单卡复现 DeepSeek R1 Zero教程来了!
推荐语
DeepSeek R1 Zero单卡复现技术大揭秘,性价比与性能的完美结合!
核心内容:
1. 单卡复现DeepSeek R1 Zero的可行性分析
2. Unsloth+LoRA技术详解,如何优化性能降低资源消耗
3. 环境搭建与复现步骤指南,轻松上手实践

杨芳贤
53A创始人/腾讯云(TVP)最具价值专家
Datawhale干货
Datawhale干货
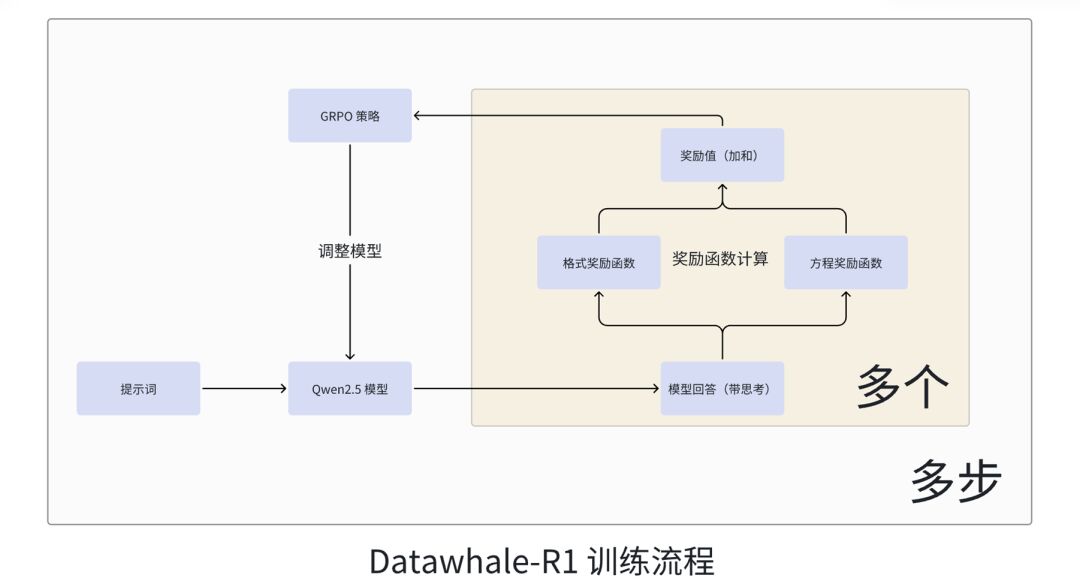
本文中仅展示与前文有差异的代码部分,同时我们提供了完整的训练代码,请在文末获取。
注意:为了兼容 Unsloth,我们需要安装特定版本的 trl。具体命令如下:
大部分配置与之前的Datawhale-R1.yaml文件保持一致。为了支持单卡复现 R1 Zero,我们做了如下调整:
LoRA微调参考:https://zhuanlan.zhihu.com/p/663557294
启动训练的代码很简单,由于我们只需要单卡,不需要涉及到配置复杂的 Accelerate 库,直接运行以下代码即可运行。
基于 Unsloth 框架,我们对原始代码做了简化和优化。主要思路有两点:
在执行强化学习训练的代码之前,我们添加了两行代码,利用PatchFastRL函数对某些 RL 算法(如 GRPO)进行“打补丁”。这个操作实际上在底层优化了计算图、减少了冗余计算,从而加速训练过程。
参考自:https://unsloth.ai/blog/r1-reasoning
模型量化参考:LLM量化综合指南(8bits/4bits)https://zhuanlan.zhihu.com/p/671007819

