刚刚,红杉中国推出全新 AI 基准测试 xbench!在 AI 下半场定义“好问题”,以及 Agent 技术市场匹配的三个阶段

今天,红杉中国发布了全新的 AI 基准评测体系 xbench(xbench.org),并同步发布论文《xbench: Tracking Agents Productivity, Scaling with Profession-Aligned Real-world Evaluations》。
这是首个由投资机构发起,联合国内外十余家顶尖高校和研究机构的数十位博士研究生,采用双轨评估体系和长青评估机制的AI基准测试。
也是红杉在 AI 基础模型赛道重金布局后的又一标志性动作。xbench将在评估和推动AI系统能力提升上限与技术边界的同时,重点量化AI系统在真实场景的效用价值,并长期捕捉Agent产品的关键突破。
当前基础模型的快速发展和AI Agent进入规模化应用,被广泛用于评估AI能力的基准测试(Benchmark)却面临一个日益尖锐的问题 —— 想要真实反映AI系统的客观能力正变得越来越困难,这其中最直接的表现——基础模型“刷爆”了市面上的基准测试题库,纷纷在各大测试榜单上斩获高分甚至满分。

因此,构建一个更加科学、长效和反映AI客观能力的评测体系,正在成为指引AI技术突破与产品迭代的重要需求。

▍xbench 基准测试特点
xbench采用双轨评估体系,构建多维度测评数据集,旨在同时追踪模型的理论能力上限与Agent的实际落地价值。该体系创新性地将评测任务分为两条互补的主线:
评估AI 系统的能力上限与技术边界;
量化AI 系统在真实场景的效用价值(Utility Value)。其中,后者需要动态对齐现实世界的应用需求,基于实际工作流程和具体社会角色,为各垂直领域构建具有明确业务价值的测评标准。
xbench 采用长青评估 (Evergreen Evalution)机制,通过持续维护并动态更新测试内容 ,以确保时效性和相关性。xbench将定期测评市场主流Agent产品,跟踪模型能力演进,捕捉 Agent产品迭代过程中的关键突破,进而预测下一个Agent 应用的技术-市场契合点(TMF,Tech-Market Fit)。作为独立第三方,xbench致力于为每类产品设计公允的评估环境,提供客观且可复现的评价结果。
首期发布包含两个核心评估集:科学问题解答测评集(xbench-ScienceQA)与中文互联网深度搜索测评集(xbench-DeepSearch),并对该领域主要产品进行了综合排名。同期提出了垂直领域智能体的评测方法论,并构建了面向招聘(Recruitment)和营销(Marketing)领域的垂类 Agent评测框架。
在过去两年多的时间里,xbench一直是红杉中国在内部使用的跟踪和评估基础模型能力的工具,今天红杉将其公开并贡献给整个AI社区。无论是基础模型和Agent的开发者, 还是相关领域的专家和企业,或者是对AI评测具有浓厚兴趣的研究者,xbench都欢迎加入,成为使用并完善xbench的一份子,一起打造评估AI能力的新范式。
xbench最早是红杉中国在2022年ChatGPT推出后,对AGI进程和主流模型进行的内部月评与汇报。在建设和不断升级“私有题库”的过程中,红杉中国发现主流模型“刷爆”题目的速度越来越快,基准测试的有效时间在急剧缩短。正是由于这一显著变化,红杉中国对现有评估方式产生了质疑——
“当大家纷纷考满分的时候,到底是学生变聪明了,还是卷子出了问题?”
▍红杉中国希望解决的问题与思路
因此,红杉中国开始思考并准备解决两个核心问题:
1)模型能力和AI实际效用之间的关系?基准测试的题目越出越难,意义是什么?是否落入了惯性思维?AI落地的实际经济价值真的会和AI做难题呈正相关吗?
2) 不同时间维度上的能力比较:在xbench每一次更换题库之后,就失去了对AI能力的前后可比性追踪。因为在新的题库下,模型版本也在迭代,无法比较不同时间维度上单个模型的能力如何变化。
在判断创业项目的时候,创业者的“成长斜率”是一个重要依据,但在评估AI能力上,题库的不断更新却反而让判断失效。
为了解决这两个问题,xbench给出了新的解题思路:
1) 打破惯性思维,为现实世界的实用性开发新颖的任务设置和评估方式。
当AI进入“下半场”,不仅需要越来越难的AI Search能力的测试基准(AI Capabilities Evals),也需要一套对齐现实世界专家的实用性任务体系(Utility Tasks)。前者考察的是能力边界,呈现形式是score,而后者考察的实用性任务和环境多样性,商业KPIs(Conversion Rate, Closing Rate)和直接的经济产出。
因此,xbench引入了Profession Aligned的基准概念,接下来的评估会使用“双轨制”,分为AGI Tracking和Profession Aligned,AI将面临更多复杂环境下效用的考察,从业务中收集的动态题集,而不单是更难的智力题。
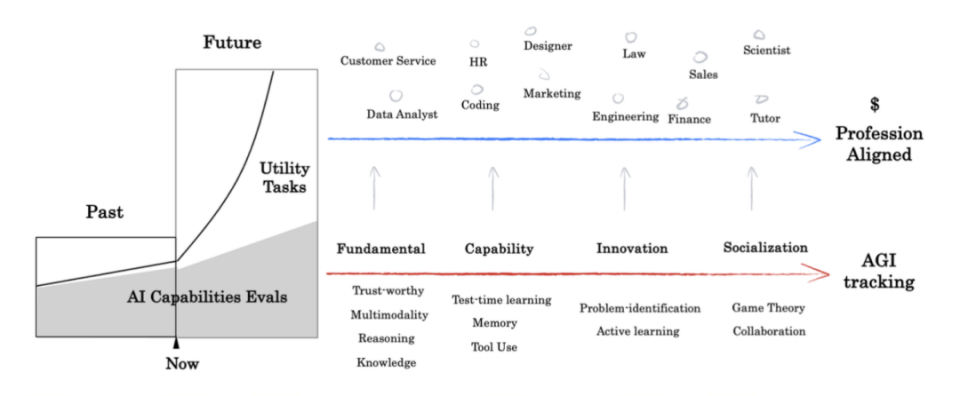
2)建立长青评估体系。静态评估集一旦面世,会出现题目泄露导致过拟合然后迅速失效的问题;如LiveBench与LiveCodeBench评估的出现,利用动态更新的题目扩充评估集,缓解了题目泄露的问题。
针对AI Capacity Evals:学术界提出了很多出色的方法论,但是受限于资源与时间不充分,无法维护成动态扩充的持续评估。xbench希望能延续一系列公开评估集的方法,并提供第三方、黑白盒、Live的评测。
针对Profession Aligned Evals:xbench希望建立从真实业务中Live收集机制,邀请各行业的职业专家共同构建和维护行业的动态评估集。
同时,在动态更新的基础上,xbench设计可横向对比的能力指标,用于在时间上观察到排名之外发展速度与关键突破的信号,帮助判断某个模型是否达到市场可落地阈值,以及在什么时间点上,Agent可以接管已有的业务流程,提供规模化服务。
▍评估 Agent 的技术市场匹配(Tech-Market Fit)
在Agent应用的评估任务中仍有新挑战。利用动态更新的题目扩充评估集来缓解这一现象。
首先,Agent应用的产品版本是具有生命周期的。Agent产品的迭代速度很快,会不断集成与开发新功能,而旧版本Agent可能会被下线。我们虽然可以在同一时间测试同类Agent不同产品的能力,但是不能比较不同时间的产品能力进步。
同时,Agent接触的外部环境也是动态变化的。即使是相同的题目,如果解题需要使用互联网应用等内容快速更新的工具,在不同时间测试效果不同。

成本也是Agent应用落地的决定性因素之一。 Inference Scaling让模型与Agent可以通过投入更多推理算力来取得更好的效果。这种投入既可以来自于强化学习带来的更长思维链,也可以是在思维链的基础上引入更多次数的推理与汇总进一步提升效果。
然而在现实任务中需要考虑Inference Scaling带来的投入产出比,找到在花费、延迟与效果上的平衡。
类似于ARC-AGI,我们会追求为每个评估集汇报在效果-成本图上的需求曲线、人类能力曲线以及现有产品的最优供给曲线。 在Benchmark的得分-成本图上,我们可以划分出左上区域的市场接受区与右下的技术可行区。
人力成本应当是市场接受区边缘的一部分。左图展示了技术尚未落地的状态,而中间图展示了TMF后的状态,而其中交叉部分是AI带来的增量价值。
对于具有TMF的AI场景,人力资源应当更多投入在领域的前沿以及不可评估的任务,并且市场会因为人力资源与AI算力的稀缺性不同重新给人类贡献的价值定价。
认为每个专业领域会经历3个阶段:
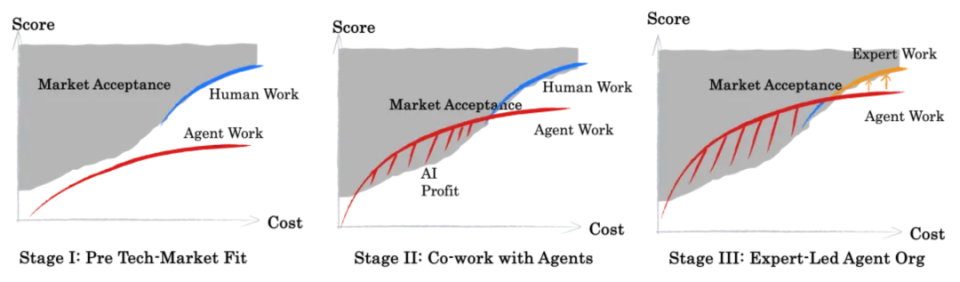
1. 未达成TMF:技术可信与市场接受区域没有交集,此时Agent应用仅是工具或概念,无法交付结果或规模化产生价值;Agent对人的影响较小。
2. Agent与Human共同工作:技术可信与市场接受区域发生交集,交叉区域是AI带来的价值增量,包括(1)以低于最低人类成本提供可行服务,(2)帮助提升应对重复性、质量要求中等的工作内容。而高水准的工作内容,由于数据稀缺、难度更高、依然需要人来执行,此时由于稀缺性,企业获取的AI Profit可能会被用于支付高端工作产出。
3. 专业化Agent:领域专家在构建评估体系,并指引Agent迭代。专家的工作从交付结果转向构建专业评估训练垂类Agents,并提供规模化服务。
其中从1.向2.的转变是由AI技术突破、算力与数据的Scaling带来的,而2.转向3.的进展依赖于熟悉垂类需求、标准、历史经验的专家。
此外,在部分领域中,AI可能带来新的满足需求的方式,改变已有的业务流程和生产关系组成方式。
在xbench推出当天,官网xbench.org上线了首期针对主流基础模型和Agent的测评结果。
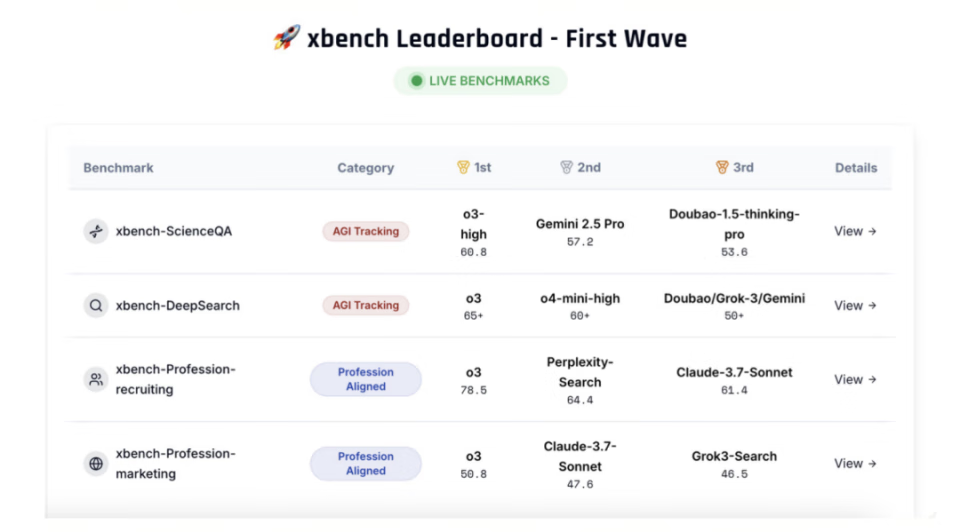
红杉中国表示:xbench欢迎社区共建。对于基础模型与Agent开发者,可以使用最新版本的xbench评测集来第一时间验证其产品效果,得到内部黑盒评估集得分;对于垂类Agent开发者、相关领域的专业和企业,欢迎与xbench共建与发布特定行业垂类标准的Profession Aligned xbench;对于从事AI评测研究,具有明确研究想法的研究者,希望获取专业标注并长期维护评估更新,xbench可以帮助AI评估研究想法落地并产生长期影响力。
✦ 精选内容 ✦