混元与AI生图的“零延迟”时代

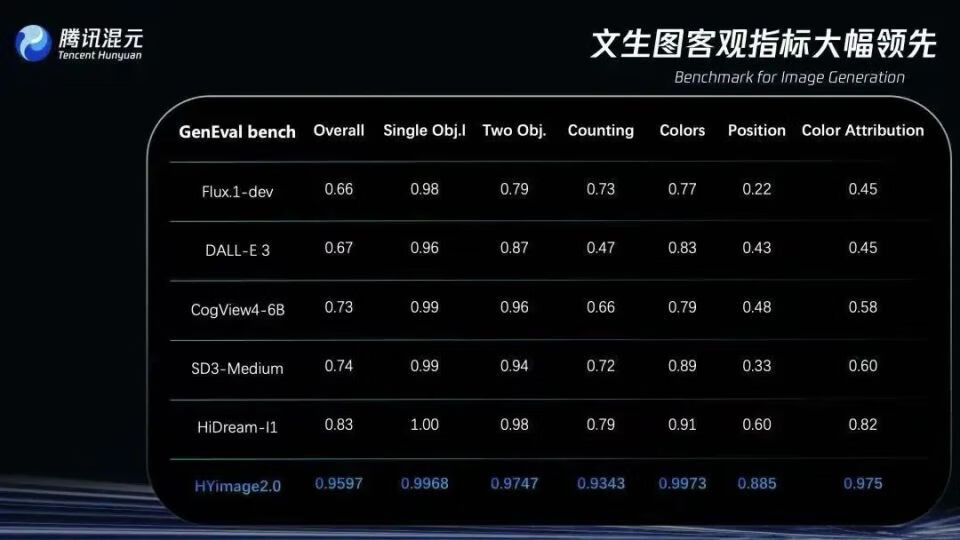
5月16日,腾讯混元推出Hunyuan Image2.0(混元图像2.0模型),基于超高压缩倍率的图像编解码器,全新扩散架构,实现超快的推理速度和超高质量图像生成,极大降低“AI味”。
这个模型的诞生,意味着图像生成进入了“毫秒级”时代——"所见即所得",输入提示词的同时,即可看到图像发生变化,非常震撼。
腾讯科技在第一时间进行了实测:
1、 文生图指令遵循的能力很强,能按照文字的改变,实时修改图片中的内容;
2、 图生图有“参考主体”、“参考轮廓”两种模式,用户可以自己设定参考的强度。实现图片的二次编辑能力。但是在实测中,对于轮廓不太清晰的图片,参考轮廓的模式可用性稍差;
3、 对专业设计来说,结合画板给线稿进行上色、生成各种风格、调光影,可以及时方便看到效果;
4、 双画布联动中的多图层融合功能,存在一定抽卡概率,需要多次调试(比如主体参考强度、提示词)才能达到比较好的效果。
目前,模型已经开放体验,体验地址为:https://hunyuan.tencent.com/(限pc端)。
普通人实现绘画自由
所思即所见
毫秒级响应这个词汇比较抽象,在测试中的体验是,随着用户打字输入,实时能够生成我们想要的东西。
比如,我逐渐输入提示词:人像摄影,爱因斯坦,背景是东方明珠电视塔,自拍角度。可以看到,画面是在实时变化的,加入了背景,并在最后切换了拍摄角度。

人物的表情也可以瞬间改变,比如让爱因斯坦吐舌头:

除此之外,还可以连续对画面增加或修改多个细节:一个女生,亚洲面孔,大眼睛,笑容灿烂,长头发,穿中式服装,戴上帽子,手绘风格。
模型都能够快速实时生成成功,尤其是戴上帽子这个环节。
能够看到,模型给女孩戴上了类似于蓑笠的帽子,和衣服很搭配,比如并没有生成棒球帽等和图片整体风格“违和”的元素。

2、 图像生成图像:可调节遵循强度
除了文字直接生成图片,混元图像2.0也支持上传参考图,通过图生图。
但是,和传统生图模型不同的是,混元图像2.0可以提取主体或轮廓特征,融合文本指令生成新图像。用户可以自由选择参考主体、或参考轮廓两个模式。
如果选择参考主体,模型将会保持主体的一致性 ,角色、物体在生成中保持特征统一(如脸部,物体等)。而且,还能支持选择“参考强度”,强度越强,模型会越遵循原图主体;强度越弱,越有想象力。

图:主体一致输出,从左第一张图表示主体图,后面依次是主体图权重从低到高对应的效果图
通过图生图-参考主体这个功能,可以轻松给自己家宠物生成各种“整活儿”图片,比如上传一张猫咪照片,图像参考强度设定为92,让猫咪眼睛变大,在草地上,戴上皇冠。

如果选择参考轮廓,模型会自动提取图片的轮廓,比如左图的机器猫,会被提取成右图的“线稿”,然后我们还可以根据自己的想法输入提示词进行二次创作。比如给它二次上色,转换风格,搭配背景、光影。
但是,这里也发现了一个小缺陷,如果上传毛绒绒的轮廓不清晰的物体,比如上面案例中的小猫,模型就很难提取出轮廓。

同样,参考轮廓也可以设定参考的强度,比如下面的例子,左边第一张图表示边缘图,后面依次是轮廓图权重从低到高对应的效果图。

专业画师的生产力工具
实时文生图的功能,普通用户可以0门槛上手。如果有设计基础,还可以使用“双画布联动”画笔:左侧勾线,右侧即刻呈现上色预览,将过去“绘制—等待—修改”的创作流程压缩为一气呵成的实时预览。
比如下面这个案例,上传一张简单的汽车线稿,用prompt给它加上背景及颜色,迅速能够出现一个效果图片。但是在测试中我们发现,双画布的指令反应速度,可能会比实时文生图稍慢。

还可以实时对图片进行风格的修改,添加小元素,对比和原图的效果。比如下面的例子,通过一张小猫的图片,生成“家居猫、公主猫、古惑仔猫”。

再比如,将以下这只小狗放到游乐场中,戴上项圈,并转变风格。但是在测试中,我们发现,对于风格的定义会有主观性,有的时候复现的并不是我们脑中想象的样子,可能需要更多的细节进行描述。下面这只陶土风格的小狗,就和我的想象有点差别。

另外,以下面这只赛博朋克风格的小狗为例,虽然模型能够识别并执行指令,但生成图像中的主体风格转换和元素添加并未完全体现“赛博朋克”的特征,要达到理想的风格效果仍需通过多轮提示词调整。但是与其它模型不同的是,即使需要调整,也能立即看到效果。

对于设计师来说,还有一个多图层融合的实用功能,支持将多个草图/图片(如人物、配饰)叠加至同一画布,自由DIY,AI 自动协调透视与光影,对应提示词内容,生成融合图像。但是这个功能,存在一定抽卡概率,需要多次调试(比如主体参考强度、提示词)才能达到比较好的效果。

但是,对于AI生成图片来说,即使是需要调整,速度快确实能“解千愁”,人类终于不必在等待中消磨创意,甚至让普通人也感受到了“神笔马良”般的超能力。