清华推出小公司本地部署满血DeepSeek方案!个人还是别尝试了!
朋友们!今天必须给你们分享一个AI圈的热点事件!
清华大学的KVCache.AI团队搞了个叫KTransformers的开源项目,直接让咱们这些普通玩家也能在家用一张4090显卡跑动千亿参数的“满血版”DeepSeek-R1!
(是的,就是那个之前动不动就宕机、租一小时服务器得卖肾的模型!)
本地运行千亿模型,4090单卡搞定?
以前想跑DeepSeek-R1这种671B参数的巨无霸模型,要么得花200万租8卡A100服务器,要么只能玩“阉割版”模型(参数缩水90%那种)。
但现在,清华团队直接甩出王炸—仅使用 14GB VRAM 和 382GB DRAM 运行其 Q4_K_M 版本,在家流畅运行满血版DeepSeek-R1!
(问题来了,谁家有382G内存的电脑啊?!个人还是别考虑部署了)
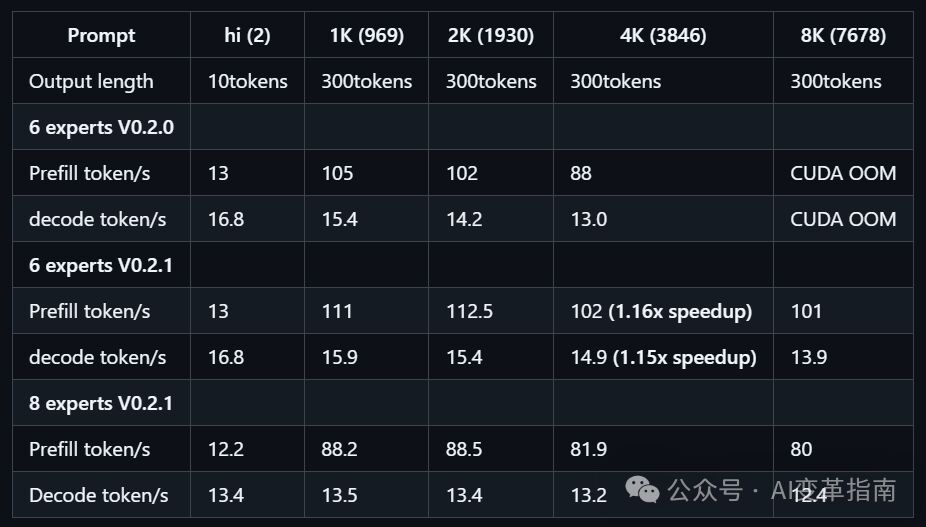
实测数据离谱:
预处理速度最高286 tokens/s(比llama.cpp快28倍!)
推理生成速度14 tokens/s(3090显卡也能跑到9.1 tokens/s)

也就是说,写代码、分析长文档这种需要上万Token的任务,直接从“等咖啡凉了”变成“秒级响应”!
技术揭秘:如何榨干硬件性能?
这项目为啥这么猛?核心就俩字:“分工”!
让CPU和GPU“各司其职”:
GPU负责高计算强度的部分(比如Attention层),用Marlin算子暴力加速,效率提升3.87倍!
CPU处理稀疏的MoE专家矩阵(比如用英特尔的AMX指令集),预填充速度直接起飞!

MoE架构的“偷懒哲学”:
DeepSeek-R1是混合专家模型,每次推理只用部分参数。团队把不活跃的专家模块卸载到CPU内存,显存需求直接从320G砍到24G!
“抠门级”优化:
用4bit量化压缩参数,减少GPU/CPU通信断点,甚至一次解码只调用一次CUDA Graph,功耗低到80W!
成本直降95%,中小团队福音
最狠的是成本!有老哥算过账:
显卡:4090(24G)约1.5万
CPU+主板:双路至强Gold 6454S +主板≈2万
内存:1T DDR5≈3万
整套不到7万,对比A100服务器200万的天价,直接省出一套房首付!就算租云服务器,每小时几千块也够喝一壶的。
不只是DeepSeek,未来可期!
KTransformers不只支持DeepSeek,还能兼容各种MoE模型,甚至提供了ChatGPT式网页界面和HuggingFace兼容API,小白也能一键开跑!团队还预告了v0.3版本要整合至强6的128核CPU,未来速度还能再翻倍!
最后说点人话:这项目简直是“技术平权”的里程碑!以前大模型是巨头们的游戏,现在咱们用消费级硬件也能玩转千亿参数。
虽然目前对硬件配置还有点要求,但至少让普通开发者看到了希望——AI普惠化,真的不是梦!
(友情提示:想尝鲜的朋友,记得先备好1T内存和4090显卡!)
https://github.com/kvcache-ai/ktransformers
好了,今天的内容就分享到这里希望你们喜欢!欢迎关注、点赞和分享!