《猫和老鼠》更新了?!还有方言版本...
我们先看看下面的视频


在视频生成领域,如何让一段只有几秒钟的演示扩展到一分多钟,同时还能保持连贯的风格与内容,是很困难的
ttt-video-dit就是为解决这两个问题而生的工具,就是上面两个视频使用的框架!
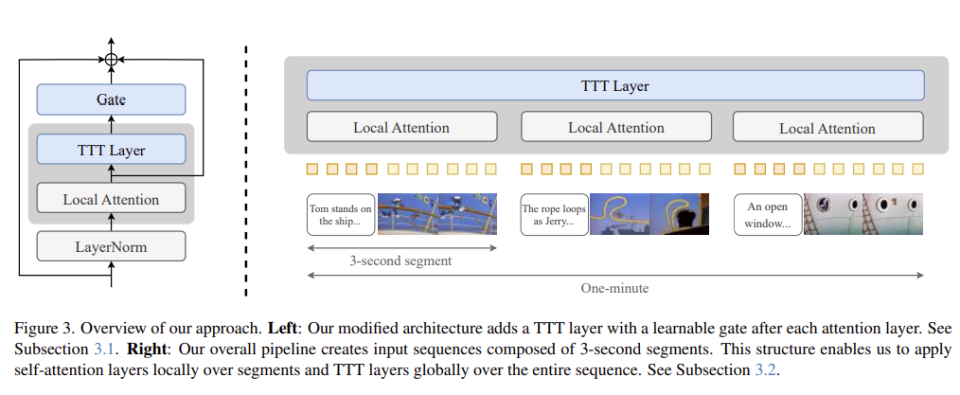
把原始模型的注意力层(attention layers)留作对每个 3 秒分段的“本地”处理,同时在这些段之间插入 TTT 层,用以建模全局的时序依赖。
手把手教你用
首先需要安装项目依赖,推荐用 conda(环境管理工具):
# 克隆项目代码git clone https://github.com/test-time-training/ttt-video-dit.gitcd ttt-video-dit# 创建并激活虚拟环境conda env create -f environment.yamlconda activate ttt-video# 安装核心组件(TTT-MLP kernel,需要CUDA 12.3+和gcc11+)git submodule update --init --recursivecd ttt-tk && python setup.py install
准备 "原材料":预训练模型
TTT-Video 需要基于 CogVideoX 的预训练权重进行微调,需要下载这些文件:
VAE 和 T5 编码器:按照CogVideoX 官方指南获取
https://github.com/zai-org/CogVideo/blob/main/sat/README.md扩散模型权重:从HuggingFace下载两个
safetensors文件(注意选 5B 版本,不是 2B)https://huggingface.co/zai-org/CogVideoX-5b/tree/main/transformer生成视频:输入文字,输出画面
准备好后,就可以用sample.py脚本生成视频了,只需提供文字描述就可以
https://github.com/test-time-training/ttt-video-dit