IndexTTS2:B站的最新语音克隆模型,情绪都能克隆!影视级别效果!


IndexTTS2的前世今生
IndexTTS2 是 B 站语音团队对早期 IndexTTS 模型进行深度优化后推出的全新一代语音合成模型。
其目标是解决早期版本在情感表达细腻度与时长控制精准性方面的问题,让tts技术能够真正的落地,实现AI完美克隆声音。

之前推出过1.0 和 1.5版本,效果就已经很不错了,目前在github上收获了4k⭐

早期版本地址:
https://github.com/index-tts/index-tts
据小道消息,哔哩哔哩内部正在研发一系列AI工具,这个tts也许就是其中之一。
IndexTTS2技术上有哪些突破?
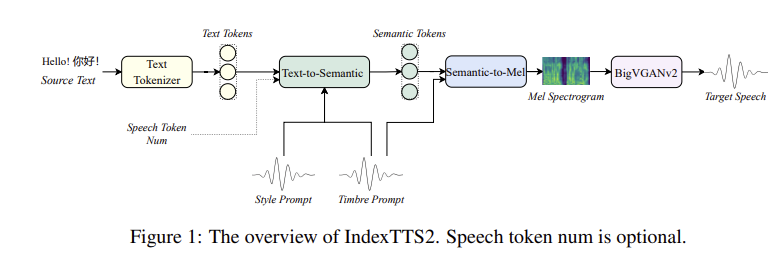
精准时长控制与细腻情感解耦能力
IndexTTS2的核心突破在于首次融合了精准时长控制与细腻情感解耦能力,让AI语音能像"剪辑音频"一样自由调速(用户可直接指定语句毫秒级时长或单词数,支持0.75-1.25倍速调节,彻底解决影视配音口型同步难题)
声音和情绪分离
通过3-10秒参考音频就能克隆特定情感(如愤怒或悲伤),并独立移植到不同音色上,甚至仅用"巨巨巨难过"等自然语言指令就能触发对应情绪;
它是先从参考音频里挑出 “情绪信号”(比如愤怒的调调),再用特殊方法把它和 “音色信号”(比如张三的嗓音)拆开,这样就能随便搭配,甚至直接说 “超级难过”,模型就知道该调出啥情绪,还不影响原本的声音。
用大白话控情绪(比如 “带点委屈”),就像模型里藏了个 “懂人话的翻译”:它提前学过把日常描述转成 “情绪密码”(比如把 “委屈” 对应到预设的情绪模板),你说啥它都能翻译明白,不用学专业操作。
其零样本克隆
其零样本克隆技术仅需5秒音频即可高精度复刻任何人声(相似度超85%),结合抗干扰算法确保强情绪表达时咬字清晰(怒吼场景字错率仅1.883%)
主要靠大规模多语言(中英)和情感数据(55K 条,含 135 小时情绪数据)训练,加上 T2S 的自回归 token 预测(像大语言模型预测下一个词)和 S2M 的流匹配机制(高效学语音特征),让模型见一次新声音 / 情绪就能快速克隆,无需额外训练。
IndexTTS2怎么使用呢?
目前项目还未开源,体验也需要登录哔哩哔哩的官方网站获取内测资格。
想要看官方介绍,可以查看论文或者项目介绍页
论文地址:
https://arxiv.org/pdf/2506.21619
项目介绍首页:
https://index-tts.github.io/index-tts2.github.io/