对谈 Macaron 创始人陈锴杰:RL + Memory 让 Agent 成为用户专属的“哆啦 A 梦”|Best Minds

嘉宾:陈锴杰
访谈:Cage
编辑:Haozhen
随着 ChatGPT 加入 memory 功能,ChatGPT 的用户粘性进一步增强。在此基础上,Agent 的开发也进入了更加成熟的阶段:过去大家主要依赖 prompting,只能构建基础的 Agent,如今通过 RL 和 memory 开发者可以开发出 Agentic 能力明显更强的 Agent。
这意味着 AI 的角色正在发生有趣的转变:AI 不再是仅仅帮你写代码、做 PPT 的助手,更有潜力成为一个真正懂你的生活伙伴,可以更加个性化地完成日常任务。
为了更好了解这一趋势,我们访谈了 Macaron 创始人陈锴杰,锴杰分享了将 Memory 当作一种智能能力进行训练的经验,也强调了 RL 在 Agent 开发中的重要性。
Macaron 的产品最近引发了很多争议和讨论,锴杰坦言,如果满分是 100 分,自己只会给产品打 7-8 分,产品还有很大的提升空间,他期待未来的 Agent 能成为用户专属的多啦 A 梦,既是有趣的伙伴,又能随时创造实用工具:
• Multi-agent 系统可以将 Memory Agent 和 Coding agent 分开训练,从而实现对 Agent 情商和智商的平衡;
• 训练 Agent Memory 时,要把 Memory 当作方法,而不是目的。机器与人的 Memory 需要拟合、对齐;
• All-Sync RL 技术能帮助 Agent 开发者加快训练速度;
• RL infra 很难像云服务一样标准化,难点在于必须要基于真实用户反馈训练模型,最后再部署模型;
• 不同的生活场景叠加会给 Agent 带来更大的商业价值。
......
01.
更懂用户的专属 LLM 是未来趋势
海外独角兽:请锴杰先做一个自我介绍。
陈锴杰:我毕业于杜克大学机械工程系人机交互方向,过去有几段创业经历,现在是 Macaron 创始人。在成立 Macaron 以前,我曾创立 MidReal,这是一个互动故事的平台,累计有 300 万海外用户。我们在上上周刚刚发布了全新的产品 Macaron。
Macaron 产品功能图
海外独角兽:为什么决定做 Macaron?为什么特别强调 Personal 这类非生产力的方向?
陈锴杰:Macaron 是一个 Personal Agent。当时有这个想法,是源于我们对 MidReal 的观察。我们称 MidReal 是一个 “Fantasy World”,用户进入 MidReal 之后,可以写下自己的想法,并以多模态互动的方式沉浸到一个十几万字甚至二十万字的小说里。
MidReal 这个产品做了一年之后,我们在很多用户访谈里发现用户有一个共同的现象:大家会觉得在这个幻想世界里沉浸很快乐,但是一旦回到现实世界就会感觉有一些空虚乏味,甚至有一些割裂。因此也许可以更进一步,往用户的衣食住行、真实生活靠近,而不仅仅停留在幻想世界。
同时,在 2025 年初看到一个很明显的趋势:很多 AI 在生产力方向已经有很好的应用,比如帮你做 PPT、写代码、写报告,但在个人生活场景里,渗透依然很差。比如你让一个 AI 规划一下下周吃哪些餐厅,它通常会给一个正确但没什么用的回答。因为它不了解你究竟有什么饮食偏好,家里有几个人,和谁一起吃饭,有没有过敏的情况。它也很难理解这些背景。
所以一个更懂你、能服务你生活的 Personal Agent 才是时代在呼唤的东西。也是基于这个背景,定义了 Macaron 这个产品。
海外独角兽:和别的通用 Agent 相比,Macaron 的差别是什么?它是真的解决生活化任务,而不是为了某一些生产力导向的效率或者工作任务?
陈锴杰:可以这么理解。Macaron 有两个非常大的特点:
• Memory 强:比如你要它帮你规划下周的饮食,它必须非常了解你,所以需要有很强的记忆能力。
• 有用:在 Macaron 里,它能帮你定制小工具,我们称之为 Sub Agent。这些小工具可以是饮食记录(拍一张食物照片,它能帮你换算卡路里)、健身日志、心情日记、家庭财务管理、学业规划等等。
我会把它比作私人生活管家。它既是你的营养师,也是你的健身教练、网球老师、英语老师、日语老师。它是一个能真正帮助你生活的朋友。
海外独角兽:最近我们观察到,ChatGPT 加入 Memory 后用户粘性明显提高了。很多团队也在做基于 Memory 的 Agent infra。在你看来,什么是好的 Agent Memory?Macaron 的记忆又比别人好在哪里?
GPT更新 Memory 功能
陈锴杰:我们对 Memory 的理解可能稍微不同。我们认为:Memory 不是一个目的,而是一个方法。记住一个东西的目的不是“记住”本身,毕竟这不是考试,目的是更好地帮助用户。
比如用户忘了下个月朋友的生日,agent 能主动提醒;用户考虑旅行时,agent 能记得他提到的偏好:喜欢什么酒店、什么旅行方式、去过哪些地方。目标是更好地服务,而不是单纯记忆。
今天很多 Memory 之所以不好用,问题就在于把“记住”当成了目的。但如果把记住当作手段,目标是更好地服务用户,那训练 Memory 的方式就不一样了。
训练 memory 其实跟 Reasoning 是非常相似的。Reasoning 是一个最典型的手段,中间具体怎么做的并不重要,只要最后能给出标准答案,提高正确率就好。所以,今年年初,Macaron 就开始做 Memory 强化学习。我们可能是最早在 671B 模型级别上做 Memory 强化学习的团队之一。
做法是:用两个 Memory token 包裹住一段 Memory,优化目标不是“记住了什么”,而是能不能在具体 case 里回答好问题。在训练中,模型会不断演化、压缩,甚至丢弃一些信息,形成一个不断进化的 Memory 区块,随着聊天自动调整,最后给出更好的回答。
海外独角兽:你们把 Memory 直接当成了一种智能能力,就像 Reasoning 一样,专门去做了训练和强化学习。在 Reasoning 数据中,我们可以把过程解法打包成 Reasoning token,最后得出答案。那么在 Memory 里,Memory token 里具体是什么?
陈锴杰:在 Reasoning 训练初期,用的是一些 CoT 数据,后期其实就不需要特意做数据规划了。Memory 也类似:一开始我们可以用 RAG、prompt 机制、context engineering 做冷启动,比如用写代码、做数学题。但最终的训练还是在聊天应用里完成的。
在聊天中,Macaron 会逐渐记住,比如我的饮食偏好是什么;家里有几岁的父亲、母亲、孩子;他们分别有什么特点。这些偏好会被写进 Memory。看上去和今天的 Memory 总结有点像,都是用提示词的方式,但不一样的是:Macaron 会自己决定总结什么、压缩什么,哪些信息多放一点,哪些少放一点。
我们发现一个现象:当用户特别强调某个信息时,Macaron 就更着重去记录这个信息。这其实是机器的 Memory 和人的 Memory 在拟合、对齐。人类聊天时,也会自己记一些重点。人的记忆本身就像一个不断进化的小区块:我们不断放入、更新,比如前十分钟聊了什么,逐渐形成记忆。最后训练出来的 Memory,就像把机器的记忆和人的记忆对齐了:
• 记住的东西差不多时,你会觉得 Macaron 很懂你;
• 还能记一些你没特别强调的,那你会觉得 Macaron 很棒;
• 没有在意的部分,Macaron 反而会遗忘。
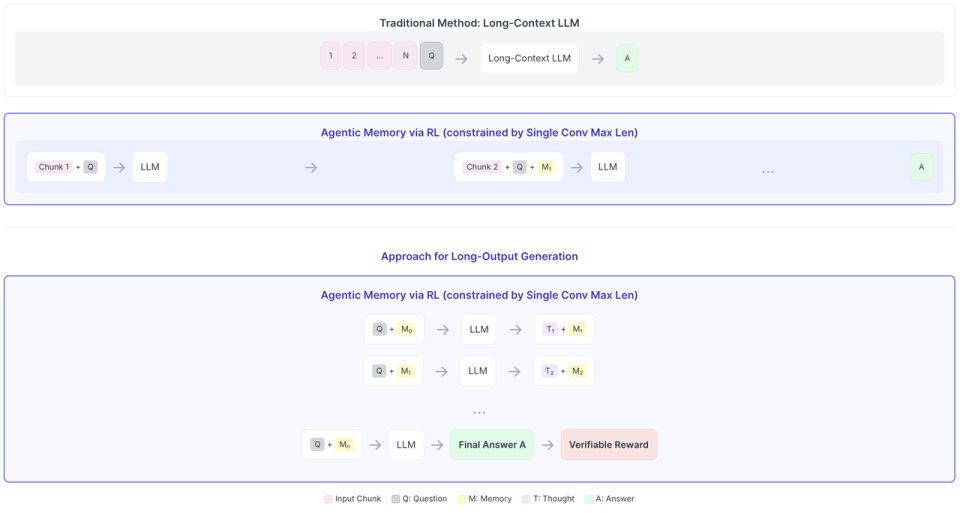
Macaron Agentic Memory:
通过 RL 进行训练,适应于长文本输出
02.
Macaron 最好的类比是哆啦 A 梦
海外独角兽:对于训练来说,冷启动比较好理解;那对于用户早期使用呢?比如大家第一次用 Macaron 的时候,这时没有上下文。但我们希望它是“非常懂我的 Agent”。那怎么让用户第一天就能感受到这种体验?
陈锴杰:刚上线的时候,Macaron 还没有把这个事情做好,让用户立刻理解 Macaron 在做什么,并且能和它交朋友,这是有一个学习的过程。
除了那些玩过 vibe coding 或者很熟悉 AI 的用户,大部分人其实只知道 AI 能聊天,但并不知道 AI 还能帮他们做小工具。所以我们发现,上线一周之后,很多用户甚至都没有发现 Macaron 可以帮他们做小工具,这是我们急需解决的问题。
现在的冷启动流程大概会是这样的:
• 人格测试:用户会先回答几个问题,就像 MBTI 一样。我们的观察是,大家都喜欢做人格测试,都想知道自己是什么样的人、和什么样的人能匹配。用户在这一步通常是愉快的。
• 匹配专属 Macaron:测试结束后,用户会得到一个属于自己的、有“颜色”和“性格”的 Macaron。
• 见面礼:第一次见面时,Macaron 会送你三个有趣的小工具,作为见面礼,并问你:“你觉得它们好用吗?” 同时它还会说:“如果你觉得这些不好也没关系,可以专门为你定制一个新的小工具。” ——这样用户立刻明白:原来 Macaron 是能做小工具的。
• 从兴趣入手对话:在测试里我们也会问到一些兴趣和性格,比如用户选择了“户外运动”,那见面后 Macaron 就会问:“你是不是喜欢徒步,或者玩飞盘?最近有出去玩吗?接下来放假打算去哪旅行?” 这样就快速和用户开启话题,从兴趣点进入聊天。
通过这一系列设计,用户会感觉 Macaron 是一个能聊得来的朋友。一旦成为朋友,后面无论是解决生活中的小困扰、烦心事,还是探索新的兴趣(比如学网球、游泳),都能自然展开。
海外独角兽:这个过程有点像哆啦 A 梦。一开始见面,它会从口袋里掏出几个小工具,对我说“这个很好用,你来试试”。
陈锴杰:哆啦 A 梦可能是最相似的比喻了。我认为未来的 AI 不会再被比作“物品”或者“工具”。可能 ChatGPT 会被比作 Jarvis 或者其他角色,但 Macaron 最好的类比就是哆啦 A 梦:
• 哆啦 A 梦首先是大雄的朋友。
• 只有当大雄遇到问题时,哆啦 A 梦才会从口袋里掏出一个道具,尝试帮他解决。
• 有时候道具不完美,甚至坏掉,但大雄还是会原谅哆啦 A 梦,因为他们是朋友。
用户可能不需要世界上最聪明的人来做你的朋友。用户更需要的是一个能持续陪伴他、关心他的人。这就是我对 Macaron 的定位。你不会因为有了一个新朋友,就放弃陪伴已久的老朋友。
海外独角兽:Macaron 有两个定位:一个是朋友,一个是助理。GPT-5 发布的时候,也有类似的争论:当一个模型智商上升时,情商可能会下降,它反而不那么像朋友了。至少从 GPT-4o 到 5 的过程中,很多用户都反馈过这种体验。那 Macaron 在“成为朋友”和“成为一个好的助理”之间,怎么平衡?
陈锴杰:Macaron 做了一个天然的区分。和用户对话、管理记忆和偏好的模型,和帮用户做小工具的 Coding Agent,其实是两个不同的 Agent。它们之间有一个互通的协议,但职能是分开的:
• 和用户交互的那个 Memory Agent,就是用户的朋友。
• 而帮用户写小程序的 Coding Agent,只需要专注把工具写好。
用户的所有偏好,比如饮食习惯、健身时是否膝关节受伤、需要注意什么细节,这些信息都会由“朋友”这个 Agent 传递给 Coding Agent。
我希望的是:和用户聊天的这个 Agent 不是一个冷冰冰的助手,而是有温度的对话者。这样用户更容易接受它、信任它。而信任建立之后,用户才会愿意提供更多上下文信息,Agent 才能更好地服务用户。
海外独角兽:所以其实 Macaron 是用 multi-Agent 的思路来平衡:一个高情商的 Agent 加上一个高智商(或者说动手能力强)的 Agent,共同来保证用户体验。
陈锴杰:是的,高情商和高智商的优化方向完全不一样。这两个 Agent 都是在我们自己的百卡集群上做的端到端强化学习训练。但训练目标不同:
• “朋友”Agent 的目标:更懂你,记住更多东西;在聊天过程中更好地服务你;并且用 Router 把不同需求(无论是烦恼还是好奇心)合理分配给其他需要调用的 Agent。
• Coding Agent 的目标:我们有 100-200 个真实的生活小工具的案例(这些案例是从社区用户反馈中不断提炼的)。Coding Agent 的目标就是把这 200 个案例都写好,做到功能完整、交互流畅、视觉好看、用户喜欢。
所以我们必须把这两类优化目标完全分开,各自训练。这样子合起来之后,体验才会更好。
海外独角兽:现在 Macaron 满分 100 分,你会打几分?
陈锴杰:大概就七八分。
我对它的期待很远:如果有一天能服务 1 亿人,我可能会给到 85 分。今天还是一个试探,交互、外部对接、Coding Agent、记忆未来都可能有重大的变化。比如手机厂商入局做“大 Agent”,社区未来占比多少等,这些问题都还没解决。今天只是最早的状态。
03.
Sub Agent 进化论是什么?
海外独角兽:锴杰描述的过程让我想到几个有趣产品的影子:小红书、Notion 和多邻国。从小红书的启发来看,Macaron 的一些功能也是社区驱动的,那未来你们打算从哪里找到这种网络效应?
陈锴杰:我其实是有这样的想象。Macaron 不只是你的私人管家,它还是一个“生活方式分享的平台”。
比如说瑜伽和跑步都是常见的活动,但它们并不仅仅是动作练习,更多的是一种生活方式。比如瑜伽更强调静心、流畅的状态。我认为这种生活方式可以被固化、凝聚成一个 Agent。
拿我自己来说,我特别喜欢喝水和运动。和我见过面的朋友都知道,我随身会带一个 1.5 升的大水壶,一天要喝两瓶。所以我的 Agent 里就有饮水和运动相关的。这就是我的生活方式,我也希望能把这样的方式分享出去,无论是在 Macaron 的社区,还是小红书、Instagram 这样的社交平台。如果有人想尝试这样的生活方式,他就可以把这个 Agent 导入到自己的 Macaron 里。这就意味着他也能拥有和我一样的习惯。
再举个例子:我的联合创始人特别喜欢红酒,而我完全不懂。于是他做了一个红酒的 Sub Agent。这个 Agent 的能力是:你只要拍一瓶酒,它就能告诉你年份、酒庄、价格,以及最佳保存方式和最适合的搭配食物。对我来说,这就是一个入门方式。后来我甚至能在社区里看到大家分享的红酒体验,这个口感如何、适合配什么。
未来,我甚至希望请一个网球冠军来做一个网球训练的 Sub Agent,然后在社区里分发。相信会有很多人喜欢。所以我对 Macaron 社区的畅想是:会有很多生活方式的“领袖”出现。
和之前的小红书、抖音这些平台相比,Macaron 有一个很大的不同:
• 在抖音或小红书,创作者需要一定的创作能力,比如写文章、拍视频、发美图。
• 而在 Macaron,用户几乎不需要创作能力。只要一两句话,就能生成一个小工具。
所以在 Macaron,创作者的本质不是“会写内容”,而是是否有独特的生活方式。这意味着:哪怕有人喜欢“宅在床上一整天”,这种方式也能被固化成一个 Sub Agent,被别人使用和分享。生活方式本身就是内容。它不一定精彩、不一定充实,但它足够独特,分享出来之后,就能给别人带来启发。这就是我希望 Macaron 的社区能成为的样子:一个生活方式的分享平台。
海外独角兽:如果未来我和 Macaron 说,我也想做一个“宅在床上一天”的人,会不会把其他用户做过的类似 Sub Agent 推荐给我?
陈锴杰:这是一个非常好的想法,也是我们接下来会发展的方向。
今天所有的 Sub Agent 都是 Coding Agent 从零开始一行一行代码写出来的。这种方式并不是最优。未来我们会做调整:如果已经有人做过一个很精彩的案例,并且被很多人使用,Macaron 就会基于这个现有案例来提供给新的用户。同时还会问用户,要不要在上面做一些修改,让 Agent 变得更个性化。这样,Sub Agent 就会不断地衍生、演化,形成一种 “Sub Agent 进化论”。
比如,一个 Sub Agent 被调用得多,就可能在它之上长出新的分支;在新的 Sub Agent 里,如果有的使用率更高,它又会继续被进化;整个体系就像一棵树一样,不断往下发展。
和苹果 App Store 不同的是:
• App Store 的开发和反馈是相互独立的,每个开发团队独立开发,每个用户反馈独立分散。
• 在 Macaron,所有 Sub Agent 都是由 Coding Agent 写的,生产和反馈都不是独立的。
这意味着在 Macaron 中,如果用户对一个 Sub Agent 提了反馈,下一次 Coding Agent 写的工具就会做出调整。用户反馈也能跨场景关联起来,形成真正的强化学习反馈回路。主 agent 在分发的时候可以把不同的应用分发给同一个人,或者把同应用分发给不同的人。这个时候反馈之间,我们可以去创建关联。
结果会是,Macaron 团队能真正用 gpu 上的强化学习算法把所有反馈作为奖励函数,因为数据的生产和反馈都不是相互独立的。收集到反馈数据作为强化学习的方式,就能不断把 agent 和 sub agent 的能力往上解锁,做更多场景,用更好的交互服务更多的用户。我觉得是有这样的进化趋势的。
海外独角兽:Macaron 未来可能是一个慢慢演化、扩散的社区,有点像一个双边平台:一边是 Coding Agent 做出的小工具,一边是想找到有趣朋友的用户。你们则把这两边缝合在一起。这就是 Macaron 想传达的思考吗?
陈锴杰:是的。比如 Pixel 新手机发布时,也在强调能“帮助生活”;ChatGPT 的 Query 请求里,关于生活的内容也越来越多。AI 不再只是生产力工具,而是逐渐渗透到生活场景。
所以 Macaron 特别的地方就在于:它想构建一个新的分发和平台,让大家分享有趣的生活方式。
海外独角兽:Notion 这家公司有两个特质和锴杰描述的愿景有点像:第一是它一开始就做了 memory 和 database,后面才能做跨页面的关系,成为用户的“第二大脑”;第二是它有一个模板的生态,社区里有人拿 Notion 的各种配置去叠加内容,甚至靠它做创作经济、分享生活方式。如果真的要做这样一个 AI 时代的现象级产品,既有 memory,又有网络效应,最大的挑战会是什么?
陈锴杰:我觉得在不同层次看,会有不同层次的挑战。
最大的、最抽象的层次是团队。如果把团队当作一个强化学习(RL)的算法来看的话,它需要根据社区氛围、人的变化、案例的变化,不断调整社区的运营策略;在服务每个个体用户的时候,根据新的需求做新的强化学习训练,让 Coding Agent 能写出更好的 Sub Agent。
比如今天在 Macaron 里说“做《黑神话:悟空》第二部”,这肯定写不出来;你说“做一个 3D 赛车游戏”,其实也做不出来。但如果这样的 case 积累多了,下个月重新做 RL 训练,可能就可以把 3D 赛车游戏做出来。
所以在用户个人反馈这一侧,Macaron 会不断做强化;同时还要修改怎么向市场传递策略。一开始可能去找开学的人群(9 月),他们会遇到选课、社团、交新朋友等问题,让他们第一时间想到 Macaron。对我们来说,首先是要和市场有一个这样的“强化过程”。
再往里深究,怎么同时把用户服务好、把社区建立起来,有个关键要点是记忆系统的设计。本质上 Macaron 还是一个 Personal Agent,要把生活服务好。记忆不仅仅是在对话里记用户的偏好,还要把这些偏好传递到每个 Sub Agent 里,Sub agent 与 Sub agent 之间也要相互理解。
• 例如用户今天开始做新的力量训练,饮食规划的 Sub Agent 就要知道用户需要更多蛋白质。
• 当用户做完饮食计划和健身训练,聊天过程里 Sub Agent 又知道了新的信息,就应该基于这些新信息继续反馈和调整。
“记忆传递”是一个比较复杂的机制。为实现这个效果,我们设计 Macaron 的时候甚至摒弃了原来的数据库系统,既没有用关系型数据库,也没有用非关系型数据库。Macaron 的数据库结构的目标是,让所有 Sub Agent 共享同一份、关于你的个人数据。当然这些个人数据被存放在一个加密的地方,我们 Macaron 非常关注隐私。
在这个架构下,每一个 Sub Agent 有点像“生成式 UI”,可能比 Chat 更好的 UI;同时它像每一个 Chat 一样都能知道你生活里发生了什么、你记录了什么信息。这部分的记忆工程 + 模型训练,是让 Personal Agent 真正“有用、能帮助你”的关键一步。我们还在努力继续去实现,有非常多的工作没做完。这个再加上前面聊到的社区,Macaron 有机会实现类似 Notion 的产品。当然我们的团队也要像 RL 一样,不断和环境接触、迭代。
04.
RL infra 很难像云服务一样标准化
海外独角兽:RL 是不是现在做 Agent 最重要的元素?你在实际做的过程中,会觉得在哪一方面的提升最明显、最需要深入?
陈锴杰:大部分公司是做不了 RL 的。我们最早在 70B 的模型上做 RL,那时模型在写小说的记忆能力不够好,必须要通过增强才能写出十万、二十万字。后来我们团队继续探索。今年在 r1 的范式之后,特别是 deepseek 的 0528 版本之后,我们把 RL 从 70B 迁移到了 671 B 级别的模型上。
在国内能自己做 671 B 级别模型 RL 的团队非常少,可能不到 5 个,包括很多能做 Pre-train 的团队,比如说智谱,也没办法做 671 B 级别的稠密模型的 RL。很多公司在做 RL 的时候,也会停留在几十 B 到 200B 这个范畴,200 B 是一个分水岭。因为 200 B 以内还能放在一个 GPU node 里训练;更大就必须做专家并行、管线并行,把训练与推理分布到不同机器上同步跑。
所以,市面上大部分 Agent 公司会说 RL 不重要,因为它们做不了,也很难去想这个问题。之前大家已经看到 Pre-train 的边际效益在递减了,我们已经进入“智能提升的下半场”,RL 是智能提升下半场的核心。RL 对场景的要求很强,很难有一个“超通用”的 RL 场景,让一个超通用 Agent 在所有能力上同时提升。比如 Anthropic 就是在 coding 领域做了很多 RL,所以它的代码质量比 GPT-5 明显更好。其他的公司会有不同的 RL 的场景去优化。
能够领先的公司必须在选定的场景里面有真实的模型,生成真实的内容,获得真实的用户数据反馈,做真实的修改,去迭代它的 RL 的效果。所以如果要做 RL,模型和场景是必须配套的。今天想做一个全能的模型已经很难了。但在特定的场景,比如说 personal agent 里做 RL,Macaron 写出来的东西可能就可以比市面上其他所有的模型都好。在这个特定场景上,今天看 RL 的价值就是 RL 能够在一个场景上推到智能的最上限。而且 RL 必须是在 700B 的模型上。如果是在 200B 的模型上,目前训练结果都很难迈过 AGI 的门槛。
所以如果以这样的市场定位,RL 就非常重要,开发者需要不断去解锁智能的上限。

Macaron 用 RL 优化 Memory
Manus AI 的重点是在 Context engineering,它们的想法是这样可以提高迭代的速度,可能两三天就可以迭代一个版本出来。我很相信产品一定要迭代的够快,和用户一起成长。但其实 RL 也可以做到这一点。
Macaron 提出了一个方法,叫 all-sync rl(全同步),把训练时间从“按周”压到“按天”,大约 30 小时能完成一次有意义的 RL。也就是说,我们的 RL 也能以“天”为单位迭代。如果用这样 all-sync 的方式去做应用,既抓智能上限,又跟得上产品节奏。对 Macaron 来说,RL 是极度重要的。

Macaron all-sync 模式下 GPU 优化消耗低
海外独角兽:all-sync rl 这个方法是不是有点像:比如抖音白天收集用户反馈,晚上微调,第二天模型就变得更懂用户?Macaron 是不是也可以通过 RL 达到这种节奏?
陈锴杰:all-sync rl 是训练侧的优化算法,不是推理侧。训练过程中有两部分:training(训练)和 inference(推理);训练时模型也在不断推理、演化,两者交替会产生 GPU bubble,本质是浪费。很多优化方法的目标就是把这个“泡泡”挤掉。
我们做的是“全同步(all-sync)”:通过通信与模型压缩,更好地调度,让训练与推理同时进行,效率提升好几倍。原来 512 张卡的训练,我们可能只需要 48 张卡就能完成初步训练。
至于 online / on-policy,on-policy 今天就能实现;online 未来是可能的。两个对用户交互系统都很重要。
• on-policy:标准定义是训练数据完全由模型自己生成,比如 Macaron 的 sub agent 全部由 coding agent 自己写,优化方向清晰、下降更稳定。
• online:指模型与用户的反馈实时联动,不断在线上演进。

On-Policy、All Async、All Sync RL 的功能
海外独角兽:RL 能让小模型做到原本只有大模型才能做的事。你觉得两三年、三五年看,RL 还是需要大模型吗?会不会走向“民主化”,让更多 AI 开发者做 RL?
陈锴杰:未来可能会有 RL infra 公司,让大家都能用 RL。但有几点需要注意:
• 模型不能太小。如果是具体的小场景,可以直接调大模型,可能比去训练一个 20–70B 加上 RL 更经济;除非你需要端侧或本地部署,那 10B、20B、30B 这种级别,加上 RL,可能有特殊效果;
• 非端侧的大场景,我认为还是在 “600–1000 这个级别”更像 AGI 级别的效果,对场景的优化更大。
RL infra 的难点在于必须要真实用户反馈,再训练模型,最后再部署模型。很难像今天的云服务一样标准化。很多时候训练数据量不够/清洗不好,就没有效果;需要很深入地分析 + 做几十个实验才能收敛。我们没有见过一次就跑通的 RL。所以这种服务到底怎么定价,多重还是 200 万美元起一单,怎么证明价值,都是挑战。对 Macaron 来说,能 in-house 做,空间更大、更灵活。
海外独角兽:最近在硅谷观察到 RL infra 的公司非常多,至少十到二十家。一般有两类:
• 更像做数据的观察与服务,帮 Agent 开发者把 trajectory(轨迹)尽可能标好;
• 直接做环境,比如给 coding agent 一个能产出 CRM / IDE 的环境,更自动化、更可扩展。
你觉得 RL 有哪些特别适合或不适合的任务?对应用开发者真正带来的机会是什么?
陈锴杰:Macaron 今天非常聚焦在记忆和写 sub agent 这两个场景,训练效果很明显。我自身的经验是:在一个场景里做到 50–80 分,靠工程 + 更复杂的 context engineering 基本可以;80–85 分也能撑到。但从 85 往 95 分走,RL 的提升最强烈。这时继续堆 Context engineering 会出现“打地鼠”:流程很复杂,修好这个问题,另一边又可能出现新的问题,导致系统难维护。所以通常在最后阶段切换到 RL。
如果环境可定义,大部分任务都可以做 RL:写法律文书、做病人调查等都可以。但如果环境没有定义好,早期堆了太多 context engineering,就会有很多技术需要补充,需要拆掉、端到端重构。所以,真实环境很重要。
海外独角兽:我是个 DOTA 玩家,看着五个 DOTA NPC 冲过来的时候,我觉得它和人很不一样。而且它的那套策略在 AI 的程度下可以做得比人更好。在那种有明确输赢的场景下,RL 已经能做到 100 分甚至以上,就是超人类。你觉得未来有没有机会出现这种“比人更好的地方”?
陈锴杰:问“比人更好的地方”在哪其实更像是在问:我的 Agent 究竟等于多少个人在思考和做这件事情。
• 如果是记忆这个方向,Macaron 最后肯定会超人,它会比你的朋友、甚至比你的家人都更了解你,这是肯定会发生的。
• 从 coding agent 这个方面,我们可能最后会感受到它等于多少人效。它很难说做到“写出一个微信、一个抖音、甚至一个 ChatGPT”这种没有上限的目标,并不是不行,但那已经脱离了 Macaron 今天的发展目标。最后更像是:能不能写出来一个和应用市场上“100 万评分的番茄闹钟”一样好用、但又根据你的个性化特征重新定制的番茄闹钟。Macaron 可能等于:三个前端 + 三个后端,3 万月薪(深圳),一起干两个月的效果。它还是一个小团队能做出来的东西,可以非常精致,也非常符合用户的需要。我觉得这是它最后能达到的状态。
海外独角兽:我就经常忘记朋友的生日,Macaron 肯定比大部分像我这样的朋友要好很多。同时,普通用户平时能请到的 IT 外包帮他解决任务是很有限的。这时候 Macaron 能做到的,就比普通用户能接触到的解决方法要好很多。
陈锴杰:是的。而且 Macaron 的 Coding Agent 和 Anthropic 的 Coding Agent 需要优化的方向也很不一样。Anthropic 是注重复杂的大型编程场景里面去做,是一个工程场景。而 Macaron 更注重小的完整功能,并确保一次就能运行。Macaron 可以犯一些错误,但是它生成的东西一定要能打开,用户要在第一次打开就能看到 Macaron 帮它做好的项目的呈现。
05.
适合个人的小应用是真实需求
海外独角兽:发布 Macaron 的时候你发了条朋友圈,说之前是多邻国的用户,但在发布 Macaron 之后就把多邻国的 subscription 停掉了,因为你觉得 Macaron 已经能做一个很好的外语学习助手了。所以,比较好奇 Macaron 在和社区、用户做强化学习的过程中,未来是计划在一些垂直领域继续深入,还是先做一个更通用的 Personal Agent?这当中会怎么权衡?
陈锴杰:我们上线一周多之后,有 7000 多个用户做了一万多个大家不同的小应用。在这些小应用当中,有一些分类大类开始浮现。这跟我们的前期策略有关,前两周大家在使用时会有个感觉:“Macaron 什么都答应你、什么都想做,但做出来什么都不太行。” 这正是我面临的一个比较沉重的二选一难题:
1. 只答应我知道能做好的事,把需求范围限制在我能做好的事情里;
2. 把口子敞开。坏处是做不好,好处是我能够收集到用户真实的意愿分布。
我选择后者,这样能看到真实的需求。下一步就能看哪一些做得好、哪一些做得不好,在需求与 Coding Agent 的供给之间画一个交集,作为第一步强化的方向。现在这一万多个小应用里,收敛很明显的方向是 Tracker / Planner(生活的记录与规划),比如:
• 饮食、健身;
• 心情日记、游戏记录、升学进展、作品集整理;
• 有人记录“拉屎的颜色和形状”;
• 日本区很多用户喜欢做钢琴谱、吉他谱的生成(可能和当地音乐市场定价有关)。
Macaron 会把这些记录与规划的案例放进下一步 RL 训练,把它们做得更好。聊天侧会适度把需求往里缩,但不会缩得很死,因为还要看到下一步大家的真实需求点落在哪里。AI 发展很快,我相信可以一步步解锁更多需求,把边界往外推。
我认为专注某个垂直领域也是和用户一起动态探索的过程,有点像小红书最早做海外购物,后来拓展美妆、露营。对 Macaron 而言会更快,因为生产都是 Macaron 自己,不用去调一个外部生态。把 Agent 能力提升上去就行。
Macaron 部分应用功能展示
海外独角兽:整个社区对 Macaron 的评价很有意思,有好的,也有一些争议。我挑了两类:
1. 用户觉得在 cloud 优化方向上,做的小程序太慢,或者用不起来;
2. 用户觉得 Macaron 有一种妈感,比如总是忍不住想要帮忙。
你觉得这种反馈符合你们预期吗?接下来会怎么处理?
陈锴杰:其实是非常符合预期的。因为 Macaron 一开始的策略就是广泛收集用户需求的分布,同时看看模型在哪些 case 上会失败。在 beta 测试时,我们自己很难测出所有分布,所以其实是做好了被骂的准备的。也确实如愿以偿——被骂了。但我完全理解。
用户的评论方向,基本取决于第一个小应用:如果第一个做出来正好在模型能力范围内,他甚至会很惊讶、很感叹,有的用户甚至哭了;如果第一个应用做失败了,比如链接点不了,就会对 vibe coding 失去信心,觉得今天 AI 做不到。
所以我非常感谢早期用户的信任,愿意先来尝试。解决的方式其实很清晰:
• 先找到供给与需求的交集,把能做好的范围收拢一些;
• 我们在 8 月 29 日上线了更新,提升速度和稳定性;
• 用户反馈里最强烈的需求,比如 tracker / planner(记录与规划) 类案例,就会在下一步 RL 训练里强化。
我觉得模型的解锁速度很快,半年、一年之后,一定会和今天大不一样。我们现在也在测试一些新的生成能力,会越来越强。
至于“妈感”,Macaron 还需要继续训练聊天的要点。在之前的虚拟角色(比如 MidReal)里,我们对剧情对话有一定理解,但在“哆啦 A 梦式”的日常陪伴聊天上,还有提升空间。大家可以在 8 月 29 日后的版本看到一些不同。
海外独角兽:和用户聊天时,有没有一些特别让你惊喜的 use case?
陈锴杰:有几个让我很震惊。
• 高尔夫动作分析:昨天有个朋友想学打高尔夫,做了一个练习状态记录。他说不要静态的记录,要做“动作视频分析”,看能不能提高准确度。我当时觉得这个 case 一定会失败,结果 Macaron 真的做出来了:用户上传视频后,它能分析动作,给出改进建议。这是我们没有专门强化过的 case,但它能从已有分布扩展出来,我觉得非常酷。
• 搬家规划:有一位 40 多岁的女性用户,最近要搬去美国的新城市。她用 Macaron 规划了新生活:去哪里玩、怎么安排日程、怎么做心情瑜伽和冥想训练。看到这个我很开心。生活中有变化的人群都特别需要一个帮手,比如开学、搬家、养宠物、添小孩,
• 家庭菜谱管理:有用户做了一个家庭菜谱 app,爷爷奶奶、儿子女儿口味都不一样。他设计了一个像大众点评一样的功能,让家人给家里的菜打分。系统能根据当天谁在家自动筛选出最合适的菜,并整理成食材和做法。这个需求非常家庭化,也很有意思。
这些 case 在应用商店里很难找到现成的解决方案,因为它们太个性化了。很多人会问:“是不是要有一个比应用商店好十倍的应用,才能让用户迁移到 Macaron?”我的答案是:完全不是。有时只是做一个只属于自己或一小撮人的工具,但它完美符合个人需求。

Macaron 部分用户反馈
海外独角兽:这些应用以前只有市场足够大、有最大公约数时,才会有人去开发。就像 Sam Altman 或者 Dario Amodei 他们经常讲的愿景:有了模型智能之后,应用会像自来水一样,打开自来水龙头它就流出来了。在生活当中,Macaron 就是那个自来水龙头,覆盖了生活中最后一公里的场景。
陈锴杰:是的,写代码现在真的像自来水一样,成本也差不多。这样大家能做出更符合自己心意的东西。它和过去不一样,过去是别人给你做;现在即使是普通用户,也能造出比别人更合心意的工具。未来有很大的潜力。
06.
相比工作场景,生活场景叠加会带来更大价值
海外独角兽:回到商业模式。长期看,你们会考虑做成一个新时代的 App Store 吗?还是想得更不一样一些?
陈锴杰:从真实来讲,Macaron 也不是一个 App Store。首先它是用户的 Personal Agent。Personal Agent 能解锁的商业潜力已经很大。
生活和工作的差别是:生活场景叠加起来会带来更大的价值;但工作场景,比如说一个项目和另一个项目,随意把项目间的 context 叠加起来,可能会产生悲剧。当 Macaron 知道用户最近在做什么运动、喜欢吃什么,给用户的健身方案就不一样;用户出去旅行,给用户定的目的地、酒店就不一样;给朋友的礼物、搬家的布置也会不一样。这些场景叠加之后,效果更大,而不是单点极致。
商业上,在这里你可以订机票、买东西、点外卖;也可以让它当健身教练、营养师。这块潜力已经很大。
我不希望 Macaron 出现所谓的开发者绞尽脑汁去想,别人会需要一个什么 subagent,然后很用心的不断去修改定制,最后做了一个 subagent 给大家。我更希望是人有自己的生活方式,他本身就是这样一个人,他在分享自己的时候,也把自己的故事分享给大家。这才符合我对 Macaron 的社区的想象,健康的社区生态和态度对是产品很重要的。产品创始人在守护什么,会决定产品最后在市场的位置以及能走多远。所以,我希望去维护这样的调性——是“生活方式的分享”,而不是“创作与消费”。
海外独角兽:现在很多 Agent 都走偏订阅制的商业模式,本质上有点像 Office,为某一段时间的“生产力”付费。如果 Macaron 最后想做社区,是不是就不会走这条路?
陈锴杰:Macaron 现在还是订阅。订阅不一定不可取:你有一个“管家”,按月给他付工资是合理的。未来在社区里,当你的 Agent 被更多人分享和使用时,你也应该获得一些属于你的回报。此外,Personal Agent 部分也可以有广告或第三方接入。这里其实有很多商业模式的创新空间。
海外独角兽:从 MidReal 停止到打造 Macaron,这个转型的决策是怎么做的?大概花了多久?
陈锴杰:一方面是用户观察:用户在 MidReal 打造的虚拟世界里沉浸,但内心越来越矛盾。我们希望对真实生活有一些积极作用。另一方面,故事方向好像没在今天模型能力升级的最佳路径上,模型越来越会写代码,却越来越不会写故事(在 GPT-5 上感受尤其明显)。所以,如果在一个不是智能提升最快的路线上做事情,可能会有悖于今天 AI 时代的发展的规律。
对于服务生活,我 18 年从杜克休学创业做的第一件事情就是家庭智能机器人,也是和我今天的 cofounder 一起。我们两个对生活都有美好的想象和追求,包括在自己的生活里也有有趣的生活方式,所以我们想往服务生活的方向走一步。同时看到像 Claude code 这样能够实现真正更好代码能力的,像 Deepseek R1 这样能去做强化学习训练、同时也有很强代码能力的模型的出现。这几个因素放在一起,驱使我们从 MidReal 迁移到了一个新的愿景上。
海外独角兽:从 MidReal 到现在的 Macaron,你作为 founder,最大的思维变化和工作方式上有什么转变吗?
陈锴杰:以前会觉得,在一个小赛道做到前三名,就像 MidReal 那样,可能会有不错的市场地位,或者是一门好的生意。以前确实会这样想。但越做越发现,在小赛道上做到前三名意义并不大。我更想在 AI 浪潮里,去做一些走在前面、真正有意思的事情。所以现在的态度已经转变了:不是要在小赛道里做头部,而是要进入一个更大的赛道,在那里每个人都有机会。
Personal Agent 这个赛道很特别。未来会有很多人进来,它最后可能会像社交软件一样:在海外社交软件领域,有 Facebook 很大,但 Instagram 也还在,同时还有 Telegram、X、BeReal、Snapchat,每个平台的性格都不一样。
Personal Agent 也会是类似的:它像是你不同性格的朋友。你可以有一个很专业的朋友,也可以有一个很温暖的、甚至带点“妈感”的朋友。所以我希望切换到这样的模式下去做。虽然 Macaron 强调的是生活方式,但从工作节奏上看,其实团队已经进入了一种 “没有生活的生活方式” ,最近都在努力修复用户提出的各种问题,并快速迭代。
海外独角兽:听起来也很像强化学习:一个地方的奖励饱和了,就去找一个更陡峭的 reward 曲线。
陈锴杰:是的,追求的首先肯定不是财富,更像是一种生活方式。在原方向见顶后,我们选择切换到新方向。
海外独角兽:如果把 Personal Agent 对标 Facebook / Instagram / Telegram,ChatGPT 现在是在 Facebook 的位置吗?
陈锴杰:GPT 毫无疑问是 Facebook 的位置。它今天已经有 4 亿 DAU,是无法阻挡的增长,也是最大的明牌。很多原本不那么“冒险”的公司都在入局 OpenAI。它真的很强。
海外独角兽:那你们做 Macaron,Timing 上有偏早或偏晚?还是现在就是最好?
陈锴杰:时间点正好。
• 微观上,我们在 ChatGPT5 发布之后,Macaron 也被骂了很多(对我们来说反而是好事);
• 宏观上,我们是第一批 Personal Agent 上市的团队之一,能先占到用户心智。留给我的空间至少还有三到六个月。
我很难想象 ChatGPT 会很快调整产品形态来做这件事。GPT 虽然很大,也能处理一些 Personal 需求,但 GPT 不会像我们这样去做 Personal Agent,它可能离这个方向还是非常遥远的。如果它要过来这个赛道,不管从交互上还是从心智定位上,都要做比较大的产品的调整。
我倒是觉得竞争不会那么强烈,我有充足的信心,当 Macaron 建立自己的社区之后,Macaron 和 OpenAI 是会各自有一批用户的。甚至一个用户能够同时在手机上拥有我们两个应用,但是在不同的场合打开。如果用户每一次工作的时候就打开 ChatGPT 的话,我觉得用户很难回家之后再像朋友一样跟 GPT 聊聊天,这是有一点割裂或者人格分裂的。所以 Macaron 是可以和 GPT 并存、甚至去抗衡的。
海外独角兽:和巨头站在一起是很有勇气的事情。现在 ChatGPT 更像是占据了用户“同事”这个心智位置,站住了之后,一定会有一个新的心智的位置给包括 Macaron 在内的所有创业者打开。因为 Agent 领域很大,有人做通用的,有人做垂直的,有人做基础设施。你觉得有哪些方向被低估,哪些被高估?
陈锴杰:目前,很多小 Agent 基于大模型做一套工作流,其实并不成立,最后会被更大的 Agent 覆盖。比如 Personal Agent 一定会把“旅行规划”做好,因为它有你的衣食住行信息,大概率比单独做旅行的 Agent 更强。但在一些专业场景里,Agent 也会有巨大机会。
是的,写代码现在真的像自来水一样,成本也差不多。这样大家能做出更符合自己心意的东西。它和过去不一样,过去是别人给你做;现在即使是普通用户,也能造出比别人更合心意的工具。未来有很大的潜力。
排版:傅一诺

