苹果AI应用迟疑,还在思考“大模型会思考吗|笔记
用户和投资者一直对苹果在AI的动作迟缓感到不满,它既不自己研究前沿大模型,对于采纳外部模型也非常谨慎。这次WWDC会又一次跳票Siri和其他重要的Apple Intelligence功能。
可能有一个最重要的原因,是苹果一直觉得大模型不靠谱。
苹果在自己的网站上公开了一篇论文,认为推理大模型(LRM)的思考能力,无非是幻觉。而8个月前,几乎是同一组研究员,指出了大语言模型(LLM)中数学推理的局限性。
这次他们对比了LRM与LLM,在同等计算预算下,他们发现:
低复杂度任务:LLM反而优于LRM;
中等复杂度任务:LRM通过增加“思考”展现出优势;
高复杂度任务:两类模型均出现全面崩溃。

苹果研究团队并不相信大模型的基准测试,而是自己设计了一个测试环境。尤其是在编程和数学领域的基准模型,研究团队认为存在数据污染问题,即用于模型训练的数据与基准数据出现了直接或间接的重合。
这次,苹果研究团队构建了一个可控制解谜环境 (controllable puzzle environments ),采用了四个智力游戏,以可控的任务评估LRM的推理能力:汉诺塔(Tower of Hanoi) ,跳棋(Checker Jumping) ,渡河(River Crossing) ,积木世界(Blocks World) 。
他们发现,即便是当前最先进的LRM(例如 o3-mini、DeepSeek-R1、Claude-3.7-Sonnet-Thinking),在面对不同环境下复杂度提升的问题时,依然无法形成可泛化的问题求解能力,其准确率最终在某一复杂度之后全面崩溃。
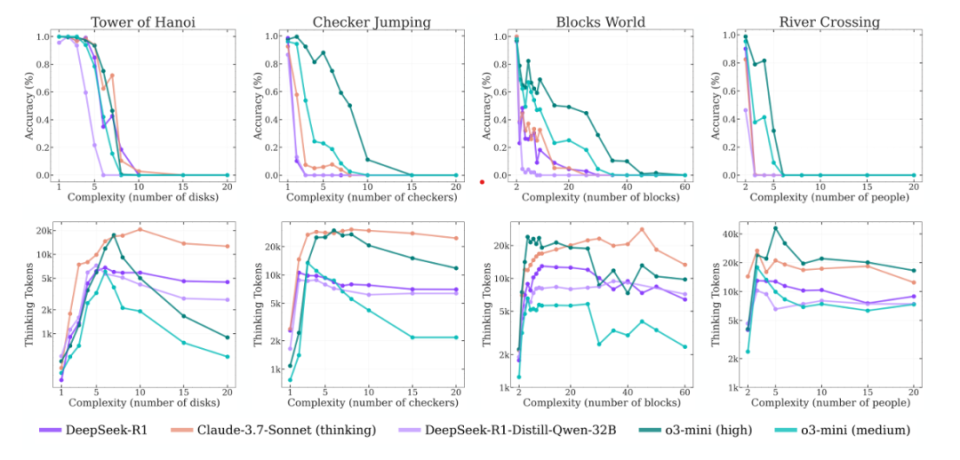
(说明:在不同解谜环境中,推理模型的准确率与思考 token 数量随问题复杂度的变化趋势如下:随着复杂度上升,模型最初会投入更多的思考 token,准确率则逐渐下降,直到达到某个临界点——此时推理过程崩溃,模型表现急剧下滑,且推理努力也随之减少。)
苹果团队对当前以最终准确率为主的评估方式提出了质疑,并引入中间推理过程(thinking traces),借助确定性的解谜模拟器对其进行扩展分析,发现随着问题复杂度上升,正确解答在思考轨迹中系统性地较迟出现,相比之下错误解答更早出现,这为理解LRM内部的自我纠错机制提供了量化线索。
这对激烈的推理模型竞赛是当头棒喝,当下的推理模型的训练范式可能存在着一个根本缺陷,面对真正复杂的问题,扩展定律 (scaling law) 又遇到天花板了:思维 token 的使用量在超过某一复杂度后,反而呈现出反直觉的下降趋势。
这似乎再一次证明了苹果同一个研究团队在8个月前得出的结论:“我们进一步探究了这类模型数学推理能力的脆弱性,发现随着题目中语句数量的增加,其性能会显著下降。我们推测,这种性能恶化的根本原因在于:当前LLMs并不具备真正的逻辑推理能力,它们只是试图模仿训练数据中所观察到的推理过程。”

所以,大模型真的会思考吗?可能库克和苹果的研究人员还在思考这个问题。也许从中可以部分理解为什么苹果在拥抱大模型方面表现得如此谨慎。
苹果掌管软件工程的高级副总裁费德里吉(Craig Federighi)并不太相信人工智能。他对这项技术投入的大量资金表示“犹豫”,并且不认为这是一种“核心能力”。
Mehrdad Farajtabar参与了苹果上述两篇论文,这次他不客气地问道:“这些被称为“推理模型”的 o1/o3、DeepSeek-R1 和 Claude 3.7 Sonnet,真的在“思考”吗?还是说,它们只是在用更多的算力来做模式匹配而已?