腾讯AI Lab首创RL框架Parallel-R1,教大模型学会「并行思维」
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。
然而,现有方法多依赖于监督微调(SFT),模型一来只能模仿预先构造的 parallel thinking 数据,难以泛化到真实的复杂任务中,其次这种方式对数据要求很高,往往需要复杂的 data pipeline 来构造。
为解决这些难题,来自腾讯 AI Lab 西雅图、马里兰大学、卡内基梅隆大学、北卡教堂山分校、香港城市大学、圣路易斯华盛顿大学等机构的研究者们(第一作者郑童是马里兰大学博士生,本工作于其在腾讯 AI Lab 西雅图实习期间完成)首创了 Parallel-R1 框架 —— 这是第一个通过强化学习(RL)在通用数学推理任务上教会大模型进行并行思维的框架。该框架通过创新的「渐进式课程」与「交替式奖励」设计,成功解决了 RL 训练中的冷启动和奖励设计难题。
实验表明,Parallel-R1 不仅在多个数学基准上带来高达 8.4% 的平均准确率提升,更通过一种 “中程训练脚手架” 的策略,在 AIME25 测试中实现了 42.9% 的性能飞跃。

论文标题:
Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
论文地址:https://arxiv.org/abs/2509.07980
项目地址:
https://github.com/zhengkid/Parallel-R1 (Coming Soon)
项目主页:
https://zhengkid.github.io/Parallel_R1.github.io/
并行思维的挑战:为何注入并行思维如此困难?
并行思维,即同时探索多条推理路径再进行归纳总结。
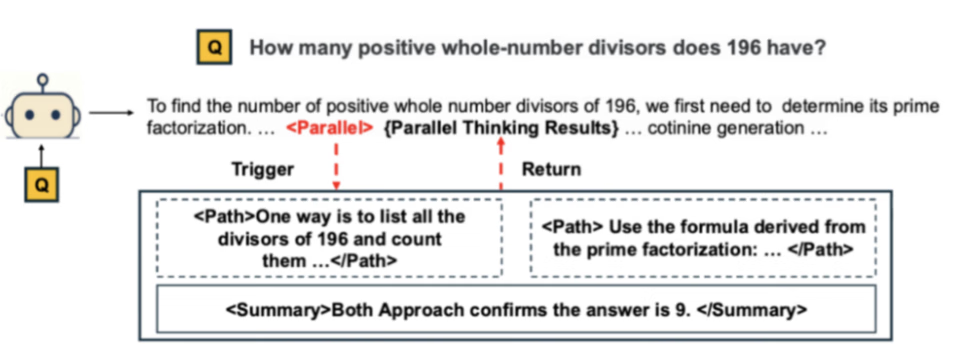
图 1:并行思考流程示意图。
目前最主流的注入并行思维的范式是监督微调 (SFT),但这种方式本质上是行为克隆,强迫模型模仿固定的、预先生成的数据,导致模型只会进行表面上的模式匹配,而无法真正习得和泛化并行思维这一内在的推理能力。其次,这类方式对数据质量和多样性的要求非常高,只有非常高质量的数据才能让模型学习到很好的 parallel thinking 能力。然而,遗憾的是,在现实世界中,人们很难天然获取高质量的这类数据,因此只能依赖于人工合成。而对于真实世界的推理任务,构造这些数据的难度很大,需要复杂的数据管道。
另一方面强化学习(RL)是一种更扩展性强的,但在通用、真实的复杂任务中进行并行思维训练却面临两大核心挑战:
冷启动问题(Cold-Start):由于预训练模型从未见过并行思维的特定格式(如同时生成多个解题路径),在 RL 探索初期,它根本无法自发产生这类轨迹,导致学习无从下手。这时候就需要一个冷启动阶段。但是上文提到,对于真实世界的难题,这种数据很难构造。
奖励设计困境(Reward Design):如何平衡「解题正确率」和「思维方式」是一个难题。如果只奖励最终答案的正确性,模型会倾向于走最简单、最熟悉的单路径「捷径」,从而「遗忘」更复杂的并行思维;而如果强行要求使用平行格式,又可能导致模型为了格式而牺牲逻辑的严谨性,反而降低了准确率。
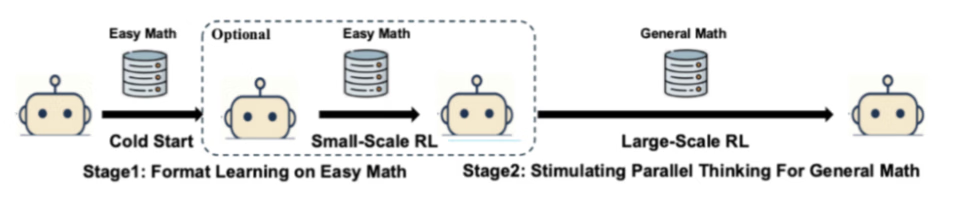
图 2:渐进式课程训练示意图
Parallel-R1 的解法:首个为真实世界推理任务打造的 RL 框架
为攻克上述难题,Parallel-R1 作为首个专为通用、复杂数学推理等真实世界任务设计的强化学习框架被提出。它通过一套精巧的组合拳,系统性地解决了训练困境。
渐进式课程:从「学格式」到「学探索」
研究者的一个关键发现是:用简单的提示工程,让强大的模型为简单数学题(如 GSM8K)生成高质量的并行思维数据是可行的(成功率 83.7%),但对于复杂难题(如 DAPO)则完全无效(成功率 0.0%)。
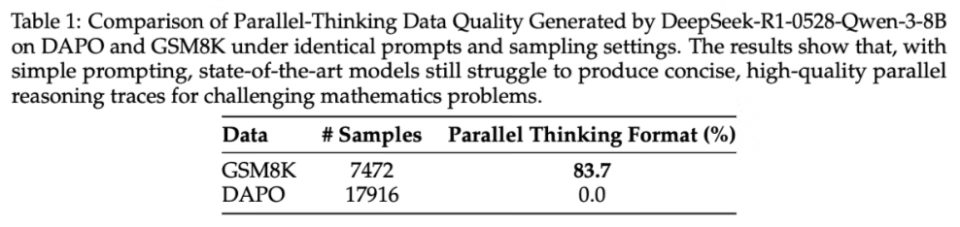
基于这一洞察,他们巧妙的避开了复杂的数据管道依赖,并设计了一种渐进式课程:
第一阶段(格式学习):首先,利用新建的 Parallel-GSM8K 数据集,在简单的数学任务上对模型进行 SFT。此阶段的核心目标并非解决难题,而是让模型学会并行思维的「语法格式」,例如如何使用
、
、
等控制标签 。
第二阶段(能力泛化):当模型掌握了基本格式后,再将其置于更困难的数学任务中,通过 RL 进行训练 。此时,模型已经具备了生成平行轨迹的 “火种”,可以在 RL 的驱动下自由探索、试错,并最终将这一能力泛化到未知难题上。
交替式奖励:在「准确性」与「多样性」间取得平衡
针对奖励设计的困境,研究团队试验了多种方案,最终提出了一种高效的交替式奖励策略。该策略在训练过程中,周期性地在两种奖励模式间切换:
80% 的时间使用「准确率奖励」:只根据最终答案是否正确给予奖励,确保模型的核心目标始终是解决问题。
20% 的时间使用「分层奖励」:在这一模式下,如果模型使用了并行思维并且答案正确,会获得一个额外奖励(+1.2 分);如果未使用并行思维但答案正确,则获得标准奖励(+1.0 分);否则将受到惩罚。
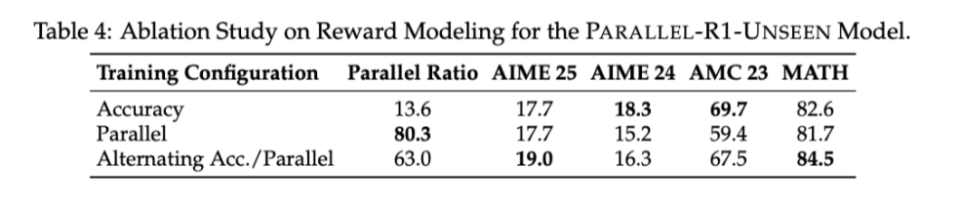
消融实验(见下表)证明了该策略的优越性。单纯奖励准确率,模型的并行思维使用率极低(13.6%);单纯奖励平行格式,模型性能会严重下滑。而交替式策略在将并行思维使用率提升至 63.0% 的同时,还能在 AIME 等高难度测试上取得最佳性能,完美实现了「既要并行行为又要准确率」的目标。
并行思考模型超过单一思考模型
根据下面提供的性能对比表,注入了并行思维能力的模型在各项数学推理基准测试中,其性能优于传统的单一(顺序)思考模型。
打开「黑箱」:模型如何悄然改变思维策略?
除了提出高效的训练框架,该研究还深入分析了模型在学习过程中的动态变化,揭示了一个有趣现象:模型的并行思维策略会随着训练的深入,从「探索」演变为 「验证」。
通过追踪模块在解题过程中出现的位置,研究者发现,在训练初期,模型倾向于在解题的早期就使用并行思维,这相当于「广撒网」,同时探索多种可能性来寻找解题思路。然而,随着模型能力的增强,它变得更加自信,平行模块出现的位置逐渐后移。在训练后期,模型会先用一条自己最有把握的路径推导出一个初步答案,然后在解题的末尾才调用并行思维,从不同角度对该答案进行复核与验证,以确保万无一失。
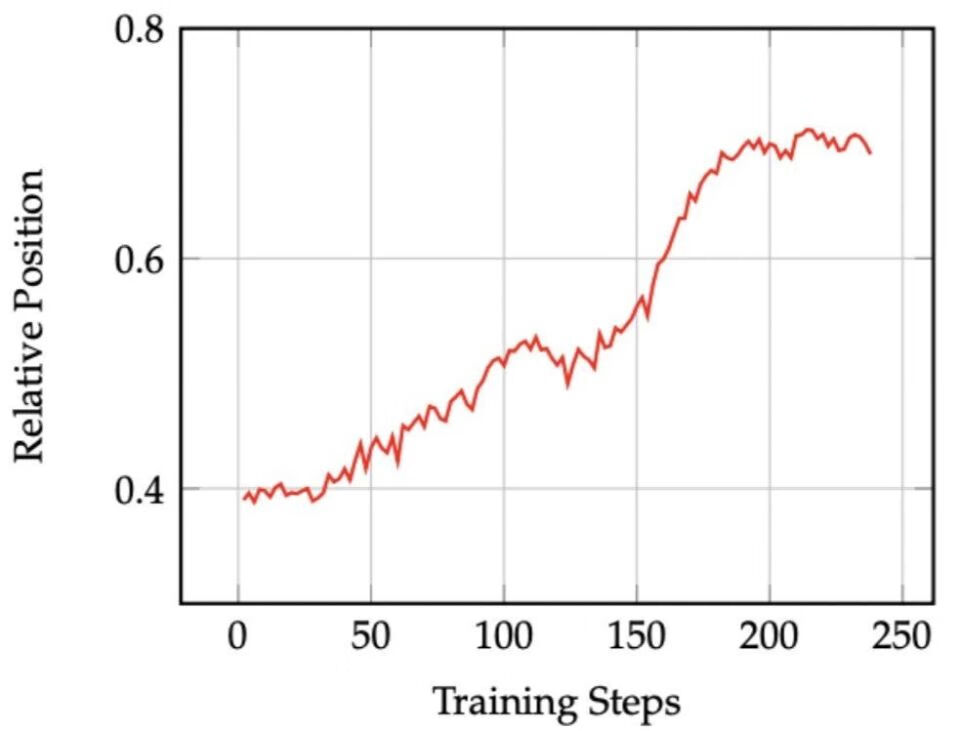
图 3:训练过程中 < Parallel > 模块相对位置的变化,曲线稳步上升,表明其应用从早期探索转向后期验证。
意外之喜:作为「训练脚手架」的并行思维
研究还发现了一个更令人振奋的结论:并行思维本身可以作为一种临时的「结构化探索脚手架」,来帮助模型解锁更高的性能上限。
研究者设计了一个两阶段训练实验:
探索阶段(0-200 步):采用交替式奖励,强制模型高频率地使用并行思维,进行广泛的策略空间探索。
利用阶段(200 步后):切换为纯粹的准确率奖励。此时,模型会逐渐减少对平行格式的依赖,转而专注于提炼和利用在第一阶段发现的最优策略。
结果(见下图)显示,进入第二阶段后,尽管模型的并行思维使用率(绿线)骤降,但其在 AIME25 上的准确率(红线)却持续攀升,最终达到了 25.6% 的峰值。这一成绩相较于从头到尾只用标准 RL 训练的基线模型,实现了高达 42.9% 的相对提升。这证明了,短暂地「强迫」模型进行平行探索,能够帮助它发现一个更优的「能力区间」,即使后续不再使用这种形式,其学到的核心推理能力也得到了质的飞跃。
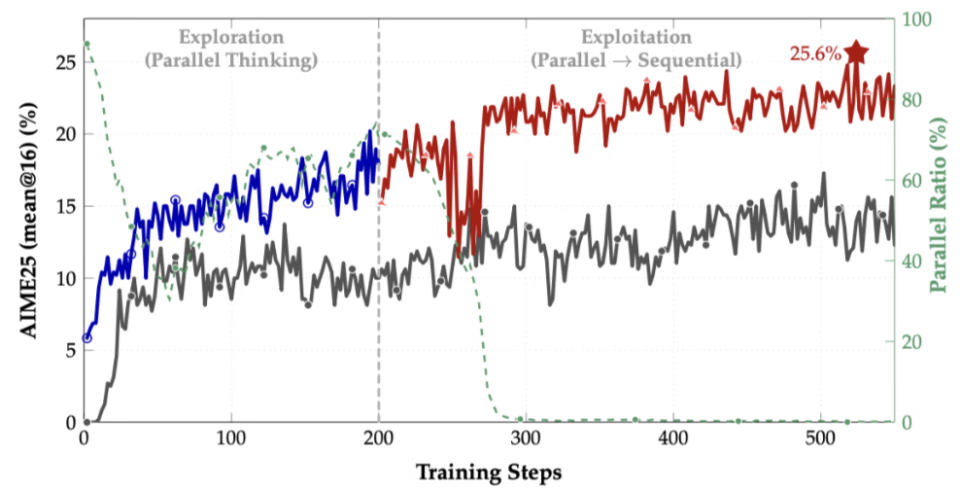
图 4:两阶段训练曲线。在探索阶段后,并行思维使用率下降,但模型准确率持续走高,超越基线。
总结
在这项工作中,研究者们提出了 Parallel-R1,这是首个能在真实的通用数学推理任务上,通过强化学习教会大模型进行并行思维的框架。除此之外,研究者们进一步对并行思考行为以及其潜在价值进行了深入探讨。
