阿里达摩院开源多模态AI大模型:VideoLLaMA3!
在AI领域,视频理解一直是技术攻坚的难点,视频不仅包含复杂的时空信息,还需结合语言生成能力进行多模态交互。
近日,阿里巴巴达摩院开源了VideoLLaMA3,一款仅7B参数的多模态视频-语言模型,在通用视频理解、时间推理和长视频分析中刷新SOTA(State-of-the-Art)成绩,同时提供轻量级2B版本适配端侧场景。

用户现可通过HuggingFace直接体验其图像和视频问答能力
VideoLLaMA3 是什么?
VideoLLaMA3 是达摩院推出的一种更高级的多模态基础模型,专注于图像和视频理解。
它以视觉为中心构建,核心设计理念包括以视觉为中心的训练范式和以视觉为中心的框架设计。
为什么VideoLLaMA3值得关注?
性能碾压同级模型
在通用视频理解、时间推理、长视频分析三大核心任务中,VideoLLaMA3全面超越同参数规模的开源模型,尤其在数学推理(MathVista)和文档理解(InfoVQA)任务中表现突出。
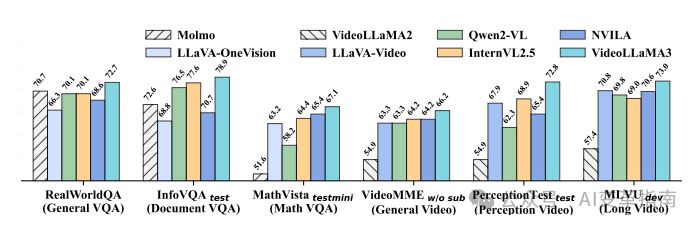
仅用3M视频文本数据训练,却通过高质量图像数据奠定基础,证明了“以图像为中心”范式的有效性。
多模态交互与多语言支持
支持图像、视频输入与自然语言问答,例如上传《蒙娜丽莎》图片提问历史意义,或分析视频中“熊吃寿司”的异常行为,回答精准简洁。支持跨语言生成,适用于国际化场景,如多语言视频内容分析。

高效轻量,端云皆宜
7B参数模型兼顾性能与效率,2B版本专为端侧设备优化,在图像理解任务中同样表现优异
如何使用呢?
达摩院已公开模型代码、训练细节及技术论文,开发者可基于GitHub快速部署。
图像Demo:
视频Demo:
GitHub项目地址: