红杉中国,准备这样预测下一个AI独角兽 | 笔记
我们去年底发了一篇展望2025年AI的文章,其中第2条提到了AGI测试基准迅速饱和的问题,认为2025年将提出更难的基准,但AGI仍然很难跨越莫拉维克悖论。
这种悖论,部分体现在那些前沿AI模型可以解出奥数题,却难以完成实际工作中初级员工的任务。而智能体的实际应用,恰恰是从完成简单的工作任务开始。
红杉中国想跨越这个悖论,推出了xBench,测评专业领域智能体的表现——从完成简单的任务开始。
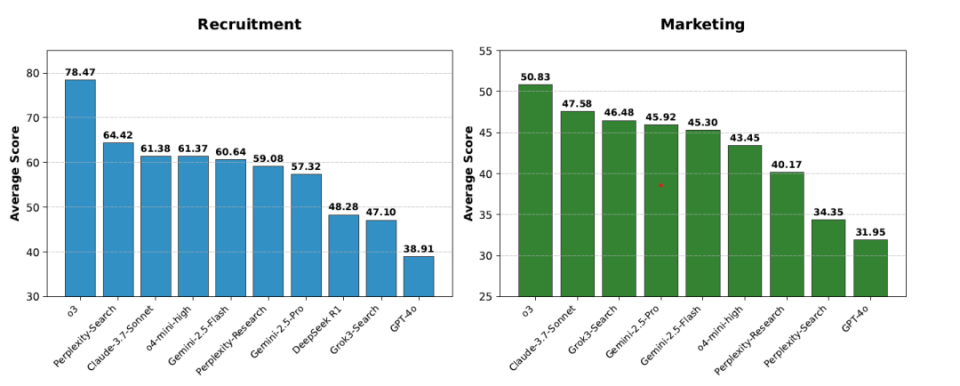
(招聘和营销两个专业智能体的xBench测评结果)
如果说当初ChatGPT带给人们的惊喜来自实际对话的体验,GPT-4的发布所引发的震撼,基本上是来自其刷题的分数。
它的技术报告中,用一系列学术和专业资格试题来测试GPT-4,得分达到甚至超过了人类的平均水平;在一系列美国大学本科和研究生入学,律师资格考试等专业领域,以及有关科学和数学的通识,初步的视觉和推理能力,编程能力等方面,实现了对GPT-3.5的大幅度提升。
配合这个模型的发布,微软发布了一篇论文称,GPT-4呈现了早期的“火花”;而OpenAI请了几位经济学家,发布一篇论文,根据GPT-4在各职业岗位技能上广泛的可替代程度,提出了生成式AI是一种通用技术(General Purpose Technologies),即GPTs are GPTs。
论文调查了美国1016种职业,包括工作行为的具体描述,将其进一步分解为每种职业的具体任务,共计19265种。对应GPT所训练出的基础能力,微调出来的具体专业领域的能力,以及融合其他技术的能力,与目前所有职业技能进行对照,划分其对GPT “暴露”的程度。
调查结果表明,大约 80% 的美国劳动力至少有 10% 的工作任务会受到 GPT 的影响,而大约 19% 的员工可能会看到至少 50% 的工作任务受到影响。这种影响涵盖所有工资水平,高收入工作可能面临更大的暴露风险。这个硬币的另外一面是,AI如果能接管现有的许多工作技能,将会创造巨大的价值。
今天回头看来,AI大模型通的通用智能,可以通过刷题获得高分,达到大学生甚至博士的水平,可以在对话中侃侃而谈,学识渊博,而在真实世界的应用中却显得“低能”。大模型过分依赖这类测评获得存在感,在一定程度上会陷入了刷题与刷榜的游戏。
OpenAI o3的发布再一次在ARC-AGI的测评中取得高分,在编程、数学、科学等一系列基准测试中成为学霸中的学霸,让测评分数都不够用了,迅速趋于饱和。
这个评价体系的创始人François Chollet 认为,o3可以解出奥数题,却在一些非常简单的任务上仍然会失败,新出一道小学数学可能轻松拿捏它,“这表明它与人类智能存在根本性的差异。”
与此同时,大模型也在撞上数据墙,各种围绕刷题和刷榜的demo,在经过了近两年的“核弹”、“王炸”级别的不断的炒作之后 ,令人产生疲劳感,人们越来越关注AI大模型的“高分低能”问题。
应该把大模型当成一个智能体,投入到实际工作中,并对其表现进行考评,而不是仅仅停留在教室和实验室里测试它们的分数。已经有一些开创性的测评方式,如硅谷研究机构METR,对OpenAI及Anthropic大模型完成的1460项任务,根据其所用的时长、完成程度和成本进行分析,初步得出了智能体接管人类工作的进展轨迹。
红杉中国也走过了同样的路。2022年ChatGPT推出后,红杉中国密切追踪AGI的进程,每个月测评主流模型,在内部汇报和投资参考。他们在中国同样也遇到了测试基准快速“饱和”的问题,主流模型从20-30分在18个月内提升到90-100分。
2024年10月,OpenAI推出推理模型o1之后一个月,红杉中国大规模更新了xbench题库,换掉了所有都得满分的题,新增的试题主要针对Chatbot复杂问答及推理,以及简单的模型外部工具调用能力。结果这一次题库被大模型更快地刷爆,仅用了6个月。
2025年3月,红杉开始第三次对xbench题库进行升级,这一次,他们开始停下来质疑现有评估方式,思考两个核心问题:
模型能力和AI实际效用之间的关系:“我们出越来越难的题目意义是什么,是否落入了惯性思维?AI落地的实际经济价值真的和AI会做难题正相关吗?” 举个例子,程序员工作的Utility Value很高,但AI做起来进步非常快,而“去工地搬砖”这样的工作AI却几乎无法完成。
不同时间维度上的能力比较:“每一次xbench换题,我们便失去了对AI能力的前后可比性追踪,因为在新的题集下,模型版本也在迭代,我们无法比较不同时间维度上的单个模型的能力如何变化。” 这样的测评,在判断创业项目的时候,尤其是在评估AI能力这件事上,可能已经失灵。
这次红杉中国决定从水平到垂直,进入一个个行业领域,去发现智能体的劳动生产率,基于AI技术与市场匹配(Technology Market Fit,TMF),甚至预测AI技术将率先在哪些领域实现大规模应用,从而尽早发现优秀的产品和团队。
xBench既测试AI的系统能力上限与技能边界,即AGI能力,也会量化AI系统在真实场景中的效用值(Utility Value)。如果说前者是对齐人类的抽象思维范式和价值观,那么后者则动态对齐现实世界的真实需求,基于实际工作流程和具体社会角色,为各垂直领域构建具有明确业务价值的测评标准。
xbench还采用长青评估(Evergreen Evaluation)机制,通过持续维护并动态更新测试内容,以确保时效性和相关性。xBench将定期测评市场主流智能体产品,跟踪模型能力演进,捕捉智能体产品迭代过程中的关键突破,进而预测下一个智能体应用的TMF。
红杉中国要构建 xbench 指数,服务于它的AI独角兽捕获机器。通过长期更新的评估追踪并预测代理产品之间的竞争格局:“我们可以追踪交替领先的产品,同时也希望发现能力在短期内迅速提升的新秀产品。”
红杉中国称之为AI“下半场的评估”,目前已经被证明了的赛道是AI编程,接下来,招聘和市场营销可能是基于深度搜索技术而产生的两个充满机会的AI应用赛道。
33位中美顶尖名校中国博士组成的团队,与这两个行业专家合作,提炼出了真实的需求和工作流程,具体到时间分配,并且计算出每个工作环节和模块的市场价值。
行业专家对具体的工作提出要求,通过搜索智能体输出结果,如应聘候选人专业表现,然后由大型语言模型进行评判,得出分数。
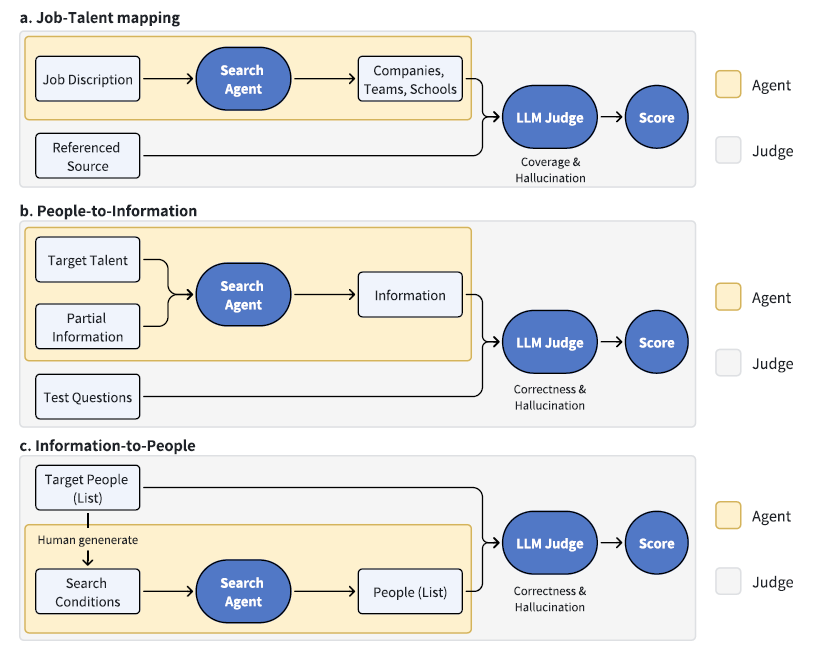
(对招聘智能体工作流程的打分)
基于这样的方法,红杉在5月份对前沿模型的最新版本的招聘和营销智能体的能力进行了测评,推出了榜单,并且首次对外公开xBench。红杉想以此来建立一个动态的榜单和指标体系,对模型研究者和垂直智能体的开发者开放测评结果。
具体到抽象的过程,比较能反应中国创业者的特点,尤其是是在进入智能体创业的阶段,是不是还要“通用”,什么是“通用”。从MANUS等中国创业者最早提出通用智能体这个概念,并且引发出现象级的主张之后,我们可以看到,它实际上把“通用”建立在一系列创造经济价值的的典型行业与场景之上,它是一个演变泛化的过程。它与硅谷创业者所擅长的从抽象到具体形成互补。
--
参考报告:
https://xbench.org/#/reports