Meta发布Llama 4模型 首次引入MoE模型提升效率
4月6日消息,Meta于美国当地时间周六发布了其最新开源人工智能软件Llama 4的首批模型,表明该公司正在争取在生成式AI投资竞赛中占得先机。

Meta此次发布提到了三款Llama 4模型,分别是Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth。其中,用户可以在Meta AI的WhatsApp、Messenger、Instagram Direct或Meta AI网站上尝试Llama 4 Scout和Llama 4 Maverick。
但规模最大、性能最强的Llama 4 Behemoth模型仍在训练中。 据Meta透露,这款“庞然大物”不仅在性能上碾压同类AI产品,还将作为“新模型的训练基石”。
Meta的数据显示,Llama 4 Maverick拥有4000亿参数,但在128个 “专家” 模型中只有170亿个活跃参数。Scout有1090亿个参数,16个 “专家” 模型,活跃参数也是170亿个。而Llama 4 Behemoth具有2万亿参数,仅活跃参数就有2880亿个,但Meta的博客帖子表示该模型仍在训练中,并未给出具体的发布时间。
这些模型的一个显著特点是它们都是多模态的——经过训练,可以接收和生成文本、视频和图像。
另一个特点是它们具有非常长的上下文窗口——Llama 4 Maverick的上下文窗口为100万个token,Llama 4 Scout为1000万个token,分别相当于1500页和15000页的文本,所有这些都可以在单次输入/输出交互中处理。这意味着用户理论上可以上传或粘贴多达7500页的文本,并从Llama 4 Scout获得相应的输出,这在医学、科学、工程、数学、文学等信息密集型领域将非常有用。
Meta首席产品官克里斯·考克斯3月曾表示,Llama 4将驱动具备新型推理与行动能力的AI智能体。这些智能体既能浏览网页,又能处理对消费者和企业有价值的多种任务。
Meta首席执行官马克·扎克伯格表示:“我们的目标是构建世界领先的AI,将其开源,并让全世界都能受益。”
他补充道:“我已经说过一段时间了,我认为开源AI将成为领先的模型,随着Llama 4的发布,这一目标正在成为现实。今天,Meta AI得到了重大升级。”
Meta将在4月29日举办首次LlamaCon AI大会,该公司还预计将在第二季度发布其独立的Meta AI聊天机器人应用程序。
Meta全面押注专家混合架构
Llama 4的所有三个模型都采用了“专家混合”(MoE)架构,这种架构最早由OpenAI和Mistral在之前的模型发布中推广,基本原理是将多个“专家”小模型整合为一个统一的大模型,以便处理不同的任务、领域和多种媒体格式。
据称,每个Llama 4模型都由不同的“专家”模型组成,运行效率更高,因为仅需调用与当前任务相关的“专家”及一个“共享专家”处理每个token,而非激活整个模型。
Meta在博客中解释:“所有参数均存储在内存中,但实际运行时仅需要激活部分参数。这降低了推理成本与延迟,Llama 4 Maverick甚至可在单颗英伟达H100 DGX主机上运行,也可以通过分布式推理实现最高效率。”
Scout和Maverick模型对公众开放,可以自托管,但Meta未公布官方API或托管定价。相反,Meta专注于通过开放下载和与Meta AI在WhatsApp、Messenger、Instagram和Web中的集成来进行分发。
据Meta估算,Llama 4 Maverick的推理成本为每百万个token 0.19美元到0.49美元(按输入输出3:1比例计算)。这使其在成本上远低于像GPT-4o这样的专有模型,后者的成本约为每百万个token 4.38美元。
强化推理能力与革命性训练技术MetaP
上述所有三款Llama 4模型——尤其是Maverick和Behemoth——都明确设计用于推理、编码和分步问题解决优化,但它们似乎并未展现出OpenAI“o”系列或DeepSeek R1那样的“思维链”式推理链条,而是直接对标GPT-4o、DeepSeek V3等传统多模态模型。不过Behemoth除外,其性能似乎在某种程度上可挑战DeepSeek R1。
此外,为了提升推理能力,Meta为Llama 4构建了专门的训练方案,包括:
——剔除50%以上“简单提示”,聚焦高难度监督微调
——采用渐进式强化学习循环,逐步增加提示复杂度
——实用pass@k评估与课程采样,强化数学、逻辑与编程能力
——引入MetaP新技术,它允许工程师在调整超参数(如分层学习率)后,将其泛化至不同规模的模型及token类型,同时保持模型行为一致性
其中,MetaP的突破性在于:通过小规模模型实验即可推导大规模模型的超参数,极大提升训练效率。业内人士评价:“这能省下大量时间和资金——不必在大模型上反复试错。”
这一技术对训练Behemoth这样的大模型尤为关键——该模型动用32000颗GPU,采用FP8精度,处理超30万亿token(是Llama 3训练数据的两倍),实现单卡390 TFLOPs算力。
与其他模型对比
Llama 4模型是非常强大的,与同等参数规模的其他模型相比,接近顶尖水平,但并未全面刷新性能记录。以下为与其他模型对比:
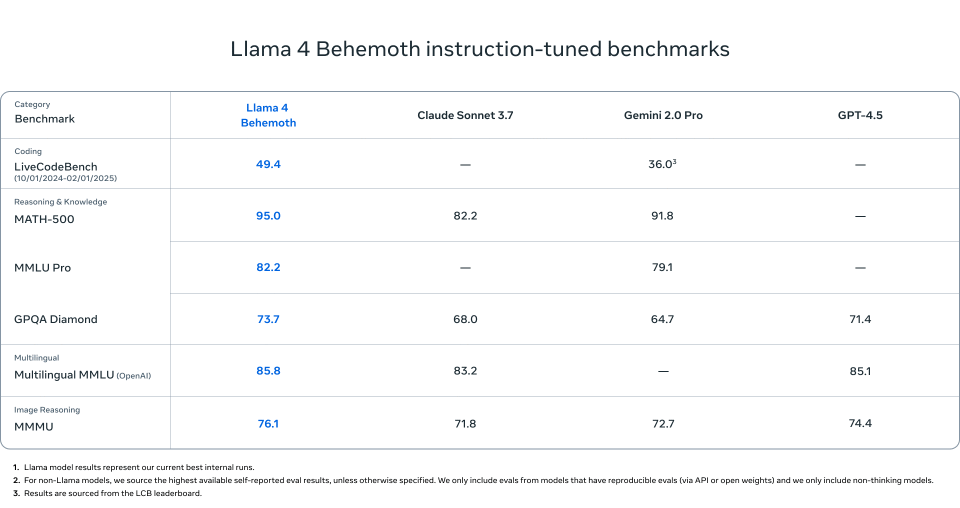
1.Llama 4 Behemoth
在以下任务上超越了GPT-4.5、Gemini 2.0 Pro和Claude Sonnet 3.7:
MATH-500 (95.0)
GPQA Diamond (73.7)
MMLU Pro (82.2)
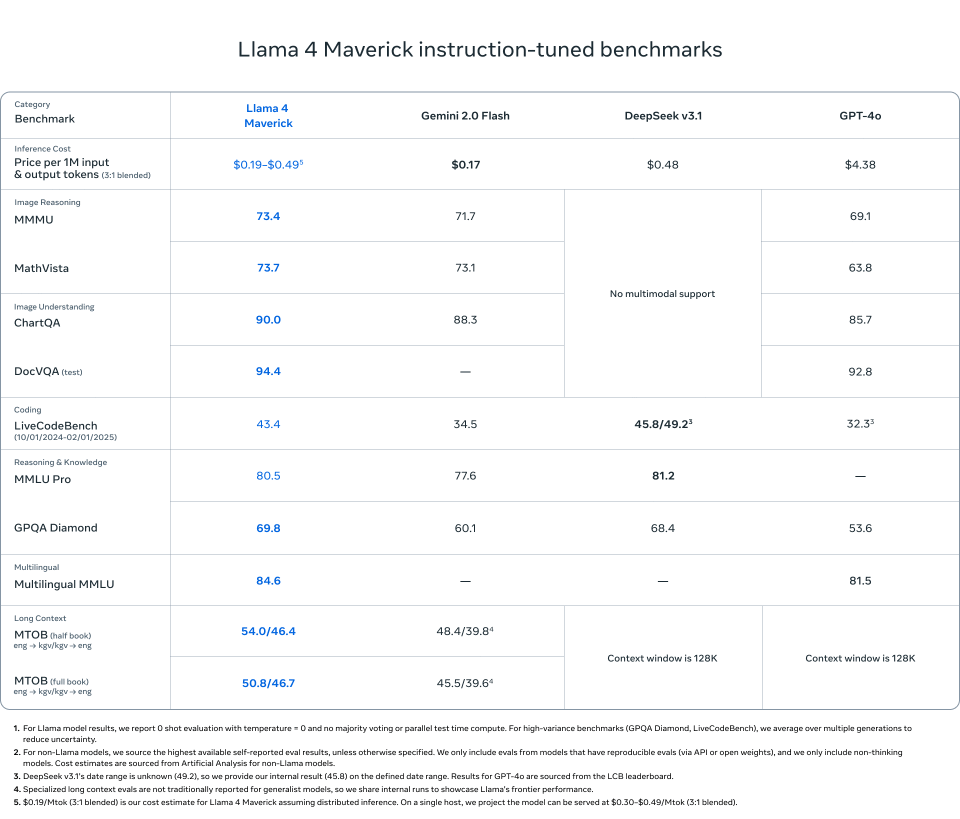
2.Llama 4 Maverick
在大多数多模态推理基准测试中超过了GPT-4o和Gemini 2.0 Flash:
ChartQA、DocVQA、MathVista、MMMU
与DeepSeek v3.1(458亿参数)相比,虽然使用的活跃参数不到一半(170亿参数),但仍具竞争力
基准分数:
ChartQA: 90.0(相比GPT-4o为85.7)
DocVQA: 94.4(相比DeepSeek v3.1为92.8)
MMLU Pro: 80.5
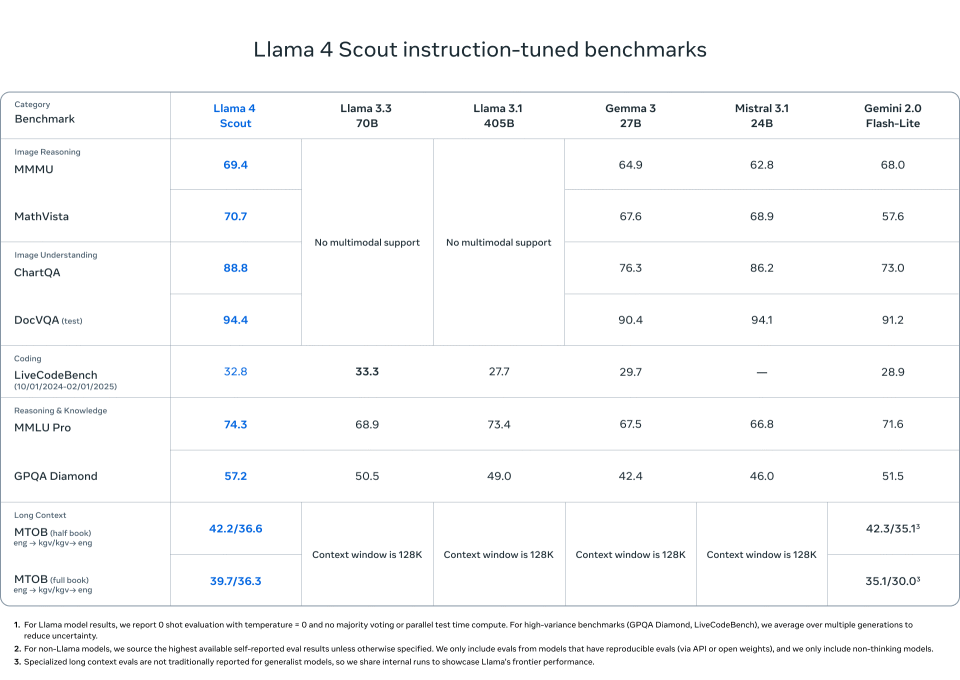
3.Llama 4 Scout
在以下任务上与Mistral 3.1、Gemini 2.0 Flash-Lite和Gemma 3相当或超越:
DocVQA: 94.4
MMLU Pro: 74.3
MathVista: 70.7
1000万token的上下文长度适用于长文档、代码库或多轮分析
更少政治“偏见”
Meta还通过引入Llama Guard、Prompt Guard和CyberSecEval等工具来强调模型对齐和安全性,帮助开发者检测不安全的输入/输出或对抗性提示,并实施生成性进攻代理测试(GOAT)以进行自动化红队测试。
该公司还声称Llama 4在“政治偏见”方面有了显著改善。它提到:“众所周知,所有领先的大语言模型中都存在偏见问题——具体来说,它们在有争议的政治和社会话题上,历史上倾向于偏左,而Llama 4在这方面更加平衡。”(腾讯科技特约编译金鹿)