GPT-4o原生图像热闹之后,看DeepSeek,看统一多模态大模型
GPT-4o推出原生图像掀起的热潮不减。OpenAI故伎重演,光芒盖过了同时发布的DeepSeek-V3 0324和Gemini 2.5 pro。
无数用户使用吉卜力画风生成和变化图片,乐此不疲。就连奥特曼也换了头像,得意地说:
“我们的GPU都熔化了”。
然后宣布对使用量临时设限,即使放开之后,ChatGPT免费用户每天只能生成三张图。
这次由多模态大模型原生出来的图像,已经融入了大模型的语言、推理、上下文学习等能力,有时体现出令人震撼的能力——它能让人感到画片背后所要表达的意味。
大模型原生出来的能力是如此强大,让那些五花八门的AI工具、垂类的智能体、甚至Midjourney和Stable Diffusion,开始怀疑人生。
统一多模态大模型
OpenAI并没有为此而改变4o的名称,它还叫4o,显示OpenAI正在构建强大的统一多模态大模型。
原生图像能准确地渲染文字、细腻地理解提示、并且调动起4o内在的知识库、交谈的上下文;还能转变上传的图片,以及用它们来启发更有创意的视觉效果。
正如OpenAI所说,图像生成本来就应该是大语言模型的主要能力。关于训练,有一小段高度概括的文字:
我们在网络图像与文本的联合分布上训练了模型,不仅学习图像与语言之间的关系,也学习图像彼此之间的关联。结合强力的后训练策略,最终得到的模型展现出令人惊讶的视觉流畅性,能够生成实用、一致且具备上下文感知能力的图像。
从中可以看到,一个原生的、统一的多模型大模型,可以把语言、视觉和声音的理解有机地结合在一起,更加接近世界知识。
正因为图像生成已经内嵌于4o中,用户可以通过自然对话来转变图像。而且由于4o模型是在上下文中构建图像和文本的,图像的一致性得到保持。例如,如果设计一个游戏中的形象,用户对它进行修正和试样,在多次迭代之后,形象仍不会走样。它还解决了图中嵌入文字的问题,并且产生了图文并茂的效果(但我们试用发现,仍然不能处理好图中较多的中文)。
而且由于它原生嵌入在我们全模态模型 GPT-4o 的深层架构中,4o 图像生成可以调动模型所掌握的全部知识,将这些能力以微妙而富有表现力的方式发挥出来。
模型即产品。大模型的第一性原理,仍然需要不断提升理解的境界。
怎么训练出来的
OpenAI在其技术报告中,重点谈了安全。对于训练提到了这么几点:
系统卡重点谈了安全,提及这是一种自回归模型。“与采用扩散模型的 DALL·E 不同,4o 图像生成是一种自回归模型,原生嵌入在 ChatGPT中。”
清华与字节的研究人员,去年底曾提出了 ACDIT(Autoregressive blockwise Conditional Diffusion Transformer),一种将扩散过程与自回归范式融合的模型。根据论文,具体的工作机制如下:
实现ACDiT 并不难,仅需在现有的扩散Transformer架构上添加一个 Skip-Causal Attention Mask 即可。在推理过程中,生成以两个阶段交替进行:一是在块内进行条件扩散去噪(以完整的干净上下文为条件),二是以自回归方式生成新的块,并将其作为新的上下文追加进来。借助这种方式,可以使用 KV-Cache 来加速推理过程。
总体而言,ACDiT 具有以下天然优势:
(i)ACDiT 同时学习了块与块之间的因果依赖(通过自回归建模)以及块内部的非因果依赖(通过扩散建模);
(ii)ACDiT 以 clean 的连续视觉特征作为输入,无需进行向量量化,从而提升了模型在完成生成任务后向视觉理解任务迁移的能力;
(iii)ACDiT 可以充分利用 KV-Cache,在任意长度下实现灵活的自回归生成,并有潜力结合文本领域最新的长上下文技术,进一步拓展至长视频生成任务。
如图所示:
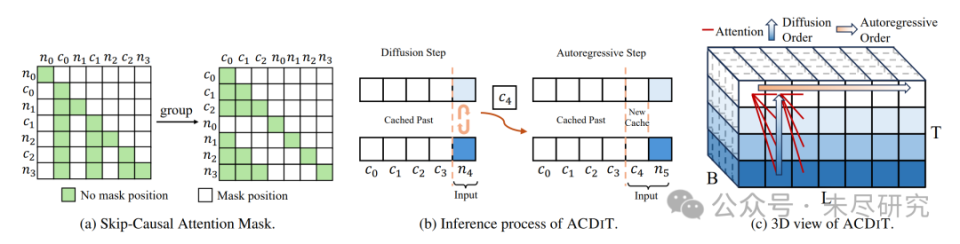
(a):对于每个带噪块 nin_i,它只能关注之前的 clean 潜在块 c0,c1,…,ci−1c_0, c_1, \ldots, c_{i-1} 以及它自己对应的 clean 表示。每个 clean 块 cic_i 只能关注之前的 clean 潜在块。
(b):ACDiT 可以高效地利用 KV-Cache 进行自回归推理。
(c):ACDiT 的三维视图,其中 B 表示块大小,L 表示块的数量,T 表示去噪的时间步。颜色越深表示噪声越高。
ACDiT不仅可以用来生成图像,而且可以用来生成视频。
DeepSeek的动作
ACDiT的共同一作是清华博士胡声鼎,相当了得。

因为是与字节合作的论文,他被科技媒体晚点报道将加入字节的AGI研究团队Seed Edge。
晚点称字节号称正要打造国内人才密度最高的AI研究团队,甚至张一鸣都亲自下场去见一些顶尖的博士和科学家。
但是已经有传闻,胡声鼎并没有加入字节,而是选择了DeepSeek。
DeepSeek创始人梁文锋,去年接受暗涌采访时,就已经表示要进入多模型大模型领域。他眼中的AGI,包括要应用于机器人领域。
以梁文锋在国内顶尖学校招收顶尖博士的做法,胡升鼎加入DeepSeek顺理成章。多模态与推理,正统一于下一代大模型中。
看起来已经成为一种趋势!自回归条件块注意力(autoregressive conditional block attention)或许就是我们统一多模态所需要的一切。

女艺术家对AI爆粗口
不久前,OpenAI以国家安全的名义,向白宫建言:必须给我们在知识产权保护方面松绑,否则我们将输给中国AI企业(DeepSeek)。
紧接着,OpenAI试图施压《纽约时报》放弃对其发起的诉讼。
4o推出图片生成和编辑功能之后,社交媒体上开始充斥着吉卜力风的图像和meme。
日本漫画大师宫崎骏是吉卜力工作室的主要创始人,其独特的艺术风格和深刻的主题,超越了文化和语言的障碍,经典作品《千与千寻》、《龙猫》在全球产生了巨大的影响力。
4o惊人的复制画风能力,加上之前Gemini稍早发布类似功能中,可以除去图像中的水印,以及马斯克的Grok模型,以言论自由之名更无忌惮地生成模仿,很快激起了许多艺术创作者的反击。
OpenAI有可能用吉卜力电影的数百万帧来训练其模型,否则怎能如此相似。OpenAI和 Google的最新工具,只要输入文本提示,只要动动嘴,就重现受版权保护作品的风格。这显然对艺术家和创意者的生存空间,又产生的前所未有的冲击和挤压,包括其中一部分人刚刚学会掌握的其他专用的图像生成工具。
OpenAI是否在对受版权保护的作品进行训练?如果是,这是否违反了版权法?但使用受版权保护的作品训练 AI 模型,是否属于“合理使用” (fair use),从而受到法律保护,这在一些法院依然是未决的问题。
有人用宫崎骏2016年对AI模仿的愤怒,也生成了一张吉卜力:“我简直恶心透了,AI在侮辱生活本身。”

这位女艺术家,已经愤怒得对AI爆粗口了。

原生图像提出了一个严峻的问题:AI如果能以如此高效的方式训练并模仿出所有的创作风格,那些艺术家、作家、创意者、创作者的工作价值何在?
这涉及到奥特曼所说的“创作自由”,还有科技右翼一直倡导的“言论自由”,在不断拓展AI的能力边界。这位Tech Bro高呼:
Memes always win!
GPU都被熔化了,不得不对用户设限了,难怪奥特曼需要5000亿美元的星际之门计划。

“释放创作自由”
AI放大的“创作自由”,人类艺术家的创作自由以及他们的版权,两者之间,如何平衡?
OpenAI在提出一种理念。其模型行为负责人Joanne Jang,把奥特曼的AI创作自由理论进行了系统化的阐述。
从中可以看出,OpenAI主张,因为AI在不断发展出新的能力,这些能力会同时给人类带来福利与风险,应该首先鼓励推出这些能力并释放福利,同时用一种新的责任、新的方法去控制可能产生的风险,而不是用现有的法律,一刀切地拒绝新的能力。
这样的问题,DeepSeek和Owen们,豆包和元宝们,如果想做出同样强大的统一多模态大模型,也无法回避。

(Joanne Jang,来源:个人X账号)
下面是她的博客文章:
为AI新能力制定政策的思考
我在OpenAI负责模型行为方面的工作。
本周,我们通过GPT-4o在 ChatGPT 中上线了原生图像生成功能。
这是一次特别的发布,原因有很多——其中之一是我们 CEO 山姆 所强调的:“这是我们在释放创作自由方面的新高峰”。
我想稍微展开说说,因为如果你不是深入AI领域,或者没有紧跟我们对模型行为的最新思考(什么?你居然没在空闲时间读那份60页的《模型规范》??),可能会很容易忽略这点。
简而言之:我们正在从对敏感领域的一刀切拒绝,转向一种更精细的策略,核心是防止现实世界中的实际伤害。 我们的目标是拥抱“谦逊”——承认我们仍有很多未知,并以便于学习和适应的方式前进。
图像具有直观的冲击力
图像有一种独特而强烈的力量,能带来难以比拟的愉悦与震撼。与文字不同,图像超越语言障碍,唤起多样的情绪反应,也能瞬间阐明复杂的想法。
正因为图像具有如此强烈的影响力,我们在制定相关政策和模型行为时,也感受到比以往发布更多的责任与分量。
对“新能力”的发布,态度也在演变
每当发布一种“看似全新”的能力,我们的视角也在不断演变:
信任用户的创造力,而不是依赖我们的假设。AI 实验室的员工不该决定什么是人们“可以”或“不可以”创造的。我们总是在发布之后被用户的创意所震撼,发现许多我们从未想象的用途——甚至是一些现在看来“理所当然”的场景,事先我们也根本没想到。
清楚看到风险,但不忽视用户日常使用中的价值。人们很容易专注于潜在的风险,而大范围的限制听起来总是最安全(也最简单)的。但我们常常会问自己:“我们真的需要更强大的 meme 生成能力吗?毕竟这些 meme 也可能被用来冒犯他人。”但我认为这种思维方式本身就是有问题的。它意味着日常的小乐趣、小幽默和连接必须为“最坏情况”让步,而这低估了这些微小瞬间对人们生活带来的真实改善。
重视那些我们未曾想象的可能性。也许是因为我们天然倾向于避免损失,我们很少认真思考“无所作为”的负面影响。有人称之为“看不见的墓地”,虽然这听起来有些阴郁。这些“新能力”往往会带来间接的积极影响——无数原本可能发生的互动、创新和想法,可能就因为我们过度担心最坏的情况而从未诞生。
决定政策的Day1考量
我们希望在保护现实安全的前提下,尽可能释放创造自由。以下是我们在首次发布时的一些政策案例:
公众人物:我们知道公众人物的图像生成很敏感,尤其是在新闻、讽刺和个人形象权益之间界线模糊的时候。我们希望政策对所有人都公平适用,不管“身份地位”为何。但我们不想扮演决定“谁够重要”的角色,因此我们引入了“主动退出名单”机制——任何可能被模型生成形象的人,都可以自行选择退出。
“冒犯性”内容:关于“冒犯性”,我们反思了哪些内容是不舒服,是因为它真的可能造成伤害,还是只是因为我们自己的偏好或不适。模型曾默认拒绝一些请求,比如“让这个人看起来更像亚洲人”或“让这个人更胖”,这其实在无意中暗示了这些特征本身是“冒犯的”。
仇恨符号: 我们清楚像纳粹符号这样的标志承载着深重的历史痛苦,但它们也可能出现在真正的教育或文化语境中。全面封禁反而可能抹除重要的对话和思想探索。因此我们正研发更精准的技术手段,识别并拦截有害滥用的情况。
未成年人:凡是涉及青少年的政策,我们都选择更加谨慎,优先保护未满 18 岁的用户,不论是在研究还是产品中。
最终,这些考量,加上我们在技术控制能力上的进步,引导我们制定了更具包容性的政策。我们理解这可能会被误读为“OpenAI 降低了安全标准”,但我个人认为,这种解读无法体现我们团队所投入的大量研究、深度讨论,以及对用户和社会的真诚关怀。
我有位同事 Jason Kwon 曾对我说过一句话:
“船停在港口最安全,模型如果什么都拒绝最安全。但那不是造船或训练模型的目的。”
未来,是靠想象力和冒险精神构建的。随着研究继续、社会反馈不断涌现,我们相信可以在“负责任”与“自由”之间不断找到新的平衡。我们的政策也将随现实反馈而持续更新——这不是失败,而正是我们“逐步部署”理念的核心。
--
参考论文及文章:
https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
https://reservoirsamples.substack.com/p/thoughts-on-setting-policy-for-new
https://arxiv.org/pdf/2412.07720
https://arxiv.org/pdf/2503.09573