(record_ids)
.with_shared_url(False)
.automatic_fields(True)
.build()) \
.build()
# 发起请求
response:BatchGetAppTableRecordResponse = self.client.bitable.v1.app_table_record.batch_get(request)
if not response.success():
logger.error(
f"client.bitable.v1.app_table_record.batch_get failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}, resp: \n{json.dumps(json.loads(response.raw.content), indent=4, ensure_ascii=False)}")
return None
# 处理业务结果
logger.info(JSON.marshal(response.data,indent=4))
records = response.data.records
records = self._to_entitys(records)
return records
def delete_record(self,app_token,table_id,query_config):
"""
删除记录
"""
records = self.query_record(app_token,table_id,query_config=query_config)
if not records or len(records) ==0:
return0
for record in records:
record_id = record.get('feishu_field_id')
# 构造请求对象
request:DeleteAppTableRecordRequest = DeleteAppTableRecordRequest.builder() \
.app_token(app_token).table_id(table_id).record_id(record_id) \
.build()
# 发起请求
response:DeleteAppTableRecordResponse = self.client.bitable.v1.app_table_record.delete(request)
# 处理失败返回
if not response.success():
logger.error(
f"client.bitable.v1.app_table_record.delete failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}, resp: \n{json.dumps(json.loads(response.raw.content), indent=4, ensure_ascii=False)}")
continue
# 处理业务结果
logger.info(JSON.marshal(response.data,indent=4))
return len(records)
def update_by_record_id(self,app_token,table_id,record_id,update_record):
"""
更新记录
"""
# 构造请求对象
request:UpdateAppTableRecordRequest = UpdateAppTableRecordRequest.builder() \
.app_token(app_token).table_id(table_id).record_id(record_id) \
.request_body(AppTableRecord.builder()
.fields(update_record)
.build()) \
.build()
# 发起请求
response:UpdateAppTableRecordResponse = self.client.bitable.v1.app_table_record.update(request)
# 处理失败返回
if not response.success():
logger.error(
f"client.bitable.v1.app_table_record.update failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}, resp: \n{json.dumps(json.loads(response.raw.content), indent=4, ensure_ascii=False)}")
return False
# 处理业务结果
logger.info(JSON.marshal(response.data,indent=4))
return True
def update_record(self,app_token,table_id,query_config,update_record):
"""
更新记录
"""
records = self.query_record(app_token,table_id,query_config=query_config)
error_num =0
for record in records:
record_id = record.get('feishu_field_id')
# 构造请求对象
request:UpdateAppTableRecordRequest = UpdateAppTableRecordRequest.builder() \
.app_token(app_token).table_id(table_id).record_id(record_id) \
.request_body(AppTableRecord.builder()
.fields(update_record)
.build()) \
.build()
# 发起请求
response:UpdateAppTableRecordResponse = self.client.bitable.v1.app_table_record.update(request)
# 处理失败返回
if not response.success():
logger.error(
f"client.bitable.v1.app_table_record.update failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}, resp: \n{json.dumps(json.loads(response.raw.content), indent=4, ensure_ascii=False)}")
error_num +=1
if error_num >0:
return False
# 处理业务结果
logger.info(JSON.marshal(response.data,indent=4))
return True
def query_record(self,app_token,table_id,query_fields=None,sort_configs=None,query_config=None):
"""
查询记录
"""
request_body_builder = SearchAppTableRecordRequestBody.builder()
if query_fields:
request_body_builder.field_names()
if sort_configs:
request_body_builder.sort(sort_configs)
if query_config:
request_body_builder.filter(query_config)
request_body_builder.automatic_fields(True)
request_body = request_body_builder.build()
# 构造请求对象
request:SearchAppTableRecordRequest = SearchAppTableRecordRequest.builder() \
.app_token(app_token).table_id(table_id) \
.request_body(request_body) \
.build()
# 发起请求
response:SearchAppTableRecordResponse = self.client.bitable.v1.app_table_record.search(request)
# 处理失败返回
if not response.success():
logger.error(
f"client.bitable.v1.app_table_record.query failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}, resp: \n{json.dumps(json.loads(response.raw.content), indent=4, ensure_ascii=False)}")
return
# 处理业务结果
logger.info(JSON.marshal(response.data,indent=4))
data_items = response.data.items
# Extract relevant fields into desired format
result = self._to_entitys(data_items)
return result
def _to_entitys(self,records):
result =[]
for item in records:
fields = item.fields
extracted ={key:fields[key][0]["text"]if isinstance(fields[key],list) else fields[key]
for key in fields}
feishu_field_id = item.record_id
extracted["record_id"]= feishu_field_id
extracted["feishu_field_id"]= feishu_field_id
result.append(extracted)
return result
def read_record(self,app_token,table_id,query_fields=None,query_config=None):
"""
读取记录
"""
# 构造请求对象
results = self.query_record(app_token,table_id,query_fields=query_fields,query_config=query_config)
if len(results) >1:
raise Exception("查询到多条记录")
elif len(results) ==1:
return results[0]
else:
return None
def read_by_id(self,app_token,table_id,id):
"""
读取记录
"""
records = self.read_by_record_ids(app_token,table_id,[id])
if not records or len(records) ==0:
return None
return records[0]
def read_by_ids(self,app_token,table_id,ids):
results = self.query_record(app_token,table_id,query_config=[
Condition.builder().field_name("id").operator("is").value(ids).build()])
return results三、让机器人能思考
在实际使用中,我发现,插件通过关键字触发的方式过于死板,很多时候会因为输入错误的关键字而出现重复发送或未记录成功的情况,影响了用户体验。于是,我决定引入思考插件,增强机器人的灵活性。
1.增加思考插件
思考插件的引入,使得机器人能够在接收到消息后,首先思考用户的意图,再根据分析结果自动选择合适的插件进行处理。这样,无论用户输入的是哪种方式的需求,机器人都能智能判断并做出相应操作,避免了传统方式中由于关键字错误而导致的重复发送或遗漏记录的问题。例如,若用户的表达方式并没有准确地触发某个关键字,机器人仍然能够根据上下文内容识别出用户的意图,并执行相应的功能。
2.使用Function Calling
除了思考插件,我还尝试引入了Function Calling机制,进一步提升机器人的智能化水平。Function Calling可以让机器人在执行任务时,不仅仅依赖预设的规则,而是能通过调用外部功能接口(如OpenAI的Function Calling能力)来实现任务的选择和执行。
与思考插件类似,Function Calling通过分析用户的需求,智能选择需要调用的插件或外部服务,实现更为灵活的操作。当用户的需求涉及到多个任务时,机器人能够综合判断并优先选择最适合的插件执行。例如,若用户要求添加日程,机器人不仅仅依赖特定的关键字,而是会分析消息的上下文,判断用户是否需要设置提醒,并根据Function的配置提取参数。
分享一些Function Calling的实现代码:
import inspect
import os
import importlib.util
import traceback
class Scope(Enum):
"""
作用域
"""
ALL="all"
GROUP="group"
PRIVATE="private"
# 定义注解
def register(name,skill,description,parameters,enable=True,scope=Scope.PRIVATE):
def decorator(func):
# 附加元数据到函数上
func._function_meta ={
"name":name,
"skill":skill,
"enable":enable,
"scope":scope,
"description":description,
"parameters":parameters,
}
return func
return decorator
class FunctionFactory:
_registry ={}
@classmethod
def register_function(cls,func):
"""
注册函数到工厂,函数必须带有 _function_meta 元数据
"""
meta = getattr(func,"_function_meta",None)
if meta:
name = meta["name"]
cls._registry[name]={
"function":func,
"description":meta["description"],
"parameters":meta["parameters"],
"scope":meta["scope"],
"enable":meta["enable"],
"skill":meta["skill"]
}
@classmethod
def get_function(cls,name):
"""
根据名称获取注册的函数
"""
return cls._registry.get(name,None)
@classmethod
def list_functions(cls):
"""
列出所有注册的函数
"""
return[
{"name":key,"description":value["description"],"parameters":value["parameters"],
"skill":value["skill"]}
for key,value in cls._registry.items()
]
@classmethod
def get_functions_for_openai(cls):
"""
返回符合 OpenAI Function Calling 的 functions 格式的描述
"""
return[
{
"name":name,
"description":meta["description"],
"parameters":meta["parameters"],
"scope":meta["scope"],
"enable":meta["enable"],
"skill":meta["skill"]
}
for name,meta in cls._registry.items()
]
@classmethod
def scan_directory(cls,base_dir):
"""
扫描目录及其子目录,动态加载所有 .py 文件中的函数
"""
base_dir = os.path.abspath(base_dir)
for root,_,files in os.walk(base_dir):
for file in files:
if file.endswith(".py") and not file.startswith("__"):
file_path = os.path.join(root,file)
cls._import_and_register(file_path)
@classmethod
def _import_and_register(cls,file_path):
"""
动态导入文件中的方法并注册
"""
module_name = os.path.splitext(os.path.basename(file_path))[0]
spec = importlib.util.spec_from_file_location(module_name,file_path)
module = importlib.util.module_from_spec(spec)
try:
spec.loader.exec_module(module) # 加载模块
print(f"Successfully loaded module: {module_name}")
# 遍历模块中的所有方法
for name,obj in inspect.getmembers(module,inspect.isfunction):
cls.register_function(obj) # 注册每个函数
except Exception as e:
print(f"Failed to load module {module_name} from {file_path}: {e}")
@classmethod
def execute_function_call(cls,function_name,arguments,fixed_params):
"""
根据 ChatGPT 的 function_call 请求,执行对应的本地函数
"""
func = cls.get_function(function_name)
if not func:
return{"error":f"Function '{function_name}' not found."}
try:
if fixed_params:
arguments ={**fixed_params,**arguments}
# 执行函数并返回结果
return func["function"](**arguments)
except Exception as e:
traceback.print_exc()
return{"error":str(e)}写完之后再看文章,真的是又臭又长,而且还水了字数。
微信机器人已经没救了,准备转战钉钉,不过钉钉的免费版调用有次数限制,又是一个门槛。