RL缩放王炸!DeepSWE开源AI Agent登顶榜首,训练方法、权重大公开
今天凌晨,著名大模型训练平台Together.ai联合Agentica开源了创新AI Agent框架DeepSWE。
DeepSWE是基于阿里最新开源的Qwen3-32B模型之上,完全使用强化学习训练而成。
除了权重之外,训练方法、日志、数据集等所有内容也全部开源,以帮助开发人员深度学习和改进Agent。
开源地址:https://huggingface.co/agentica-org/DeepSWE-Preview
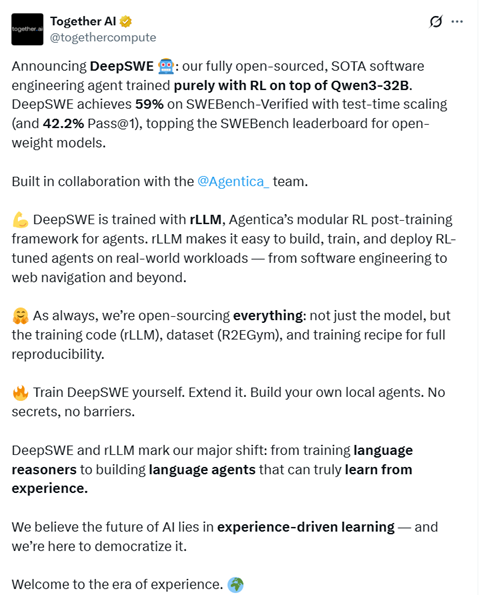
根据SWE-Bench-Verified测试数据显示,DeepSWE在64k最大上下文长度和100最大环境步骤下进行评估,最终在16次运行平均的Pass@1准确率上达到了42.2%,使用混合测试时扩展(TTS)后性能进一步提升至59%,超过了所有开源Agent框架位列榜首。
DeepSWE证明了仅使用强化学习进行训练的有效性和巨大潜力。与其他开源模型相比,DeepSWE-Preview在不依赖于更强专有教师模型的蒸馏或SFT的情况下,依然能够取得了最好的性能。
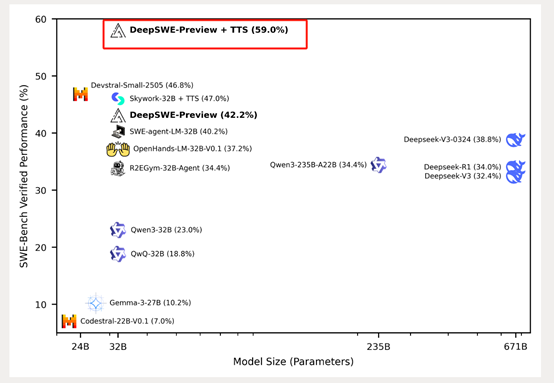
DeepSWE的训练基于rLLM框架,这是一个用于语言智能体后期训练的系统。该模型在64个H100 GPU上对来自R2E-Gym训练环境的4500个真实世界SWE任务进行了6天的训练。
这些任务涵盖了从解决GitHub问题到实现新代码功能和调试等复杂场景,体现了现实世界软件工程的多样性和复杂性。
在训练过程中,DeepSWE-Preview通过与环境的交互,学习如何浏览广泛的代码库、应用有针对性的代码编辑、运行shell命令进行构建和测试,并在解决实际拉取请求时迭代优化和验证解决方案。
在训练方法方面,数据集管理采用了R2E-Gym子集的4500个问题,通过过滤与SWE-Bench-Verified来自相同存储库的问题,确保训练数据的纯净性。
所有问题都被映射到单个Docker镜像中,以便于管理和执行。训练环境围绕R2E-Gym构建,该环境能够可扩展地管理高质量的可执行SWE环境。状态与动作的定义涵盖了执行Bash命令、搜索文件、文件编辑以及完成任务提交等操作。
奖励机制采用稀疏结果奖励模型,即只有当LLM生成的补丁通过所有测试时才给予正奖励,否则奖励为零。为了应对训练过程中出现的扩展挑战,研究人员将Kubernetes支持集成到R2E-Gym中,实现了容器的弹性调度和自动缩放,从而能够可靠地收集数百万个轨迹,同时保持计算成本与负载成比例。
在强化学习算法方面,DeepSWE-Preview的训练采用了GRPO++算法,这是对原始GRPO算法的改进版本。GRPO++整合了来自DAPO、Dr.GRPO、LOOP/RLOO等工作的见解和创新,通过高剪辑、无KL损失、无奖励标准差、长度归一化、留一法、紧凑过滤和无熵损失等策略,实现了更稳定和性能更高的训练过程。

其中,紧凑过滤策略特别针对多轮代理场景,通过屏蔽达到最大上下文、最大步骤或超时的轨迹,防止训练期间的奖励崩溃,并鼓励代理进行跨步骤的长形式推理。
TTS则是DeepSWE-Preview实现性能提升的关键策略之一。在测试阶段,通过生成多个轨迹并选择其中正确解决问题的轨迹,DeepSWE-Preview能够显著提高其Pass@1性能。
研究人员尝试了多种TTS策略,包括基于执行的验证器和无执行的验证器,并最终采用了混合扩展策略,结合了两种范式的优势,从而实现了59.0%的性能,比当前最先进的开源权重模型高出12%。
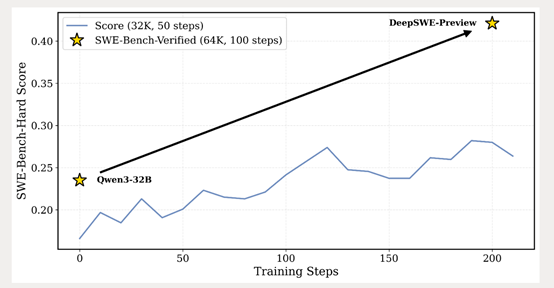
此外,研究人员还发现,对于SWE相关任务,扩展输出token的数量似乎并不有效,而滚动数量扩展则能够带来更显著的性能提升。
本文素材来源Together.ai,如有侵权请联系删除