万字长文:大语言模型复杂推理的自我进化机制

本文转载自“集智俱乐部”
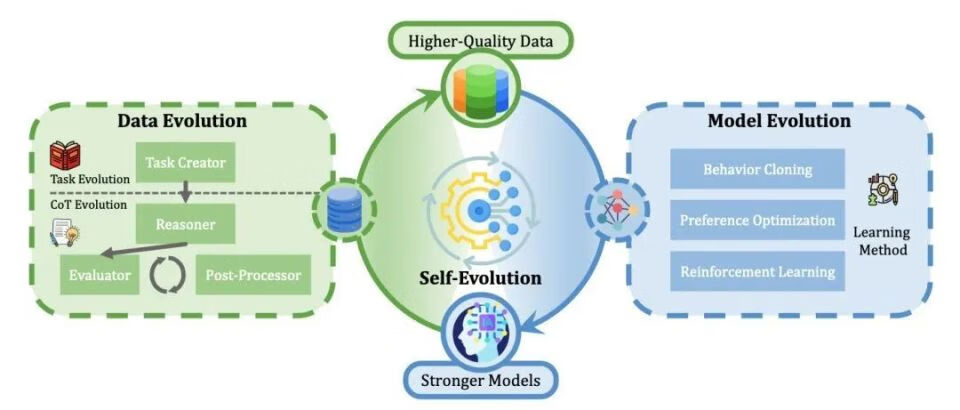
OpenAI的O1及其后续竞争者(如DeepSeek R1)的发布显著推动了大语言模型(Large Language Models,LLMs)在复杂推理方面的研究,引发学术界与工业界的双重关注。此项进展激发了相关技术成果的复现和在此基础上的创新。为系统构建该领域的研究框架,本文从自我进化(self-evolution)的角度系统地分类了现有技术。我们的调查发现分为三个相互关联的部分:数据进化(data evolution)、模型进化(model evolution)和自我进化(self-evolution)。
数据进化部分改进推理训练数据,这包括任务进化和增强思维链(Chain-of-Thought,CoT)推理的推理时间计算。 模型进化部分通过在训练过程中优化模型模块,以增强复杂推理能力。 自我进化部分则探讨其进化策略和模式。包括自我进化的规模法则(scaling law)与对 O1 类研究工作的分析。
摘要
数据进化部分改进推理训练数据,这包括任务进化和增强思维链(Chain-of-Thought,CoT)推理的推理时间计算。 模型进化部分通过在训练过程中优化模型模块,以增强复杂推理能力。 自我进化部分则探讨其进化策略和模式。包括自我进化的规模法则(scaling law)与对 O1 类研究工作的分析。
1.引言
在工业界,一系列类似的产品涌现,例如DeepSeek R1 [DeepSeek-AI et al.,2025](简称R1)、Kimi k1.5 [Team et al., 2025]和QwQ [Team, 2024b],它们都发布了自己的模型或技术报告。这些产品不仅达到甚至超越了O1,而且其开源贡献也值得称赞。此外,这些技术报告中强调的扩展强化学习(Scaling Reinforcement Learning)等技术,进一步拓展了研究类O1工作的方向。 在学术界,研究者从不同角度进行了多项复现研究。例如,O1 Journey [Qin等,2024; Huang等,2024] 广泛讨论了思维链格式化和蒸馏,但对持续优化方法的见解有限。与此同时,OpenR [Wang等,2024e]、O1-Coder [Zhang等,2024j]等工作主要通过强化学习的视角研究O1,但忽略了对反思和纠正推理操作的讨论。另一方面,Slow Thinking系列工作[Jiang等,2024a; Min等,2024]专注于推理时计算,尝试通过树搜索技术提升推理性能。此外,rStar-Math [Guan等,2025] 通过使用自我进化框架联合训练推理器和过程奖励模型(Process Reward Model, PRM),实现了接近O1的性能,突显了迭代优化在提升推理能力方面的潜力。
2. 预备知识
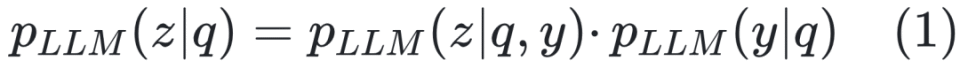
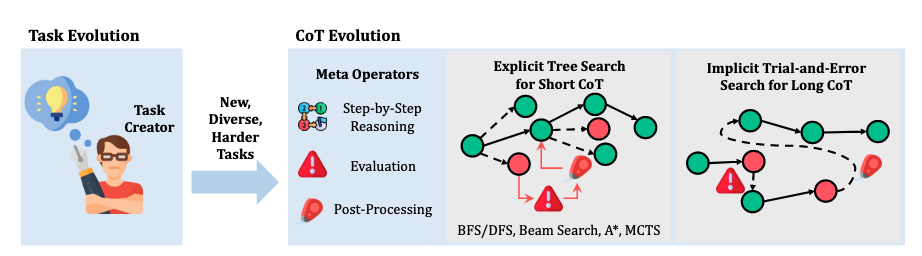
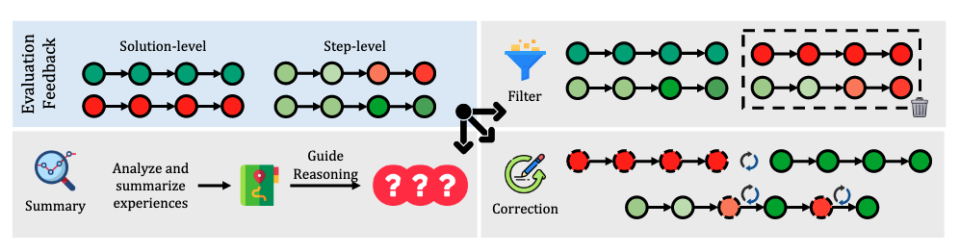
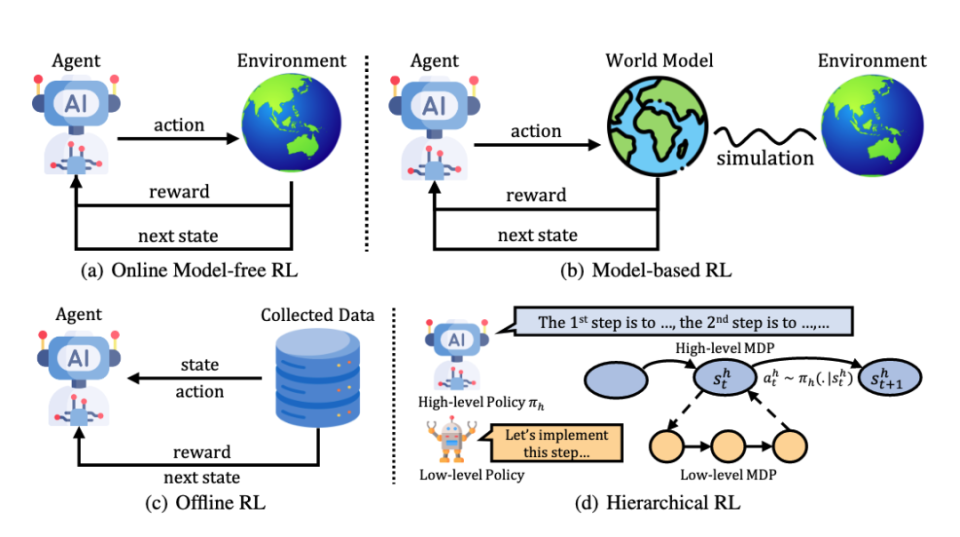
任务创建器(Task Creator):推理系统需要任务作为输入。任务创建器最直接的实现方式是从固定任务集中抽样。然而,与单轮推理改进不同,自我进化需要通过迭代优化持续提升推理能力。固定任务集可能导致性能快速收敛[Jiang等,2024a],因为系统学会识别针对特定任务的"捷径",从而降低模型泛化能力。因此,生成多样化任务对缓解这一问题并促进自我进化至关重要。 推理器(Reasoner):推理器是系统的核心角色,负责接收来自任务创建器的输入并通过逐步推理生成解决方案。在本研究中,推理器由大语言模型实现。 评估器(Evaluator):评估器负责评估和验证推理器生成的推理过程。这一辅助模块有几个关键功能:在训练阶段,它提供基于分数的反馈来微调推理器,例如拒绝微调或强化学习;在推理阶段,它评估推理过程,从而指导推理时计算和后处理步骤。 后处理器(Post-Processor):后处理器基于评估器反馈,处理推理器生成的解决方案。最简单的操作是直接过滤掉错误的解决方案;然而,这种方法可能导致数据浪费,且与人类处理错误的方式不尽相同。后处理分为两个阶段:在生成过程中,它可以通过修正错误的步骤或回溯来优化部分思维链;在生成后,它利用系统的纠正能力来完善完整的解决方案。
3. 数据进化
任务多样性 :为了增强任务多样性,Haluptzok等[2022]、Madaan等[2023a]使用大语言模型修改参考问题的数据类型和逻辑操作,生成结构相似但逻辑不同的任务。Yu等[2023b]则使用大语言模型重新表述参考问题来创建新问题。然而,此类方法受限于对参考数据的依赖,从而限制了全新任务的生成,并削弱了多样性和创造性。为突破这一局限,有人提出从高方差分布中采样数据或引入聚焦多样性的提示词。例如,Liu等[2023]采用温度采样和注重多样性的提示词来生成多样化的问题,而Xu等[2023]则明确指示大语言模型创建罕见的、特定领域的问题。此外,Self-Instruct[Wang等,2022]通过结合人工编写和模型生成的任务来生成新的任务指令,并使用特定的提示模板引导生成过程。 任务复杂性:Xu等[2023]提出了几种基于示例问题生成复杂任务的方法:1) 添加约束:通过引入额外的约束或要求来提高任务难度,从而增强模型的灵活性和适应性;2) 深化:扩展示例中查询的深度和广度,以提升模型的推理能力;3) 具体化:将问题中的一般概念替换为具体概念,使指令更加清晰,从而提高响应的准确性和相关性;4) 增加推理步骤:重新制定简单问题,要求额外的推理步骤,从而增强模型的逻辑思维能力;5) 增加输入复杂性:通过修改问题条件,引入结构化数据或特定输入格式(如代码、表格、XML等),将问题从直接可计算转变为需要额外数据解析或操作的形式,从而提升模型的鲁棒性和泛化能力。
任务可靠性:自动生成任务可能会产生无法解决的任务或不正确的答案。为解决这一问题,Li 等 [2023a] 采用微调的大语言模型(LLMs)对任务进行评分并筛选高质量任务。类似地,Liu 等 [2024a] 和 Xu 等 [2023] 基于原始问题生成多种任务,并通过验证答案来过滤不一致的任务。Haluptzok 等 [2022] 和 Liu 等 [2023] 则利用 Python 解释器和预定义规则(如检查任务长度或数值内容)来验证正确性,从而确保任务质量。Kreber 和 Hahn [2021] 提出了一种基于 Transformer 编码器的生成对抗网络(GAN)[Goodfellow 等,2014],通过随机噪声生成符号任务。评判器评估生成任务与真实数据之间的相似性,并提供反馈以优化生成器,从而提高任务可靠性。此外,Wei 等 [2023] 和 Lu 等 [2024b] 探索了反向任务生成方法,利用大语言模型从解决方案中推导问题。具体而言,Lu 等 [2024b] 从数学参考解决方案中迭代生成新答案,定义约束条件和逻辑关系,并将这些答案转化为任务,从而确保生成问题的可靠性。类似地,Wei 等 [2023] 利用高质量的开源代码,通过大语言模型生成编程任务。
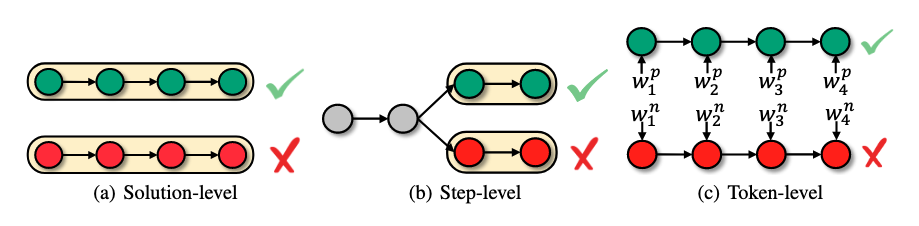
结果级评估 早期工作主要关注结果级评估,即在推理完成后对完整解决方案进行评估 [Cobbe 等,2021; Wang 等,2023c; Lee 等,2024a]。这些方法的主要区别在于评估的形式和目的。在训练阶段,当正确答案可用时,一些工作对照标准答案对解决方案进行直接的正确性评估 [Cobbe 等,2021; Hosseini 等,2024]。除了单纯的答案准确性外,R1 [DeepSeek-AI 等,2025] 和 T1 [Hou 等,2025] 还融入了基于格式的结果奖励来指导推理格式学习。在推理阶段,Cobbe 等 [2021]、Hosseini 等 [2024] 利用训练好的验证器对候选解决方案进行评分和排名,从而选择最优解。此外,一些方法使用大语言模型对解决方案提供自然语言反馈。例如,Madaan 等 [2023b]、Zhang 等 [2024b] 直接生成批评,而 Peng 等 [2023]、Shinn 等 [2023]、Gou 等 [2024] 在批评生成中包含内部和外部环境信息。此外,Ankner 等 [2024b]、Yu 等 [2024b] 将自然语言批评与评分机制相结合,以提高评估的可靠性和可解释性。一些研究还采用基于一致性的评估框架。例如,Wang 等 [2023c] 采用投票系统从多个解决方案候选中确定最终答案,而 Jiang 等 [2024b]、Weng 等 [2023] 通过确保前向和后向推理过程之间的一致性来评估答案质量。 步骤级评估 虽然结果级评估实施简单,但在实践中应用有限,往往需要更细致的评估。其中,步骤级评估已成为一种特别突出的方法,强调对单个推理步骤的评估 [Lightman 等,2024; Wang 等,2024g,m; Gao 等,2024a; Lu 等,2024a; Li 等,2023b]。在树搜索算法中,过程评估被广泛用于指导搜索轨迹。例如,Tian 等 [2024] 在蒙特卡洛树搜索(MCTS)中使用状态评分来指导搜索过程,而 Xie 等 [2023] 在束搜索中实现状态评分以优化路径选择。此外,步骤级评估在错误纠正和推理步骤总结方面都证明了其有效性。值得注意的是,Zheng 等 [2024]、Xi 等 [2024] 已开发出能够精确定位特定推理步骤中的不准确之处的方法,从而提供更精确和可操作的反馈,用于全面评估。 词元级评估 一些研究认为,步骤级评估的粒度对于全面的推理评估仍然不足 [Yoon 等,2024; Chen 等,2024h]。这促使了词元级评估框架的发展,提供了更高细粒度的分析。Yoon 等 [2024] 引入了一种方法,利用强大的大语言模型在词元级别上迭代修改思维链推理。他们的方法根据修改操作为词元分配不同的奖励,并利用这些奖励来训练词元级奖励模型。类似地,Chen 等 [2024h] 提出了一个两阶段框架,首先训练一个纠正模型来识别和纠正错误的推理步骤。通过将低生成概率与错误词元关联,将高概率与正确词元关联,他们的方法能够构建精确的词元级奖励信号。此外,Lee 等 [2024d] 提出了一个词元监督的价值模型,该模型监督单个词元以提供对解决方案正确性的更准确评估。同时,Yang 等 [2024b] 基于最大熵强化学习原理推导出了一种词元级评估方案。他们的方法通过基于排名的截断计算词元级价值,为每个词元分配 +1、0 或 -1 的离散奖励,从而实现对推理过程的细粒度优化。
验证器 验证器范式通过分配量化分数来评估解决方案的正确性。例如,Cobbe 等[2021]使用验证器来估计解决方案正确的概率,而Hosseini 等[2024]利用经过训练的DPO验证器生成反映解决方案有效性的似然分数。此外,[Lightman 等,2024; Wang 等,2024g; Lu 等,2024a]采用步骤级评分机制,对单个推理步骤分配分数,并使用最小值或平均值等指标聚合它们,以得出整体解决方案质量评估。[Tian 等,2024; Xie 等,2023]为树搜索过程中的每个状态分配分数,以优化搜索路径。为了更细的粒度,[Yoon 等,2024; Chen 等,2024h; Lee 等,2024d; Yang 等,2024b]引入了词元级评分机制,为单个词元分配连续或离散分数(如中性、正确或错误)。 评论器 评论器范式生成自然语言反馈,以促进错误澄清并提高评分机制的可解释性。例如,Madaan 等[2023b]利用模型固有的能力对其自身解决方案产生批判性反馈,实现迭代改进。同时,[Peng 等,2023; Shinn 等,2023; Gou 等,2024]通过结合内部模型状态和外部环境信息来扩展这种方法,生成全面的批评,不仅识别错误,还指导后续改进。进一步推进这一工作,[Zheng 等,2024; Xi 等,2024]进行粒度化、逐步的批判性分析,以更详细地定位和纠正错误。[Ankner 等,2024b; Yu 等,2024b]将批评生成与评分机制整合。通过在分配分数之前生成自然语言批评,这些方法增强了评估过程的透明度和可靠性,为评估解决方案质量提供了更可解释和稳健的框架。此外,MCTS-Judge Wang 等[2025b]也将自我评估建模为一系列子任务,并使用蒙特卡洛树搜索将问题分解为更简单的多角度评估任务。
词元级束搜索在模型生成的最小单位上操作,直接与大语言模型解码过程对齐。虽然传统束搜索基于词元对数概率对序列进行排序,但这种方法优先考虑自然语言流畅性而非推理质量。为解决这一局限性,Lee 等[2024c]引入了词元监督价值模型,对词元进行评分以提高数学推理的准确性。此外,为缓解生成序列多样性不足的问题,Vijayakumar 等[2016]提出多样化束搜索,将束分成多个组,在每个组内独立优化,并在组间引入多样性惩罚,以鼓励生成更多样的推理路径。 步骤级束搜索将多步推理分解为子步骤,对每个子步骤进行评分和验证,以维持高质量的候选路径。例如,Wang 等[2024i]、Ma 等[2023]使用过程奖励模型(PRM)对子步骤进行打分,利用这些分数引导搜索朝有希望的推理路径发展。类似地,Chen 等[2024b]、Yu 等[2023a]利用学习的价值模型在步骤级别增强搜索效率,避免了蒙特卡洛树搜索的计算开销。Setlur 等[2024]进一步结合过程优势来完善搜索过程。与外部评估方法不同,Xie 等[2023]利用模型本身进行自我验证,提示它验证步骤正确性,同时通过温度调整的随机化引入多样性。 解决方案级束搜索独立评估整个推理路径,通过避免中间操作提供更快的推理。例如,Best-of-N(BoN)采样生成多个完整解决方案,并使用奖励模型选择评分最高的解。然而,Wang 等[2024i]强调了奖励模型在区分相似推理过程方面的局限性,提出了一种成对偏好模型以实现更有效的排名。同时,Wang 和 Zhou [2024]观察到模型可以通过采样自动生成思维链推理,而基于思维链得出的答案表现出更高的置信度。利用这一见解,他们引入了思维链解码(CoT-decoding),这是一种通过改变解码过程隐式执行思维链推理的方法,通过top-k采样生成多个序列,并基于答案置信度选择最佳序列。
选择(Selection) 从根节点开始,MCTS 在探索与利用之间进行权衡,并据此计算各子节点的权重。常见的权重计算策略包括上置信界(Upper Confidence Bound, UCB)和预测器上置信树界(Predictor Upper Confidence Tree Bound, PUCT)[Rosin, 2011]。 UCB 公式为: ![]() ;PUCT公式为:
;PUCT公式为:![]() 。其中Q(s,a)表示从状态 s 采取行动 a 后的累积奖励,πprior(a|s) 为在状态 s 下选择行动 a 的先验概率, N(s) 是当前上下文中状态 s 被探索的次数, N(s,a) 是行动 a 在状态 s 被探索的次数。权重函数同时考虑探索(未访问节点将获得更高探索值)与利用(历史上高回报节点获得更高利用值)。每轮选择会推进到得分最高的子节点,直至到达叶节点。
。其中Q(s,a)表示从状态 s 采取行动 a 后的累积奖励,πprior(a|s) 为在状态 s 下选择行动 a 的先验概率, N(s) 是当前上下文中状态 s 被探索的次数, N(s,a) 是行动 a 在状态 s 被探索的次数。权重函数同时考虑探索(未访问节点将获得更高探索值)与利用(历史上高回报节点获得更高利用值)。每轮选择会推进到得分最高的子节点,直至到达叶节点。扩展 (Expansion) 一旦到达叶节点,若该节点不是终止状态(例如尚未得出最终答案),MCTS 将基于当前状态执行新的行动,扩展生成多个子节点。扩展质量主要取决于行动空间的定义。在围棋中,行动为落子;而在大语言模型推理中,不同任务需定义不同的行动空间。即使在同一任务下,不同粒度的行动空间也可能导致完全不同的搜索行为和结果。 评估(Evaluation) 到达叶节点后,需对其状态值进行评估。常见方法包括: 1)蒙特卡洛采样估值:将从根到当前节点的状态-行动路径作为上下文,采样多个完整轨迹,并基于其统计指标(如成功率)计算状态值。该方法无偏但方差高、计算成本大,难以用于采样代价高的任务; 2)训练价值模型估值:利用预训练模型直接估计状态值,但训练价值模型比奖励模型更具挑战,因为它需预测未来的预期累积奖励。 反向传播(Backpropagation) 一旦完成状态值评估,MCTS 将从叶节点向根节点回传该值,更新路径中所有节点的状态估计。随着模拟次数的增加,这些估值愈发精确。该过程重复执行,直到达到设定的最大模拟次数,最终形成一棵记录每个节点状态值与访问次数的搜索树。由于不同任务和方法的设计差异,MCTS 在大语言模型推理中的实现方式也有所不同。


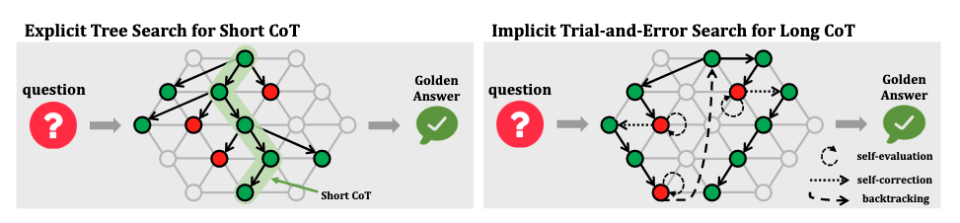
如图5所示,显式树搜索采用启发式搜索算法(如蒙特卡洛树搜索、A*和束搜索)来探索解决方案空间。在每个状态,都会扩展多个行动以获得候选状态,形成树结构的搜索过程。在此过程中,推理系统被动调用评估和剪枝等操作。生成的思维链中的每个推理步骤都保证是正确的,而评估、剪枝和错误纠正等行为不会在短思维链(Short CoT)中呈现。 相比之下,隐式试错搜索不依赖启发式算法。相反,大语言模型在推理过程中主动调用自我评估和自我纠正等能力,并用自然语言表达这些操作。因此,试错搜索中的长思维链不仅包含逐步推理,还融合自我评估、自我纠正与回溯操作,使整体推理过程更加透明且具有动态调整能力。
首先,树搜索通常依赖奖励模型或价值模型等验证器提供评分,以实现细粒度的评估指导。然而,这些验证器普遍存在泛化能力弱与奖励欺骗严重的问题。这可能导致中间评估不准确,甚至因 LLM 利用捷径最大化奖励而引发训练崩溃。相比之下,R1、Kimi k1.5和T1在搜索过程中利用自我评估能力,并在训练过程中采用基于规则的结果奖励,显著减轻了奖励欺骗并提高了泛化能力。 此外,树搜索中验证器的分数仅反映推理的相对质量,未能指出错误或原因,导致评估质量有限。相比之下,R1和类似项目通过自我评估生成口头评估反馈,提供更丰富和更有信息的反馈。 最后,虽然树搜索可以同时探索多条路径,但这些路径是独立的。因此,中间经验无法在它们之间共享,降低了并行推理过程的利用率。这使得树搜索与人类推理有显著差异,因为在人类推理中,过去错误的见解指导后续推理,这在长思维链(Long CoT)的试错搜索中可以看到。
在试错搜索中应用长思维链可能在两个关键方面引入效率低下。1) 对于简单任务,长思维链方法往往表现出过度思考。正如[Chen 等,2024f]所指出的,QwQ [Team, 2024b]和R1 [DeepSeek-AI 等,2025]等方法通常会探索多个潜在解决方案,即使初始解决方案通常已经足够。这种过度探索行为会引入显著的计算资源消耗。2) 对于复杂任务,Wang 等[2025a]观察到QwQ和R1容易思考不足。这些方法往往在未充分验证当前推理路径有效性前即过早放弃,导致策略频繁切换,导致搜索过程不稳定且效率低下,伴随着不必要的冗长推理链。相比之下,基于短思维链的方法产生更简洁的推理路径,提供明显的效率优势。[Wu 等,2025b; Xie 等,2025a]进一步论证,更长的思维链不一定能改善推理性能;相反,每个模型和任务都存在最佳思维链长度。因此,试错搜索的低效率不仅增加了词元使用和计算成本,还降低了性能。 此外,隐式试错搜索严重依赖大语言模型的自我评估和自我纠正能力。一方面,这些能力的背景机制仍是需要进一步研究的领域;另一方面,这些能力在大语言模型的学习过程中尚未被特别优化。R1 [DeepSeek-AI 等,2025]、kimi k1.5 [Team 等,2025]和T1 [Hou 等,2025]等模型在同一行动空间中仅使用结果级奖励同时学习推理、评估、反思和错误纠正,但缺乏专门的奖励信号来指导评估、反思和纠正能力的学习。结果,大语言模型中的这些能力没有得到特别优化,一个后果是,即使大语言模型在早期阶段进行低质量的反思或错误纠正,只要最终答案正确,它们仍然可以获得积极奖励。此外,自我评估能力的不足是R1等方法经常无法准确评估推理路径,从而过早放弃有希望路径的原因之一。
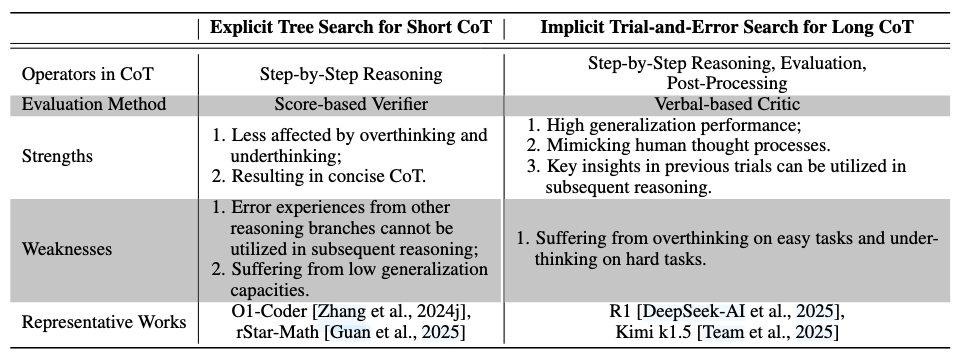
最初,两种策略都包括逐步推理,短思维链主要由逻辑连贯的推理步骤组成。 然而,两种策略在评估机制上有显著差异。显式树搜索通常需要学习过程奖励模型或价值模型来评估推理质量,由于这些模型泛化能力差而引入高偏差。相比之下,试错搜索依靠大语言模型的内在自我评估能力来评估推理状态。 关于后处理,我们以"纠正"为例进行分析。树搜索通常缺乏直接纠正操作,尽管分支间切换可被视为一种形式上的错误纠正。然而,这种"纠正"无法利用先前尝试的内容,因为它们仅是在先前扩展阶段预先采样的,不同尝试彼此独立。例如,在蒙特卡洛树搜索的扩展阶段,同时采样多个子候选行动。在随后的选择阶段,当前状态中选择的行动可能与前一模拟中的不同,这可视为一种"纠正"。然而,此次模拟中选择的新行动并非基于前一模拟中所选行动的评估反馈生成;相反,两种行动都是在扩展阶段独立采样的。
4. 模型进化
奖励建模(Rewarding):收集偏好数据训练奖励模型 rθ。早期方法通过人工标注同一提示下的多个响应,并按质量排序以表示人类偏好关系 。
训练目标如下: ![]()
策略优化(Policy Optimization):将大语言模型微调为策略模型 πref ,目标是最大化其所获奖励。过程包括生成内容、通过奖励模型评分,并使用 PPO [Schulman 等,2017] 进行优化: ![]()
其中参考模型πref通常经监督微调(SFT)后冻结参数。KL散度项 ![]() 用于限制偏离并保持多样性,防止策略塌缩。
用于限制偏离并保持多样性,防止策略塌缩。



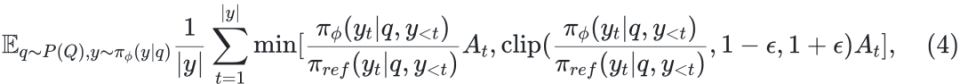
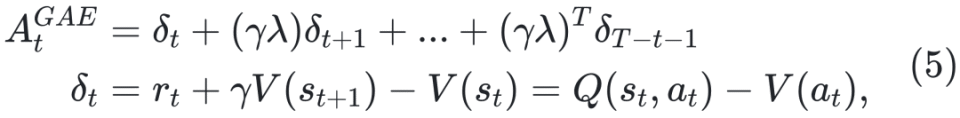
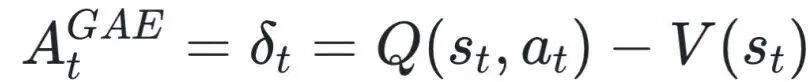 。
。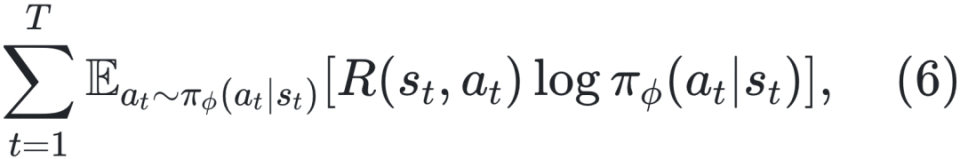
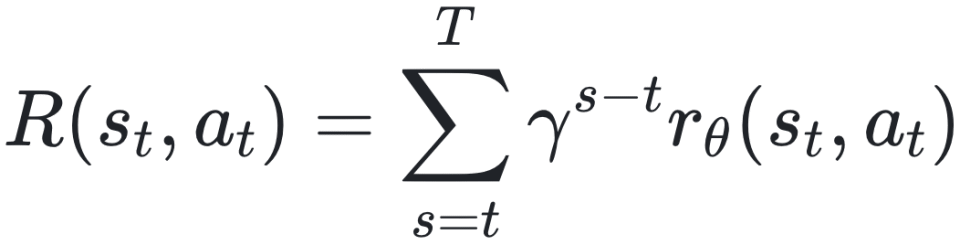 为累积奖励,用于控制策略梯度更新的方向与步长。
为累积奖励,用于控制策略梯度更新的方向与步长。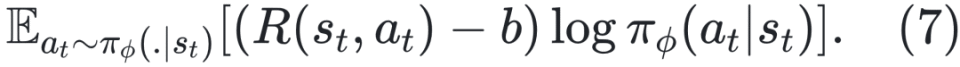
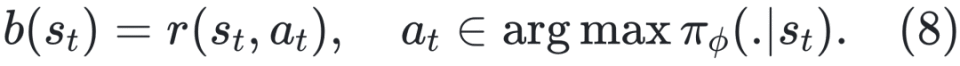
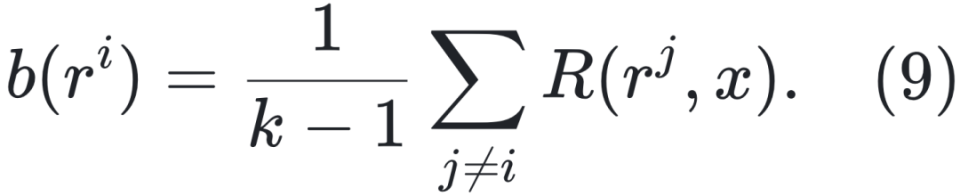

使用 PRM 时,为每步分配奖励,构造奖励集: ![]()

其中 ki 表示 yi 中的步骤数, 表示 yi 的第 j 步中结束词元的索引。此时,优势函数计算如下:
![]()
使用 ORM 时,为每个解分配一个奖励 ri,优势函数简化为: ![]()


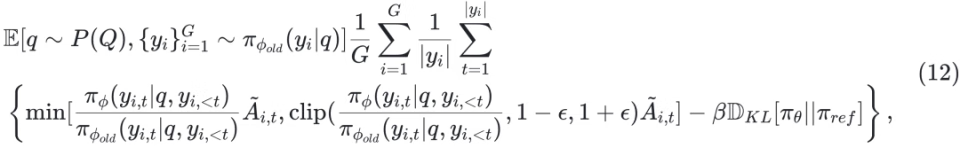
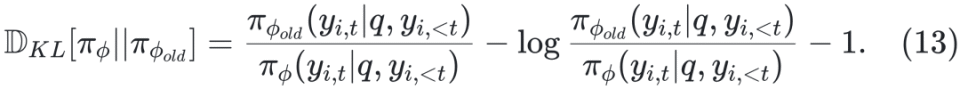
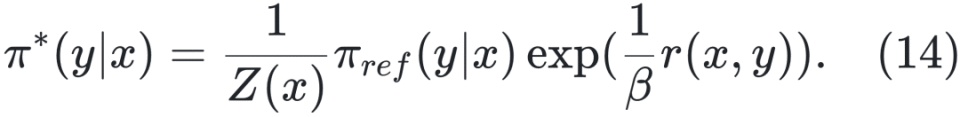
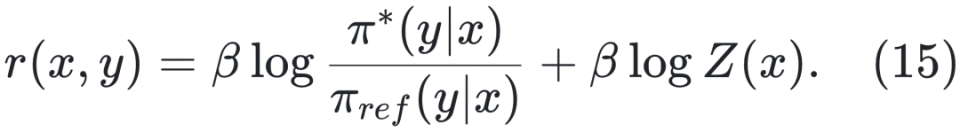
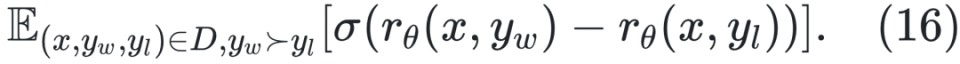
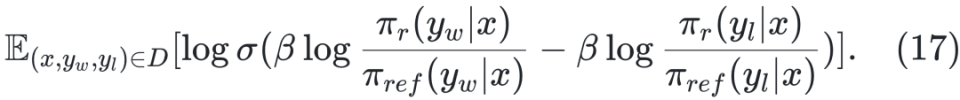
优化粒度粗糙 原始 DPO 只在响应级别优化偏好,难以精细区分复杂推理中的正确与错误步骤,容易将部分正确的响应也标记为负例。为此,后续提出了 step-DPO、token-DPO 等细粒度方法(详见 §4.2.2)。 数据分布偏移 DPO 通常在离线场景训练,先使用参考模型 πref 收集一批固定的偏好数据集,再用 DPO 训练策略模型 πΦ 。该方法虽具有较高的训练效率,但完全依赖静态离线数据可能限制模型的持续学习能力 [Chen 等,2024a]。为缓解此问题,有研究将 DPO 拓展到在线学习框架。具体做法是:每轮先收集一批偏好数据,使用 DPO 训练策略模型,然后将新训练得到的模型 πΦ 替换为下一轮数据收集的参考模型 πref,实现策略的持续迭代优化。 正样本被抑制 DPO 在训练中不仅会降低负样本概率,也可能误伤正样本,尤其当正负差异不显著时。为解决该问题,研究者引入正则化项以强化对正负样本质量差异的建模 [Azar 等,2023;Le 等,2024]。 奖励信号利用不足 DPO 未对偏好程度进行显式建模,在奖励数值可用的情况下,仅通过比较奖励高低构造偏好对,而未直接利用奖励信号本身,导致信息利用不足。同时,对偏好对数据的依赖也提高了训练数据的构造成本。为解决这一问题,OREO [Wang 等,2024b] 提出一种全新的离线强化学习算法,仅依赖奖励信号进行优化,完全无需偏好对数据。
fDPO:引入散度约束,增强偏好表达能力与鲁棒性 [Wang 等,2023a] cDPO:提升在噪声反馈环境下的稳定性 [Chowdhury 等,2024] KTO:基于 Kahneman-Tversky 心理模型结合人类决策偏好 [Ethayarajh 等,2024] GPO:用凸函数族参数化损失函数,统一偏好学习框架 [Tang 等,2024] ORPO:去除参考模型,仅使用偏好信息优化策略,进一步简化流程 [Hong 等,2024]
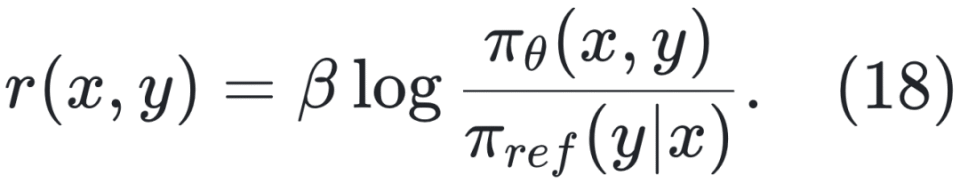
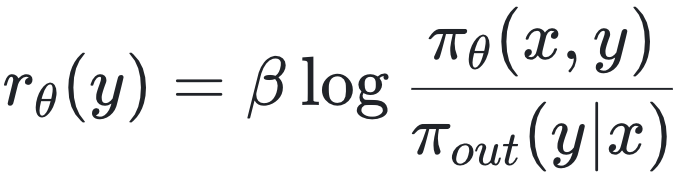 ,则所得的 ORM 可直接用于计算词元级奖励。换句话说,按此格式训练出的 ORM 本质上也可作为过程奖励模型(PRM)使用。具体而言,PRIME [Cui 等,2025] 包含四个核心组件:策略模型 πΦ、结果奖励验证器 πΦ、过程奖励模型 πΦ 及其对应的参考模型 πref。在生成响应 y 后,PRIME首先获取结果级奖励 ro(y) ,并通过交叉熵损失训练 rθ(y):
,则所得的 ORM 可直接用于计算词元级奖励。换句话说,按此格式训练出的 ORM 本质上也可作为过程奖励模型(PRM)使用。具体而言,PRIME [Cui 等,2025] 包含四个核心组件:策略模型 πΦ、结果奖励验证器 πΦ、过程奖励模型 πΦ 及其对应的参考模型 πref。在生成响应 y 后,PRIME首先获取结果级奖励 ro(y) ,并通过交叉熵损失训练 rθ(y):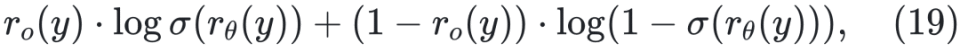
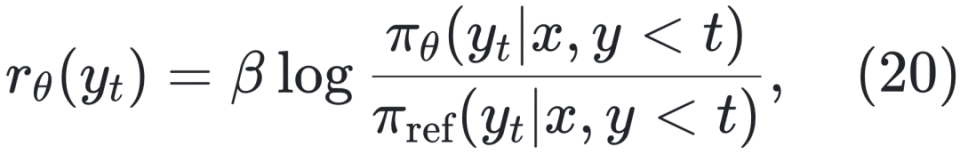
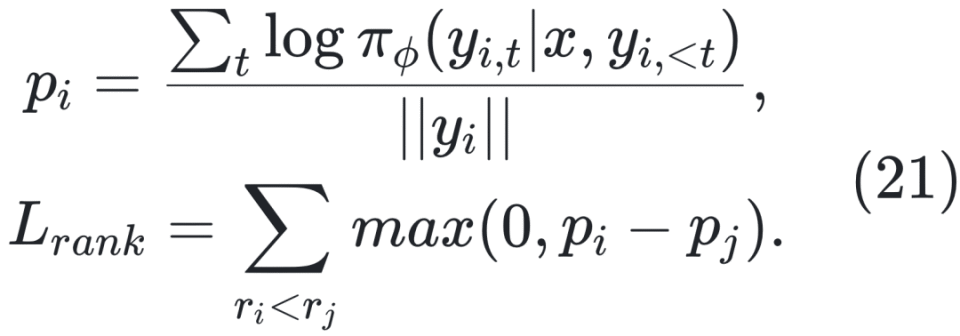
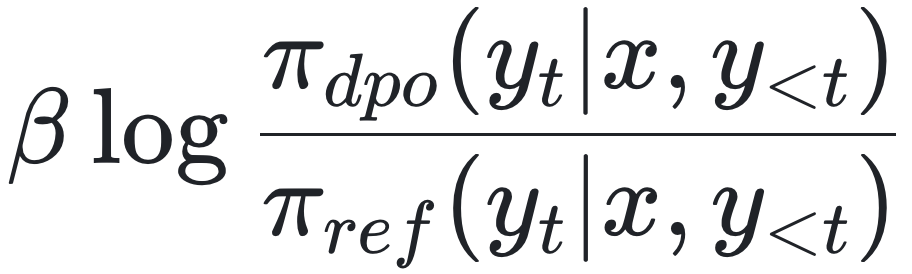
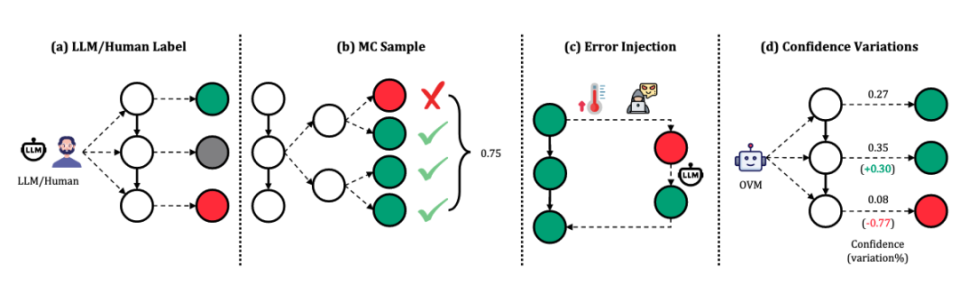
第一类:估计步骤正确性。 Wang 等[2024g,m]和 Jiao 等[2024]通过蒙特卡洛采样估算步骤奖励,以步骤Si的N次完成的成功率为其奖励。Luo 等[2024]结合二分查找和MCTS识别首个错误步骤,提高采样效率。Zhang 等[2024f]、Xia 等[2024]和 Gao 等[2024a]则直接采用LLM评估步骤正确性。Zhang 等[2025b]指出MC采样存在较大噪声,提出共识过滤机制,将MC估计与LLM验证结合,以提升数据准确性。与此不同,Chen 等[2024g]将问题分解为子问题,并从标准解中提取中间结果,将其与模型生成结果比对评估步骤正确性。 第二类:基于标签生成步骤内容。 此类方法主动向正确推理过程注入错误,以构建包含错误步骤的数据集。Yan 等[2024]通过高温采样生成错误,并基于正确解生成反思与修正。Xi 等[2024]则主动插入错误并引导模型生成反思,构造高质量的修正数据。 第三类:通过置信度变化评估步骤质量。该类方法基于以下假设:优质推理步骤提升推理置信度,劣质步骤则降低之。Lu 等[2024a]提出利用结果监督验证器评估相邻步骤之间置信度变化,以此标注步骤正确性,同时避免大规模采样以降低计算开销。
的对比,为每个词元标注奖励。Rafailov 等[2024]、Zhong 等[2024]从DPO框架导出隐式奖励,形式为:
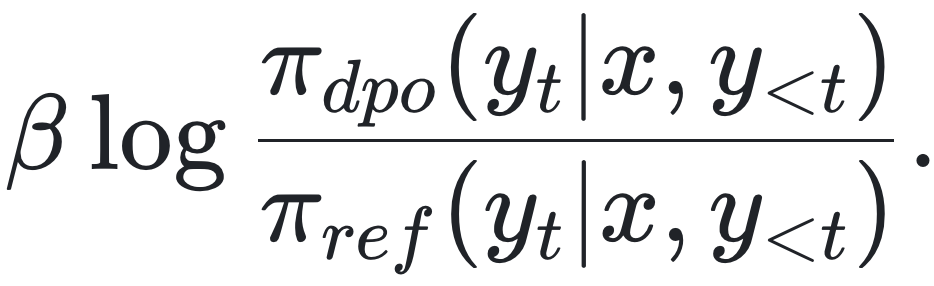
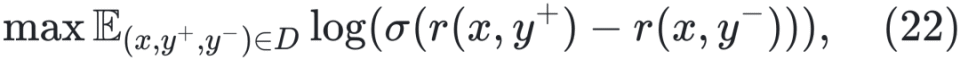
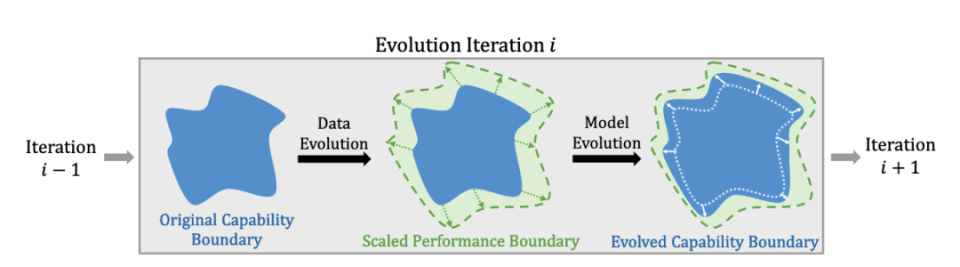
5. 自我进化
[研究问题 1] 推理的自我进化是否遵循规模法则? [研究问题 2] 哪些关键因素促使自我进化实现持续性能提升?
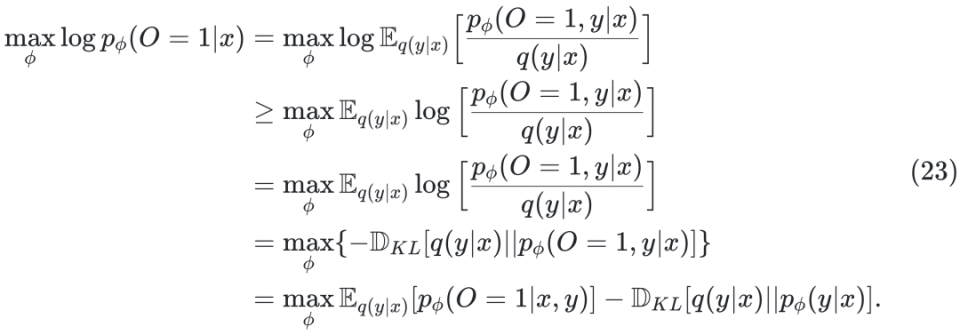
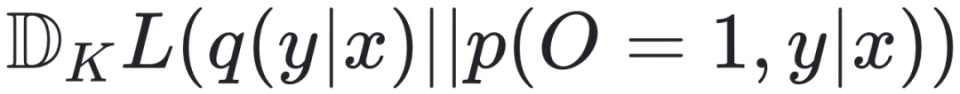 来最大化目标,最终得到:
来最大化目标,最终得到: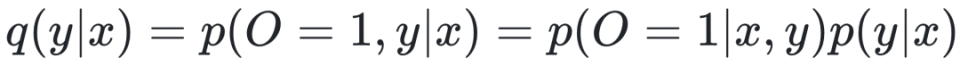
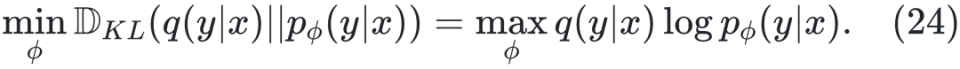
6. 基于自我进化框架解读 O1 类研究
7. 未来挑战和方向
如何进一步增强任务多样性?艰难任务是提升系统泛化能力的有效途径之一。例如,Min 等 [2024] 指出,由于任务池稀疏,模型在仅经历少量迭代训练后便趋于收敛。为维持持续的自我进化,亟需提升任务的多样性与复杂性。尽管 R1 等方法有效增强了逐步推理、自我评估与自我纠正等能力,但尚未纳入任务进化机制。若能引入有效的任务进化,有望实现更显著且持久的性能提升。目前,相关方法仍较为初级,亟待进一步研究以构建更加多样化、复杂且具挑战性的任务集。 如何开发更细致的奖励建模?R1 等工作表明,仅使用结果奖励模型(ORM)即可实现令人满意的推理能力,而其在蒙特卡洛树搜索+过程奖励模型(PRM)方面的失败尝试加剧了对 PRM 实用性的质疑。与可学习的 PRM 相比,R1 采用的基于规则的 ORM 在泛化和缓解奖励欺骗方面具备优势。然而,这种 ORM 在优化过程中无法提供细粒度的奖励。分析表明,R1 等模型倾向于在简单问题上过度思考,而在复杂问题上思考不足 [Chen 等,2024f; Wang 等,2025a],这可能激励 PRM 的研究,因为 PRM 可以提供过程信号以指导高效的逐步推理。然而,PRM 的弱泛化能力、持续更新和奖励欺骗等挑战仍是其进一步发展的重大障碍。R1 通过自我评估实现 PRM,并使用 ORM 同时优化逐步推理、自我评估和自我纠正能力,但并未特别优化自我评估。自我评估的持续有效增强仍需进一步研究。 如何平衡效率与有效性以确定最佳思维链进化?短思维链的显式树搜索具备较高效率,但缺乏长思维链的泛化能力。尽管试错搜索模仿了人类推理,但其存在过度思考和思考不足等缺陷。因此需要思考如何在推理时计算阶段结合两种搜索类型的优势。一种可能的解决方案是增强大语言模型的自我评估和自我纠正能力,以缓解过度思考和思考不足。另一个潜在方向是在推理过程中将显式树搜索原则与试错相结合,从而提升 R1 中序列推理的性能。
8. 结论

· Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–12267, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.662. URL https://aclanthology. org/2024.acl-long.662/.
` Renat Aksitov, Sobhan Miryoosefi, Zong xiao Li, Daliang Li, Sheila Babayan, Kavya Kopparapu, Zachary Fisher, Ruiqi Guo, Sushant Prakash, Pranesh Srinivasan, Manzil Zaheer, Felix X. Yu, and Sanjiv Kumar. Rest meets react: Self-improvement for multi-step reasoning llm agent. ArXiv, abs/2312.10003, 2023. URL https://arxiv.org/pdf/2312.10003.
` Afra Feyza Akyürek, Ekin Akyürek, Aman Madaan, A. Kalyan, Peter Clark, Derry Tanti Wijaya, and Niket Tandon. Rl4f: Generating natural language feedback with reinforcement learning for repairing model outputs. In Annual Meeting of the Association for Computational Linguistics, 2023. URL https://aclanthology.org/2023.acl-long.427.pdf.
` Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. Learning from mistakes makes LLM better reasoner. CoRR, abs/2310.20689, 2023. doi: 10.48550/ARXIV. 2310.20689. URL https://doi.org/10.48550/arXiv.2310.20689.
` Marcin Andrychowicz, Dwight Crow, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Joshua Tobin, P. Abbeel, and Wojciech Zaremba. Hindsight experience replay. In Neural Information Processing Systems, 2017. URL https://arxiv.org/pdf/1707.01495.
` Zachary Ankner, Cody Blakeney, Kartik K. Sreenivasan, Max Marion, Matthew L. Leavitt, and Mansheej Paul. Perplexed by perplexity: Perplexity-based data pruning with small reference models. ArXiv, abs/2405.20541, 2024a. URL https://arxiv.org/pdf/2405.20541.
` Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D. Chang, and Prithviraj Ammanabrolu. Critique-out-loud reward models. CoRR, abs/2408.11791, 2024b. doi: 10.48550/ARXIV.2408. 11791. URL https://doi.org/10.48550/arXiv.2408.11791.
` Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences. ArXiv, abs/2310.12036, 2023. URL https://arxiv.org/pdf/2310.12036.
` Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39:324, 1952. URL https://api.semanticscholar.org/ CorpusID:125209808.
` Cameron Browne, Edward Jack Powley, Daniel Whitehouse, Simon M. M. Lucas, Peter I. Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez Liebana, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in Games, 4:1–43, 2012. URL https://ieeexplore.ieee.org/document/ 6145622.
` Changyu Chen, Zi-Yan Liu, Chao Du, Tianyu Pang, Qian Liu, Arunesh Sinha, Pradeep Varakantham, and Min Lin. Bootstrapping language models with dpo implicit rewards. ArXiv, abs/2406.09760, 2024a. URL https://arxiv.org/pdf/2406.09760. Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Alphamath almost zero: process supervision without process. ArXiv, abs/2405.03553, 2024b. URL https://arxiv.org/pdf/2405.03553.
` Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Step-level value preference optimization for mathematical reasoning. In Conference on Empirical Methods in Natural Language Processing, 2024c. URL https://arxiv.org/pdf/2406.10858.
` Huayu Chen, Guande He, Lifan Yuan, Hang Su, and Jun Zhu. Noise contrastive alignment of language models with explicit rewards. ArXiv, abs/2402.05369, 2024d. URL https://arxiv. org/pdf/2402.05369.
` Justin Chih-Yao Chen, Zifeng Wang, Hamid Palangi, Rujun Han, Sayna Ebrahimi, Long T. Le, Vincent Perot, Swaroop Mishra, Mohit Bansal, Chen-Yu Lee, and Tomas Pfister. Reverse thinking makes llms stronger reasoners. ArXiv, abs/2411.19865, 2024e. URL https://arxiv.org/pdf/ 2411.19865.
` Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Trans. Mach. Learn. Res., 2023, 2022. URL https://arxiv.org/pdf/2211.12588.
` Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do not think that much for 2+3=? on the overthinking of o1-like llms. ArXiv, abs/2412.21187, 2024f. URL https://arxiv.org/pdf/2412.21187.
` Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language model generation. CoRR, abs/2311.17311, 2023a. doi: 10.48550/ARXIV.2311.17311. URL https://doi.org/10.48550/arXiv.2311.17311.
` Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug. ArXiv, abs/2304.05128, 2023b. URL https://doi.org/10.48550/arXiv.2304. 05128.
` Zhaorun Chen, Zhaorun Chen, Zhuokai Zhao, Zhihong Zhu, Ruiqi Zhang, Xiang Li, Bhiksha Raj, and Huaxiu Yao. Autoprm: Automating procedural supervision for multi-step reasoning via controllable question decomposition. ArXiv, abs/2402.11452, 2024g. URL https://aclanthology.org/ 2024.naacl-long.73/.
` Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, and Ji-Rong Wen. Improving large language models via fine-grained reinforcement learning with minimum editing constraint. In Annual Meeting of the Association for Computational Linguistics, 2024h. URL https://arxiv.org/pdf/2401.06081.
` Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. ArXiv, abs/2401.01335, 2024i. URL https://arxiv.org/pdf/2401.01335.
` Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, and Nan Du. Selfplaying adversarial language game enhances llm reasoning. ArXiv, abs/2404.10642, 2024. URL https://arxiv.org/pdf/2404.10642.