OpenAI新模型让Agent“开口说话”,但模仿谁开发者、用户说了都不算
3月21日消息,OpenAI发布了三款全新的语音模型,包括两款语音转文本(STT)模型GPT-4o Transcribe和GPT-4o Mini Transcribe,以及一款文本转语音模型GPT-4o Mini TTS,这三款模型专为支持语音智能体而设计,现已面向全球开发者开放。

与最初的Whisper模型相比,GPT-4o Transcribe和GPT-4o Mini Transcribe在单词错误率(WER)和语言识别准确性方面均有显著提升,在包括FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech)——涵盖100多种语言的多语言语音基准测试——在内的基准测试中实现了更低的WER,其中英语、法语等语种当中,错误率远低于包括gemini-2.0-flash在内的模型。
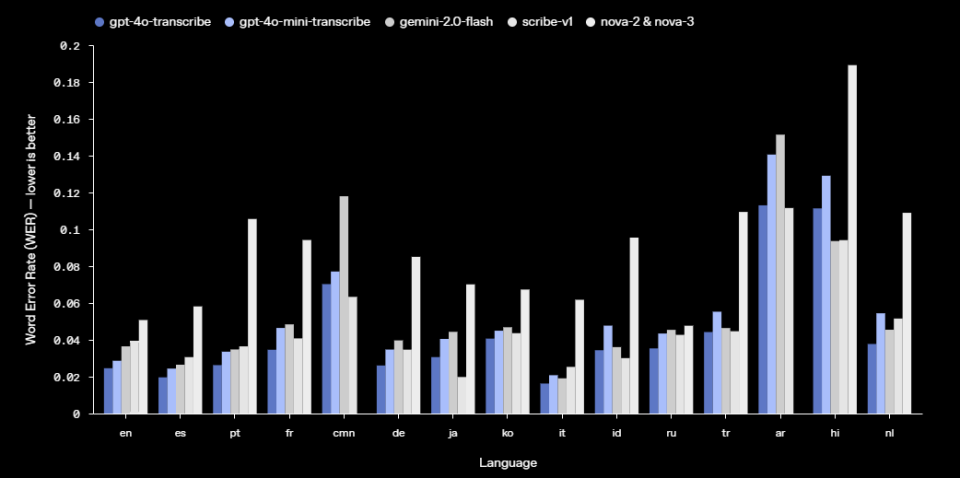 单词错误率(WER)对比:单词错误率通过计算错误转录单词的百分比来衡量语音识别模型的准确性。WER越低意味着错误越少,性能越好
单词错误率(WER)对比:单词错误率通过计算错误转录单词的百分比来衡量语音识别模型的准确性。WER越低意味着错误越少,性能越好
根据OpenAI提供的数据,GPT-4o Transcribe在英语基准测试中,错误率不到3%。
OpenAI表示,这些新的语音转文本模型能够更好地捕捉语音的细微差别,减少误识别,并提高转录的可靠性,尤其在处理口音、嘈杂环境和语速变化等复杂场景时表现尤为出色,目前相关模型现已通过语音转文本API提供。
前两款模型主打准确率提升,GPT-4o Mini TTS模型则具有更好的可操控性。
 OpenAI官方提供了多种不同情景下的Agent参考发音
OpenAI官方提供了多种不同情景下的Agent参考发音
OpenAI称开发者不仅可以“指示”模型说什么,还能指定怎么说(指定的情绪进行表达),从而为包括客户服务到创意故事叙述在内的多种应用场景提供更加定制化的体验,该模型现已通过文本转语音API提供。
需要注意的是,这些文本转语音模型可使用的音色现阶段仅限于OpenAI人工预设的语音。OpenAI表示,会监控确保这些语音始终符合合成语音的预设标准。
OpenAI表示,过去几个月里,该公司始终致力于提升基于文本的智能体(即能够独立为用户完成任务的系统)的智能性、功能性和实用性,推出了如Operator、Deep Research、Computer-Using Agents和内置工具的Responses API等产品。然而,为了使智能体真正有用,用户需要能够通过更深层次、更直观的方式与其互动,而不仅仅通过文本进行交流。
这些新的语音模型将使开发者能够构建更强大、可定制且智能的语音智能体,从而提供更具价值的服务。这些模型在准确性和可靠性,尤其是在处理口音、嘈杂环境和语速变化等复杂场景时,表现优异。这些改进提升了转录的可靠性,使得这些模型特别适用于客户呼叫中心、会议记录转录等应用场景。(腾讯科技特约编译金鹿)