Cloudflare 的 AI 新叙事:线上内容“做市商”,Agent 互联网流量基建

编译:Ivy
编辑:Siqi
Cloudflare($NET)是全球最大的 CDN 供应商,同时也提供一系列网络安全相关产品,最新市值已经达到 782 亿美元。Cloudflare 的业务和产品的演化、迭代是和互联网进化过程紧密联系在一起的,从简单的“云端防火墙”想法到今天线上流量关键基础设施的过程背后是整个互联网爆发、新需求不断涌现的过程。
当互联网时代经典的“搜索—分发—流量变现”开始被 AI Chatbots 颠覆,Google 选择通过 AI Mode、AI Overview “自我革命”,Cloudflare 则是试图定义新一代互联网内容经济,提出了 Pay-per-crawl。
“Pay-per-crawl(按爬取付费)”是 Cloudflare 今年 7 月推出的服务,在 Cloudflare 的 CEO Matthew Prince 看来,网站内容创作者被 AI 爬虫爬取内容的无奈只是表象,本质上是互联网的“免费爬取-流量变现”逻辑正在失效。
虽然“Pay-per-crawl”的商业模式不一定能跑通,但它背后反映的企业家精神很有趣,即使是近 800 亿美金市值的公司,仍然有初创公司的活力,永远站在科技前沿,不断思考新的商业机会。
在近期的一系列访谈中, Cloudflare 创始人及 CEO Matthew Prince 详细分享了Pay-per-crawl 背后的思考:
• Pay-per-crawl 可行的首要前提是对于所有 AI labs 来说,数据是模型能力不断向前的重要资源,Cloudflare 希望为内容创作者提供一个技术平台,成为互联网内容的“做市商”,确保所有内容创作者都能在新的市场机制中获得公平回报;
• 客观来说,Pay-per-crawl 今天还是一个实验型产品,还没有给 Cloudflare 带来实际的收益,还需要考虑很多细节规则的设计;
• Cloudflare 的角色很像是一个网络管理员,专注于数据的快速传输, 当 Agent 互动带来新一波高频流量和数据互通需求时,Cloudflare 仍旧有机会受益于此,今天 80% 的 AI 公司已经在使用 Cloudflare 的产品;
• 站在 Cloudflare 的视角,整个 AI 领域的关键突破点之一在于如何提高 inference compute 的效率,目前高功耗是最大的限制因素,而这一现实需求会带来“AI 时代 WMware”级的机遇。
• 不同于云服务商,Cloudflare 按算力消耗计费的商业模式更关注推理效率:如果有人能将推理效率提高 100 倍,一定是利好 Cloudflare 的。
01.
Cloudfalre 的诞生
Cloudflare 在 2010 年 9 月上线,如今的市值已达 660 亿美元,年收入 18 亿美元,是全球最大的 CDN 提供商,同时也提供了一系列网络安全相关的产品。截至2025年6月30日,Cloudflare的付费客户数量超过了26.5万,财富500强企业中有36%是 Cloudflare 的付费客户。公司的毛利率达到了75%,近5年营收复合年增长率超过42%。
CDN:内容分发网络(Content Delivery Network)是一种通过在全球部署服务器节点,把网站内容缓存到离用户更近的地方,从而加快访问速度、减少延迟的技术。
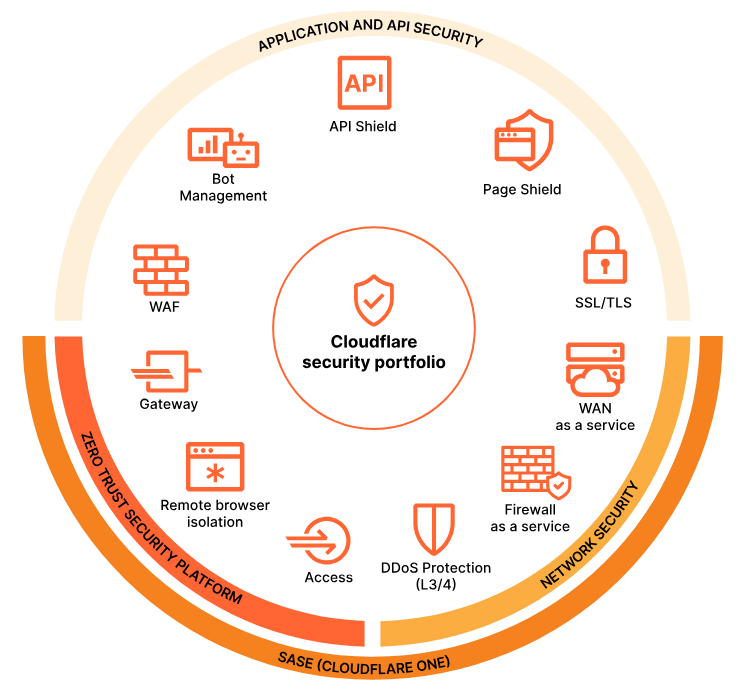
公司目前主要包括三个核心业务板块:
• Zero Trust Service:用于保护企业内部和外部访问安全;
• 网络服务:提供DDoS防御、智能路由等底层网络功能;
• 应用服务:包括Web应用防火墙和 CDN,作用是加速和保护网站。
此外,公司还提供开发者平台,让开发者可以直接在Cloudflare的边缘网络上构建和运行应用。
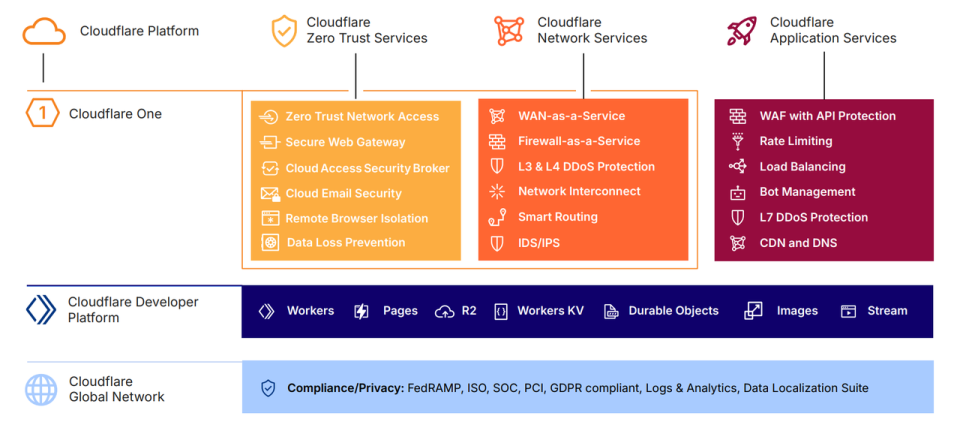
Cloudflare 产品架构概览
在创立 Cloudflare 之前,创始人 Matthew Prince 创立了一家垃圾邮件过滤公司 Unspam,并在运营 Unspam 期间酝酿出了创立 Cloudflare 的想法。
Matthew Prince 工作经历
Lee Holloway,同时也是当时 Unspam 的技术成员,他开发了一个用于追踪垃圾邮件窃取邮箱的“Project Honey Pot”(蜜罐计划),这个产品迅速吸引十多万用户。
Lee Holloway 工作经历
在一次讨论中,当时还是 Matthew Prince HBS 的同学 Michelle Zatlyn (后来也成为Cloudflare 联创之一)指出“Project Honey Pot” 并没有找到自己的商业模式。Matthew 的回答是“总有一天,人们会希望我们来阻止坏人。”这句话给 Zatlyn 带来了灵感,她提出了一个“云端防火墙”的概念, 将“Project Honey Pot”的功能从识别拓展到反击那些垃圾邮件发送者和黑客。
Michelle Zatlyn 工作经历
Cloudflare 由此诞生,Cloudflare 的名字也来源于此:“云端(Cloud)”与“防火墙(Firewall)”。Cloudflare 一开始的目标很简单:将防火墙搬到云端,并免费提供 DDoS 防护服务。通过免费服务吸引小网站,再逐步扩展到大企业。在 Matthew 看来,只要足够多的互联网流量经过 Cloudflare,就能找到商业模式。
在当时,随着服务器和软件向云端迁移,网络性能下降成为外界的主要担忧,而 Cloudflare 不仅解决了性能问题,还顺势进入了 CDN 领域。
Cloudflare 的早期用户群体是预算有限、但信息风险极高的机构,例如人道主义组织,他们频繁遭受黑客攻击,因而亟需一个低成本、高性能的防火墙工具。这类需求意外地为 Cloudflare 提供了极其宝贵的实战训练机会,甚至连黑客本身也会主动前来测试防御的极限。
在云端防火墙的建设过程中,如何获取数据是一个关键问题,正是因为 Cloudflare 提供免费服务,因而自然而然地吸引了大量不同类型的用户,这不仅帮助公司完善了产品和系统,与此同时也带来了规模扩张和管理复杂性的新挑战。公司从一开始就把自己当作“零号客户(customer zero)”。所以今天很多核心业务(或产品)最初都源自 Cloudflare 的内部需求:
• 域名注册业务:为了应对黑客企图通过窃取域名发起攻击;
• VPN 替代方案:来自于市场上缺乏能支撑他们规模的工具;
• 开发者平台:最早是为公司内部开发提供的沙盒环境。
随着公司对恶意流量拦截能力增强,互联网服务提供商也更愿意合作,从而进一步形成了良性循环,整体服务质量随之提升。
Cloudflare 的竞争对手并非 Akamai 等传统的 CDN 服务商,而是像Facebook这样的封闭平台。早期许多长尾网站和创作者因频繁遭受恶意攻击而运营困难,不得不寻求 Facebook 这样的“围墙花园(walled-garden)”的庇护,从而换取安全和便利。而 Cloudflare 提供了另一种选择,他们通过提供免费且优质的基础服务,让小网站在保障安全的同时,能继续拥有在开放互联网(Open Intenet)上创新的机会。
Akamai 是 CDN 领域的先驱和巨头,与 Cloudflare 类似,Akamai 通过分布式网络技术帮助企业提高网站性能、可靠性和安全性。
Cloudflare 安全管理面板
02.
互联网传统价值变现模式正在被 AI 颠覆
Cloudflare 很特别的一点是,它的业务和产品的演化、迭代是和互联网进化过程紧密联系在一起的,而最近讨论度很高的 Pay-Per-Crawl 也源于 CEO Matthew 对互联网内容生态的观察,即 Chatbot 的崛起正在“摧毁”传统互联网的价值变现模式。
“pay-per-crawl(按爬取付费)”,Cloudflare 在今年 7 月上线的新功能,支持网站内容创作者主动设置 AI 爬虫的“内容权限”,包括:允许 AI 爬虫自由访问、按次爬取收费,或者直接封锁 AI 爬虫访问。
Matthew 认为,过去 30 年互联网的价值创造模式主要由搜索驱动,搜索推动了几乎所有线上活动,并催生了完整的产业生态,相对应地诞生了三种商业“价值实现”路径:
1. 直接销售:通过商品、订阅或数字产品盈利;
2. 广告模式:基于内容展示广告吸引流量获取收入;
3. 非商业驱动:即创作者为了成就感或获得认可而生产内容,维基百科这样的无偿创作就是典型例子。
今天最明显的趋势是,互联网入口正在从“搜索引擎(search engine)”转向“答案引擎(answer engine)”:搜索引擎提供链接让用户自己寻找答案,而 OpenAI、Anthropic、Perplexity 等公司代表的答案引擎则直接给出答案。
对于用户来说,answer engine 显然是更高效的体验,但对于内容创作者或者网站所有者而言,也意味着用户点击减少,search engine 被 answer engine 冲击的结果是基于流量的商业模式长期看会失效,这件事首先会对新闻、评论等文字内容的创作者带来极为严重的影响。
无论是从 Google 的使用趋势,还是从 Cloudflare 自身的数据来看,越来越多用户直接依赖 AI 系统,即越来越多的用户获取的内容将不再是原始信息,而是 AI 生成的二次结果。与此同时, Google 自身也在向 AI 公司转型,先后推出了 AI Overview 和 AI Mode。
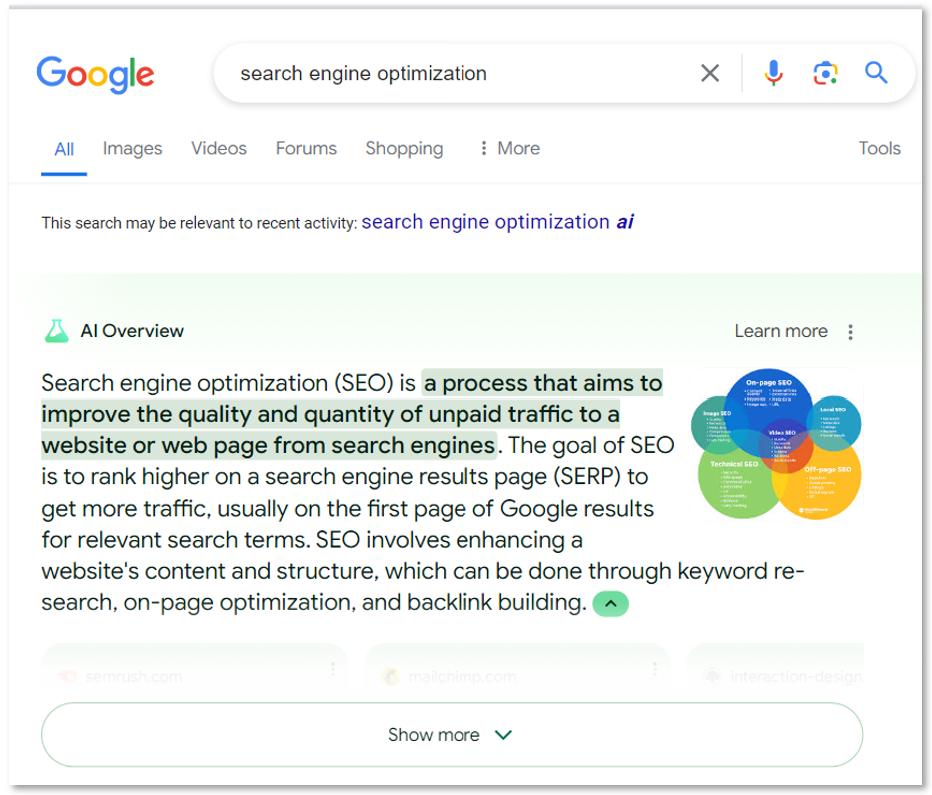
AI Overview
在 Google 的案例里,如果 Google 在搜索结果顶部展示 AI Overview,用户点击原始链接的可能性会显著下降。Cloudflare 的数据也验证了这一趋势:同一篇内容想从 Google 获得点击,如今比 10 年前难了 10 倍,而在 AI 产品中,要想获得点击的难度这是指数级上升:
• 在 ChatGPT 中,想让某条内容获得点击的难度是过去在 Google 的 750 倍;
• 在 Claude 中,这一难度甚至高达 3 万倍。

不同 AI bot 的点击几率不同和产品设计直接相关,Google 虽然展示 AI Overview,但下面仍然会有链接,用户还有可能点击,在 ChatGPT 的设计里,Search 模式下,用户直接在对话框里问问题,得到答案后认可选择点击外链查看原始内容,而 Claude 设计更加“封闭”,基本没有给第三方内容导流的机制,也没有插件生态或网页引用展示。用户几乎不可能通过 Claude 去点击外部链接,所以对内容创作者来说,获取流量的难度更高。
Google Answer box
在 Google 代表的 search engine 时代让大家认为内容理应免费被爬取,因为内容创作者最终可以通过前面提到的 3 种方式获得变现,Matthew 最担心的是,如果网络的价值创造模式一直依赖“如何获得流量”,而以 AI chat 和生成式搜索为核心的新界面打破了这种“等价交换”。在这种背景下,会带来三种可能的结果:
• 第一,内容创作者无法生存,高质量新闻和学术内容可能消失;
• 第二,少数公司垄断内容生产,回到类似中世纪的知识垄断;
• 第三,建立新的商业模式,让答案引擎收入的一部分回流给内容创作者。
作为网站内容创作者,则面对以下几种选择:
• 第一步,重新掌控自己的内容,避免无偿提供资源,从一开始就制造稀缺性,Cloudflare 正在推动这一方向;
• 第二步是主动与各家 AI 公司展开对话,寻找合作的伙伴。最近新闻显示,Google 已启动试点项目,开始向新闻机构付费,而这在过去几乎不可想象。原因很简单:如果创作激励消失,内容无法出售,广告也无法变现。一篇有影响力的文章可能被数百万次用于 AI 回答,但原作者却完全不知情,最终就像在对着虚空喊话。
• 第三步是积极参与到 AI 公司的数据使用过程中,某种程度上 Reddit 和 OpenAI 等公司的合作是一个可参考的案例。
今天许多内容创作者在处理和 AI Labs 之间的内容交易时犯了一个严重的错误:他们达成的交易模式无法随着 AI 公司商业模式的扩张而同步增长。例如,一笔“2000 万美元买断所有内容”的交易,表面上看似划算,但实际上并不利于创作者的长期收益。
真正理想的方式,是建立一个能够衡量内容价值的方法,让创作者根据 AI 模型的订阅费或广告收入长期按比例分成。这样,随着 AI 公司的成长,创作者也能持续分享到收益,实现内容价值的长期兑现。
因此,在这个变化过程中,Matthew 则认为 Cloudflare 可以扮演一个关键角色:以更 scalable 的方式支持网站内容 owners 和 AI 公司达成内容侧交易,尤其是对于“弱势”的海量的长尾内容创业者(或内容平台)而言,Cloudflare 甚至可以帮助设定基础费率和合作模式。
03.
Pay-Per-Crawl:给 AI 内容交易做一套“做市系统”
在这一背景下,今年 7 月,Cloudflare 在上线了 “pay-per-crawl(按爬取付费)”,这个新功能简单来说是让网站内容创作者可以主动对 AI 爬虫的“内容权限”进行设置:允许 AI 爬虫自由访问、按次爬取收费,或者直接封锁 AI 爬虫访问。与此同时,公司正与 IETF 等标准组织合作,制定网络爬虫规范。未来,创作者还可以设置更精细的规则,例如允许人类免费访问,但要求机器人付费等。但目前来看 “pay-per-crawl”更像是一个实验性产品。
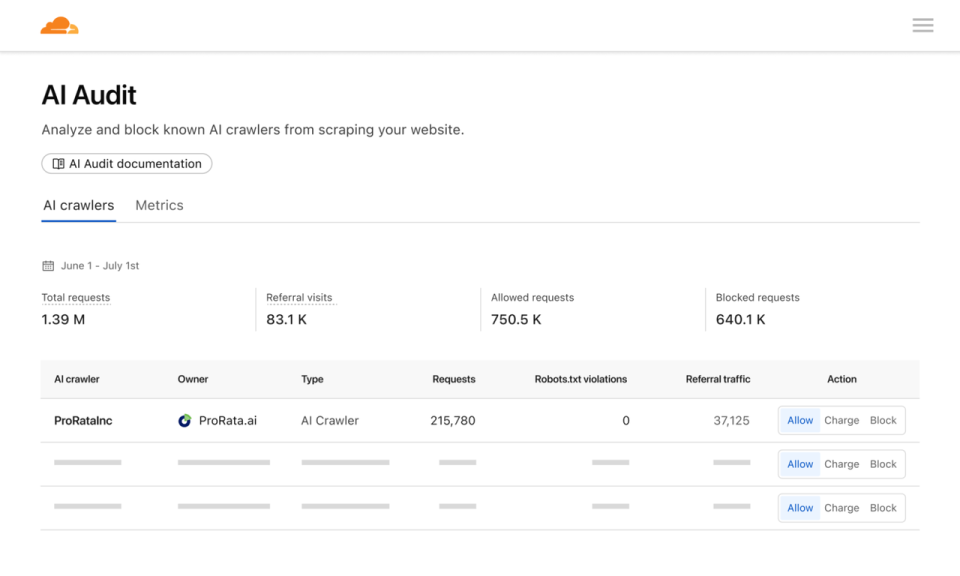
之所以有“Pay-per-crawl”是因为传统的 robots.txt 文件在控制搜索引擎抓取方面只是一个简单工具,无法实现精细化管理,而许多公司并不严格遵守规则,比如前面提到的 Perplexity 曾一度陷入这个争议。
robots.txt 是一个用于指导网络爬虫(如 Google、Bing 等搜索引擎的机器人)如何抓取网站内容的文本文件。它像网站给爬虫的一张“通行证”或“指南”。
因此,Cloudflare 想通过“Pay-per-crawl”为内容市场的公平性提供技术保障。
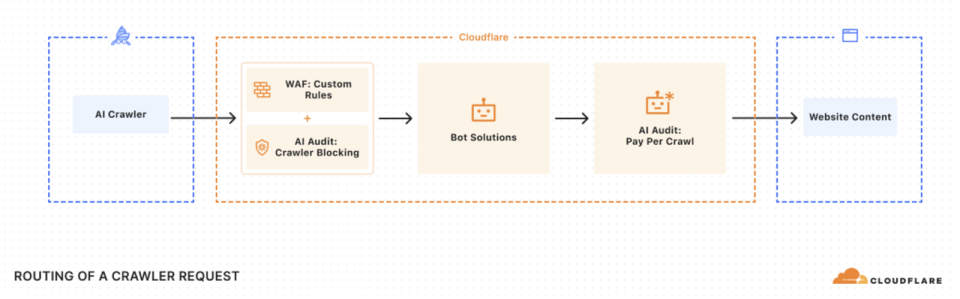
阻止 AI 爬虫
Why
Pay-per-crawl 是 Cloudflare 重构 AI 时代内容交易的第一步,这一模式可行的最核心前提是,对于所有 AI labs,除了算力和人才之外,内容是最关键的资源。
除了前面提到的 AI 颠覆了互联网“用免费内容换流量”的传统互联网变现模式外,Matthew 认为长远来看“长尾、差异化内容”的价值也会得到更多重视,这也是 Pay-per-crawl 可以参与的环节。
具体来说,在“流量变现”的模式下,当“流量”成为唯一衡量指标,媒体和内容平台自然而然就会追逐点击率,通过标题党等方式来变现,但本质上这些内容并未推动人类知识的进步。
Matthew 在这里做了一个对比:如果以 tokens 计算 Reddit 和《纽约时报》的总内容量,二者其实在同一个数量级上。而 Reddit 的收入之所以是 New York Times 的7倍规模正是在于其内容的独特性。
从 LLM 的视角看, New York Times、Wall Street Journal、FT、Washington Post,以及 Boston Globe 等媒体之间的差异其实并不大。因为他们报道的内容可能只在一些观点和立场上存在差异,从 fact 角度收敛度极高。
如果我们把 AI 生成的内容可以看作是“人类知识的近似全集”,这中间还存在大量“奶酪般存在空洞”,但这些空洞往往是最有价值的部分。如果建立一个市场交易机制,让创作者因填补知识空白而获得报酬,而非依赖流量刺激,就能真正推动人类知识的积累与发展。
Matthew 在和 Spotify 创始人 Daniel Ek 交流中发现, Spotify 是少数在大规模上真正补偿创作者的公司。举例来说,iTunes 发布前,音乐产业规模约为 80 亿美元,而如今,Spotify 每年单独向音乐产业支付超过 100 亿美元,这说明如果市场机制设计得当,可以创造更大价值。
Spotify 会分析用户搜索请求,找出那些没有合适答案的需求。例如,当有人搜索“我想要一首关于和狗一起跳舞有多有趣的 disco 歌”时,如果找不到现成内容,Spotify 就会将这一需求反馈给创作者。结果,许多音乐人因为满足这些未被满足的需求而获得可观收益。Matthew 将这种需求称为“未被满足的需求”。
过去很难精确识别内容缺口,而现在通过 LLM 的分析和修剪算法,可以很清楚地发现知识空白。
修剪算法(pruning algorithms):一种优化技术,通过移除神经网络模型中不重要或多余的部分来压缩模型,从而降低计算成本、提高运行速度。
高质量原创内容是 AI 时代最稀缺的资源。比如 Reddit 通过阻止机器人免费爬取、并与 AI 公司达成付费协议,每年获得数千万美元收入,就是这种模式的早期示例示范。
Matthew 希望可以找到一种机制,既能补偿独立的内容创作者,又能确保知识在所有 AI 公司之间共享,而不是被封锁在每一个版本的 LLM 背后。他指出,当前支付给数据标注公司的费用已经超过 100 亿美元,但是否应该把钱花在标注公司、人力成本还是 GPU 上,还需要市场去决定,未来三者的成本都可能增加。关键在于,内容本身能够创造多少价值,而是否值得投入资源,最终仍要由市场来回答。
How
为推动这一进程,Cloudflare 正在采取多项措施。要形成经济体系,首先必须有市场,而要有市场,就必须存在稀缺性。如果内容始终免费无限,就无法形成一个 marketplace,这也是当前问题的核心。
在这一过程中,Cloudflare 想要实现的角色是技术平台提供者,只推动内容可信度和新颖度的排序机制,并不参与内容的评价体系。AI 公司可以根据自己的算法来排序和付费内容,例如 OpenAI、Anthropic 和 Perplexity 的排序标准各不相同。
换句话说,Cloudflare 希望成为市场的“做市商”,而不是内容的编辑或裁判,好的市场机制是“创造稀缺性”,让价值真正得到变现。
在具体的实施方式上,目前 Cloudflare 还在探索,比如这其中可能涉及到区块链、身份认证等各种机制之间的组合。
虽然自己曾对加密货币持怀疑态度,但现在认为它们可能与这一趋势结合得很好。想象一下,如果每一次页面浏览都能实现微支付,面对每天约 15 万亿次请求,这将是一个自然的应用场景。然而,实现大规模、高效运作仍然存在技术难题,目前的区块链技术(如 Solana)尚无法完全胜任。过去十年发展出的技术或许可以重新组合,催生未来的新模式。
身份验证和权限管理也是核心问题。未来可能需要一个底层框架,将 agent、权限和身份验证结合起来。在不同场景下,有时需要人工验证,有时可以让 agent 代替执行,甚至可能允许完全自主的 agent 承担验证。如何在不同权限层次之间进行区分,将成为重大挑战。
浏览器在这个体系中同样关键——需要明确它的角色,是作为功能工具,还是潜在的数据泄露途径。理想的机制应该让浏览器能够声明:“我是某个 agent,我会遵守这些规则”,并通过加密签名确认承诺。未来,管理浏览器访问网页的机制可能与今天管理爬虫访问的机制类似,而一旦浏览器访问的数据立即被反馈给大模型,其权限可能会受到更多限制。
零知识证明(Zero-Knowledge Proof)和这一场景也非常契合,它能够证明拥有某种权限或凭证,而无需泄露额外信息。Matthew 指出,这些技术积木其实早已存在,只是直到最近,随着商业模式的变化和技术发展,它们才开始被拼合成一个完整的体系。新型验证与访问方式的需求加上技术能力的成熟,使得未来能够支持更大规模、更广泛的应用成为可能。
零知识证明(Zero-Knowledge Proof):一种加密方法,允许一方(证明者)向另一方(验证者)证明一个陈述是正确的,而无需透露该陈述本身之外的任何信息。
04.
Cloudflare 如何从 AI 中受益
Cloudflare 受益于“多云”,而 AI 显然会加速这一趋势。
Cloudflare 曾提出要做继 AWS、Google、Azure 以来的“第四朵云”,但目前公有云厂商和 Cloudflare 已经在各自赛道上形成了明确定位。虽然在一些边缘领域存在竞争,但整体方向差异明显。
在 Matthew 看来,公有云如同数据库管理员(DBA),思维聪明但偏向死板,它们以数据库为中心,让所有事物围绕数据运转。而 Cloudflare 的角色则更像网络管理员,专注于数据的快速传输。
数据库和网络的目标天然存在张力:数据库重在数据牢固保存,网络重在高效传输。如果一个团队擅长数据库,通常在网络速度上不如人意,反之亦然。这也是公有云的网络产品普遍不够理想的原因之一:它们不希望数据离开自家体系。同理,Cloudflare 的数据库产品也难以与公有云抗衡。
未来,如果企业趋向“单一云”模式,Cloudflare 的价值空间可能被压缩;但在“多云”的驱使下,Cloudflare 的重要性则会被不断加强,可以理解为它是不同云之间的桥梁与协调层。
今天 AI 的发展和技术扩散一定程度上也在多云趋势:庞大的数据集需要在不同环境之间高效移动,而这正是 Cloudflare 的强项。
虽然 Cloudflare 并不适合运行 SAP HANA 这种重量级数据库,但对于需要频繁与互联网交互、进行信息快速处理的 AI Agents,Cloudflare 也有机会成为这些产品最合适的 infra 工具。Mattew 提到,今天全球约 80% 的 AI 公司都在使用 Cloudflare 的服务。
在模型开放性方面,Cloudflare 同时闭源和开源模型,公司内部大多数技术尽可能开源。Matthew 表示,他个人偏向支持开源模型,比如 Cloudflare 与 Meta 团队合作让开发者能够轻松在 Cloudflare Workers AI 中使用 Llama 4。但他也认为,开源与闭源模型各有存在的合理性,客户会根据自身需求选择适合的方式。
Cloudflare 早在 2020 年就开始布局 inference 领域。当时,公司与 Nvidia 合作,将显卡部署到边缘网络来支持模型推理。那时市场关注度不高,几乎没有销售咨询。四年后,市场已经做好了准备,和当年类似的新闻稿在重新发布时引起了很大的反响。对于小型模型或终端场景,推理可以在本地完成,但对于大型或资源密集型模型,最佳方案仍然是在网络边缘运行,而这正是 Cloudflare 的优势所在。
更重要的是,无论是 MCP 还是其他协议,随着互联网的发展,几乎所有流量都会经过 Cloudflare。公司在这些协议上投入了大量精力来确保安全性、基础设施能力以及支付功能。这意味着 Cloudflare 在内容和支付基础设施上的布局,最终有望自然演化成 AI agent 之间的支付体系。

Cloudflare 在 2023 年 9 月宣布在边缘网络部署 NVIDIA GPU
Matthew 表示,未来很多模型会在设备端或本地运行,而更大、更复杂的模型可能会部署在边缘或云端。事实上,这一趋势已经在逐步发生。如今,手机上已经有大量计算任务可以在本地完成。在某些场景下,本地计算甚至是必须的。例如自动驾驶汽车中,如果路上突然出现一个红色球,小女孩追着它跑,系统必须立即判断是否刹车,这类决策只能依赖车载系统即时完成。
05.
Inference 爆发会带来“AI WMware”的机会
站在 Cloudflare 的视角,整个 AI 领域的关键突破点之一在于如何提高 inference compute 的效率,目前高功耗是最大的限制因素,而这一现实需求会带来“AI 时代 WMware”级的机遇。
这件事其实在历史上发生过。
2011 年,Facebook 在建设自研数据中心时,因电力资源有限而迫切需要高能效的处理器方案。但当他们向 Intel 提出相应需求时,Intel 给出的方案却是依赖高功耗和水冷的传统系统,这件事的本质是 Intel 没有理解超大规模数据中心对能效的核心诉求。
Intel 对新兴市场需求理解的错位最终促使 Facebook 推出了 Open Compute Project,引领了行业对低功耗与开放架构的关注。
Open Compute Project:Facebook(现Meta) 在 2011 年发起的开源硬件计划,目的是通过共享数据中心及服务器设计推动行业效率提升。其成员阵容相当强大,国外还有微软、谷歌、亚马逊、AMD、英伟达等,而国内的阿里、腾讯、百度等也参与其中。
今天 AI 领域面临着类似的挑战:尽管 Nvidia 在提供高性能GPU方面处于领先地位,但产品的高功耗特性使它难以广泛应用于手机、自动驾驶汽车、边缘网络等电力受限的设备。因此,行业的未来方向在于研发能够提供能效最大化的芯片,从而摆脱对大型、高耗能数据中心的依赖,真正实现 AI 的普及化应用。
在这个过程中,需要从两个角度来看问题,当这些条件成熟,转变自然会发生:
• 一是芯片设计,例如 ARM 和 Qualcomm 已在设备端积极布局;
• 二是模型本身的规模、推理延迟及不同组件的耦合。
这些因素相互影响,但核心还是看设备能否承载足够大的模型,并以高效的方式运行。
从模型层面来看,目前大多数 AI 公司在资源利用率上仍不够高效。
Cloudflare 的商业模式是按实际算力消耗计费,而不像超大规模云服务商只管出租 GPU,不考虑利用率。Cloudflare 更关注推理效率:如果有人能将推理效率提高 100 倍,这就是利好;但对于云巨头,这反而可能是不利的。
在计算机科学的基础层面,还有大量潜力尚未被挖掘,可以让模型运行得更加高效。Matthew 相信,不久的将来,人们甚至可以在 iPhone 或安卓手机上直接运行与今天 ChatGPT 类似的模型。
Cloudflare 将重心放在让任何模型能够高效运行。真正的关键问题是:谁会成为 AI 领域的“VMware”。
目前,要部署一块 GPU 往往需要整台虚拟机甚至物理机,成本极高;在大型云服务商那里,如果没有至少一年的合同,很难拿到合理价格,开发者还要承担资源利用效率低的负担。未来必然会有人找到方法,把算力切分得更细、更高效,就像过去 30 年 CPU 的效率演进一样,而这种优化过程在 GPU 上正在以更快的速度重演。

排版:傅一诺