3B超越DeepSeek,大模型终于理解时间了!Time-R1一统过去/未来/生成

新智元报道
新智元报道
【新智元导读】Time-R1通过三阶段强化学习提升模型的时间推理能力,其核心是动态奖励机制,根据任务难度和训练进程调整奖励,引导模型逐步提升性能,最终使3B小模型实现全面时间推理能力,超越671B模型。
时间,是我们日常生活中最基础的概念。
但对于大语言模型(LLM)来说,它们或许能写诗作画、通晓古今,但在真正理解和运用时间概念时,却常常显得力不从心。
这个技术短板来自于大模型的底层设计,无法避免:
训练语料库是静态的,存在知识截断时间;在按非时间顺序的语料训练过程中,跨越不同时期的时间信息是同时处理的,不像人类逐步接收知识,阻碍了在事件与其对应时间之间建立可靠的逻辑映射。
现有的方案如时间对齐、外部知识库等,如同「打补丁」,哪差补哪,始终未能实现「理解-预测-生成」的全链路突破。
最近,来自伊利诺伊大学香槟分校的研究人员发布了一份突破性成果Time-R1,基于一个仅3B的小模型,通过精心设计的三阶段的课程强化学习,实现理解过去、预测未来甚至创造性生成大一统。
该框架的核心创新在于其精心设计地动态的、基于规则的奖励机制,像一位经验丰富的导师,逐步引导模型掌握时间的奥秘。

论文地址:https://arxiv.org/abs/2505.13508
代码地址:https://github.com/ulab-uiuc/Time-R1/tree/master
模型地址:https://huggingface.co/collections/ulab-ai/time-r1-682626aea47cb2b876285a16
数据集地址:https://huggingface.co/datasets/ulab-ai/Time-Bench
直播回放:https://b23.tv/aArKNSY
Time-R1的具体实现由三个阶段组成:
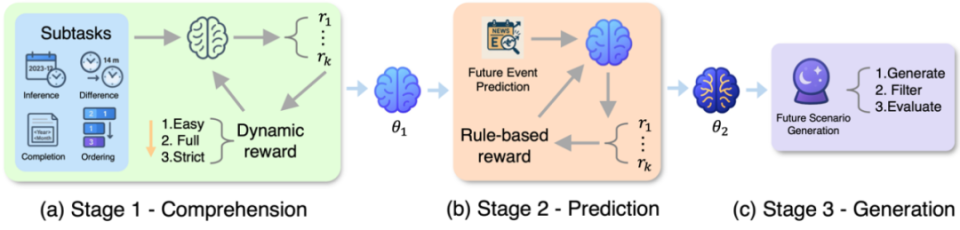
(a)阶段1通过四个时间子任务进行强化微调,建立时间观念的基本理解;(b)阶段2在阶段1的基础上进一步使用知识截止时间后以及合成的数据来训练,锻炼预测未来的能力;(c)第3阶段直接进行创造性未来情景的生成。
第一阶段,构建「时间认知基石」,通过在四大特训任务上的强化微调,建立事件与时间的精准映射:时间戳推理,时间差计算,事件排序,时间实体补全;
第二阶段,跨越知识边界的未来预测,在严格隔离未来数据的前提下,在阶段一得到的模型checkpoint基础上继续强化微调,让模型从历史规律中自主推演趋势;
第三阶段,零样本创意生成,无需额外训练,直接生成指定未来时间下合理的推演未来场景。

Time-R1在面对未来导向问题的真实回答。(左)未来事件时间预测;(右)创造性场景生成,输出与未来发生的现实新闻比较。
Time-R1的成功很大程度上归功于研究人员为每个子任务量身定制的、极其细致的奖励函数。
这套奖励机制的代码总行数超过了1200行,每一个设计细节,都是在模型试图「钻空子」、寻找捷径时,针对性地提出「反制措施」,是无数次实验和迭代的结晶。
格式遵循奖励:如果输出格式符合任务要求(例如日期格式为「YYYY-MM」),则给予少量奖励。 这也是准确性评分的前提。
标签结构奖励:对正确使用<think>和</answer>等结构标签给予奖励,以鼓励「思考链」式的推理过程。
长度与重复惩罚:惩罚过于冗长或重复的输出,这在实验中被证明非常有效。该惩罚项综合考虑了总长度和多种重复情况(如连续词语重复、短语重复、n-gram多样性不足等)。
准确度奖励,是奖励机制的核心,针对每个任务的特性进行设计:
时间戳推断:奖励基于推断日期与真实日期之间的月份差距,采用指数衰减函数,其中设计一个衰减系数α能让模型感知到其时间误差的「大小」,同时还设计了动态调整机制。
时间差估计:奖励综合了两个事件日期的推断准确性以及它们之间时间差的准确性,并引入了不一致性惩。这个惩罚项用于惩罚模型明确推断的时间差与其推断的两个日期所暗示的时间差之间的矛盾,确保模型输出的内部逻辑自洽。
事件排序:奖励同样综合了各事件日期的推断准确性和最终排序的准确性。
此任务中,设计了不一致性惩罚(确保推断顺序与推断日期所指示的顺序一致)和多样性惩罚(惩罚所有推断日期都相同或日期呈简单序列的「平凡解」),鼓励模型推断出更多样化和真实的事件日期分布。
掩码时间实体补全:奖励综合事件日期推断的准确性和被掩码实体(年份或月份)补全的准确性。特别地,当掩码实体是「月份」时,会计算预测月份与真实月份之间的「循环差异」,以更好地捕捉月份的邻近性。
为了解决从零开始微调LLM进行专门时间任务时的「冷启动」挑战,并培养模型在难题上的稳健表现,研究团队在第一阶段引入了动态奖励机制。
根据任务难度和训练进程,动态调整日期准确性奖励部分中的衰减系数α
通过上述精心设计,Time-R1在第一阶段取得了令人瞩目的成绩。
根据最新的实验结果,Time-R1 (3B) 在第一阶段的基础时间理解任务上,其综合表现已经成功超越了参数量200多倍的DeepSeek-V3-0324模型(0.647)!
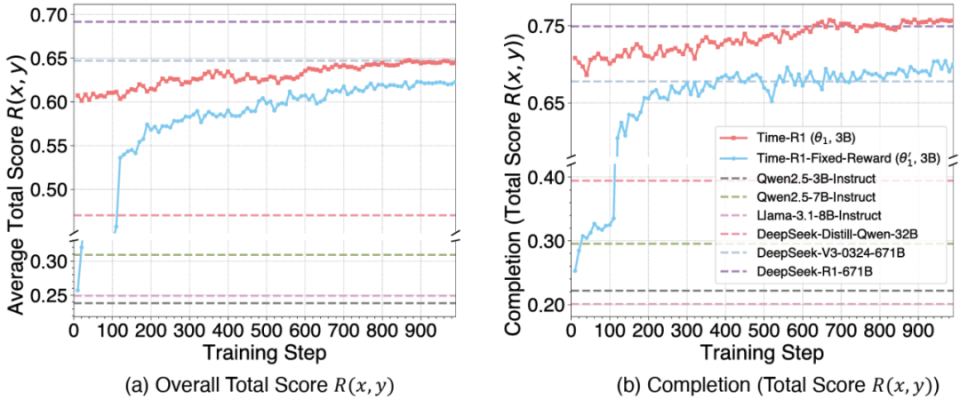
Time-R1第一阶段的训练曲线与baselines对比。红色:Time-R1,具有三过程动态奖励机制。蓝色:没有动态奖励设计的消融实验。
图中的结果也有力的证明了动态奖励机制的有效性。
在有了基础时间推理能力后,继续训练的Time-R1在未来事件时间预测上取得了最高的平均总得分,在整个预测时间范围内(2024年8月至2025年2月)持续优于包括DeepSeek-R1和DeepSeek-V3在内的大多数基线模型。

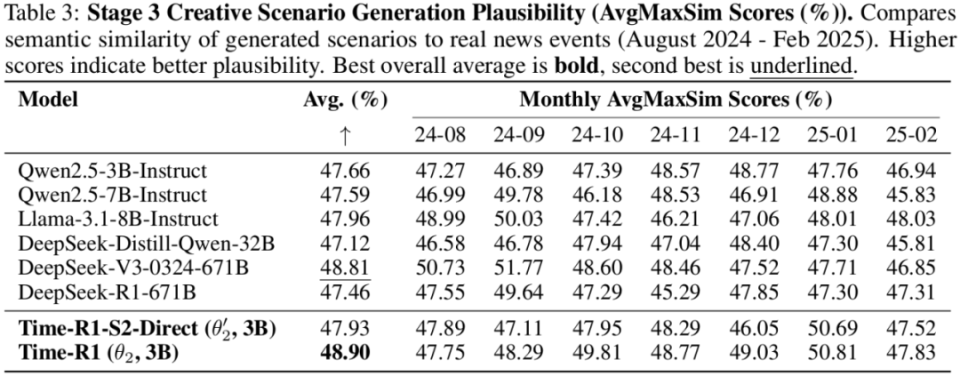
接着,在没有任何微调的情况下,创造性场景生成任务中,Time-R1同样取得了最佳的平均最大相似度得分(衡量生成新闻与真实新闻的语义相似度),再次超越了所有基线模型,展现了强大的泛化能力,有力地证明了前两阶段训练范式的成功。
Time-R1,一个3B参数语言模型,通过一种新颖的、精心设计的三阶段强化学习课程和动态奖励系统,实现了全面的时间推理能力——涵盖理解、预测和创造性生成,碾压671B巨无霸模型。
这一成功直接解决了大模型领域一个重要的痛点,并证明了先进的、渐进式的强化学习方法能够使更小、更高效的模型实现卓越的时间性能,为实现具有巨大应用潜力的、真正具备时间意识的人工智能提供了一条实用且可扩展的路径。
同时研究团队实现了全面开源,不仅发布了Time-Bench由200000余条的10年纽约时报新闻打造的大型多任务时间推理数据集,还发布了Time-R1完整训练代码以及各阶段模型检查点,积极促进下一步的研究和发展。
论文一作刘子嘉是同济大学直博生,导师为严钢教授,目前在美国伊利诺伊大学香槟分校(UIUC)访问交流,接受Jiaxuan You教授指导,博士期间围绕论文选题取得一系列成果:
在顶级期刊Physical Review X以第一作者发表「Early predictor for the onset of critical transitions in networked dynamical systems」文章,被顶级Nature子刊Nature Physics进行专门报道。
同时,工作成果「Attentive Transfer Entropy to Exploit Transient Emergence of Coupling Effect」发表于人工智能顶会NeurIPS,并被收录为「Spotlight」。
博士在读期间,发表多篇高水平论文,并被多次引用。
