清华大学开源配音神器:MOSS-TTSD!支持中英双语,生成超长语音(最长960秒),可生成双人
你是否曾经为制作多人对话的播客或视频配音而烦恼?
专业配音成本高昂,传统AI语音生硬不自然
今天给大家介绍一款开源AI工具:MOSS-TTSD

只需两段声音样本和文字脚本,它就能生成自然流畅的双人对话语音,效果逼近真人!
什么是 MOSS-TTSD?
简单来说,MOSS-TTSD 是一个能将文字对话转换成自然语音的工具。
MOSS-TTSD是由清华大学语音与语言实验室联合腾讯AI Lab、复旦大学等机构共同开发的开源语音合成模型。
它支持中英文双语,特别擅长处理两个人的对话场景,能根据脚本自动切换说话人,生成听起来像真实聊天的音频。
还能够处理对话中的特殊声音事件,比如咳嗽、笑声等,增强语音的真实感和表现力。
MOSS-TTSD 不仅支持双语,还能实现零样本多人语音克隆和长达16分钟(960秒)的语音生成。更重要的是,它完全开源,支持免费商用!
MOSS-TTSD原理
MOSS-TTSD 的技术实现虽然复杂,但其核心思想可以简单概括为:将语音分解为“语音单元”,通过语言模型生成这些单元,再将它们合成为自然语音。
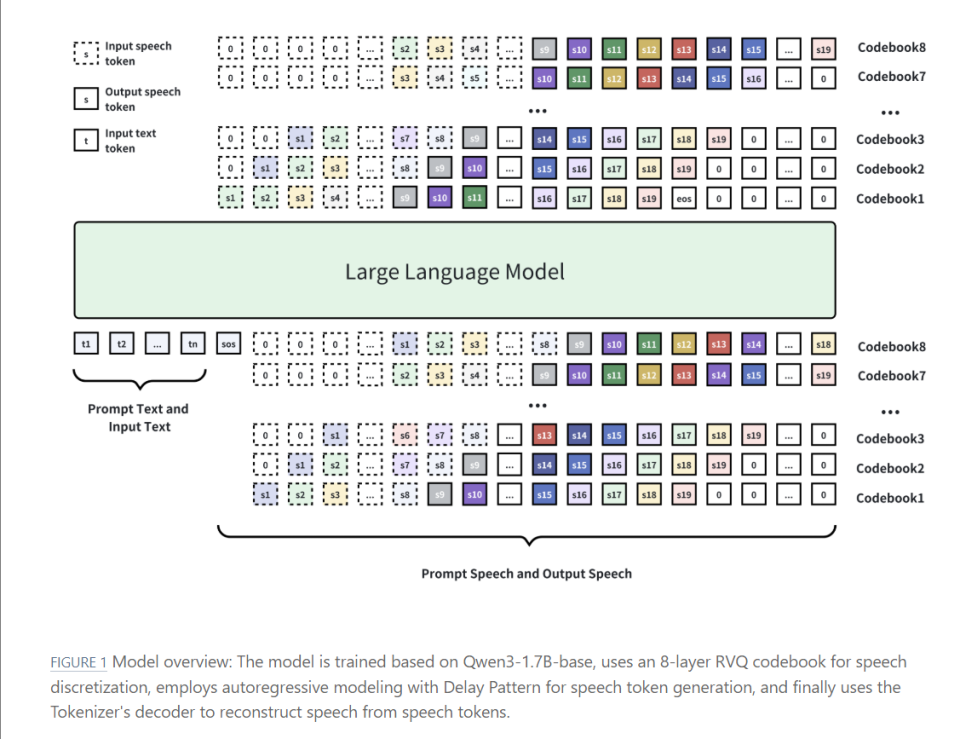
以下是它的主要工作机制:
核心技术
XY-Tokenizer:MOSS-TTSD 使用了一种名为 XY-Tokenizer 的音频编码器,它将原始音频量化为低比特率(1kbps)的离散表示,同时保留语音的语义和声学信息。这种低比特率设计让模型能够高效处理长语音序列。
基于 Qwen3-1.7B 的模型:MOSS-TTSD 以 Qwen3-1.7B-base 模型为基础,通过自回归建模和 Delay Pattern 技术生成语音 token,最后使用解码器将 token 还原为语音。
大规模训练数据:模型训练使用了约 100 万小时的单人语音数据和 40 万小时的对话语音数据(包括 10 万小时中文和 27 万小时英文对话,以及 8 万小时合成的对话数据)。这些数据确保了模型在多种场景下的表现力。
使用方式
要使用 MOSS-TTSD 进行语音合成,首先需要准备好 Python3.10 环境,安装项目依赖
如果使用 GPU,可额外安装加速库如 flash-attn 等。 接着,需要下载 XY-Tokenizer 的预训练权重(项目 README 提供了 Hugging Face 链接)
完成环境配置后,即可进行本地推理。将对话文本准备为 JSONL 格式,然后运行
python inference.py --jsonl <输入文件> --output_dir <输出目录>项目地址:
https://github.com/OpenMOSS/MOSS-TTSD