RL Infra 行业全景:环境和 RLaaS 如何加速 RL 的 GPT-3 时刻

作者:Cage
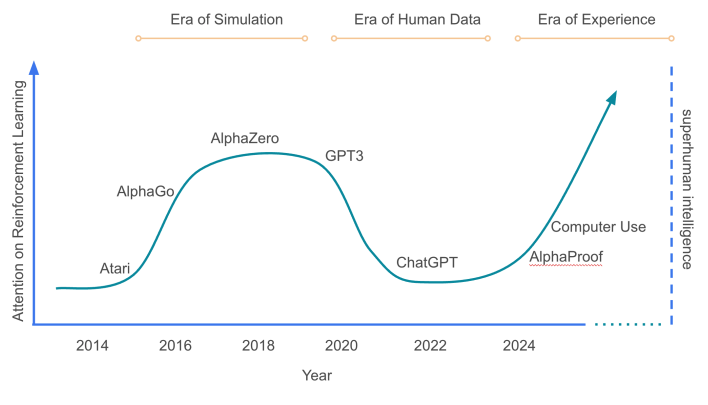
RL Scaling 正在把 AI 从“人类数据时代”推向“Agent 体验时代”,带来真正能够胜任复杂、长链条任务的 Agent 新范式。从静态数据到动态交互的学习范式变化,亟需一套全新的基础设施,也因此新的一批创业公司应运而生。RL Infra 的核心价值是弥合模拟训练与真实世界间的“sim-to-real”鸿沟,让 AI Agent 在部署前就能经历超人类强度的“压力测试”和“刻意练习”,使其从实验室 demo 走向商业可用。
我们对于 RL Infra 的行业图景梳理了三大模块:RL 环境、RLaaS、数据/评估。版图的一端是致力于将真实工作流“高保真化”的环境平台,另一端是为企业特定工作流深度优化的 RLaaS 解决方案,而数据与评估则作为关键桥梁贯穿其中。两种主流路径也代表了不同的商业野心:“横向平台化”的 RL 环境,其目标是成为 AI 时代软件世界的“Unreal Engine”;而“纵向一体化”的 RLaaS,则有望在特定行业内,成为赢家通吃的“AI-native Palantir”。
随着新趋势的演进,我们将迎来 RL 的 GPT-3 时刻,把 RL 数据规模真正拉升至预训练量级。从投资角度看,RL 环境与数据是一枚硬币的两面,构成了押注 Era of Experience 主题的对冲组合;而 RLaaS 则有希望在特定行业中孵化出新的垂直垄断型领军者。
01.
为什么需要 RL Infra?
1、Era of Experience:打造动态环境,告别静态数据
Foundation Model 正在面临一个瓶颈:仅依赖静态、人类互联网生成的数据集所能带来的性能提升已显现出边际递减的趋势。正如两位 RL 先行者 Richard Sutton 和 David Silver 所说的,我们正在从“人类数据时代”迈向“Agent 体验时代”(Era of Experience)。
在这个新时代,AI Agent 不再仅仅是知识的复述者,而是通过与环境的持续互动来自主学习和成长的行动者。因此业界开始将目光投向 RL 环境交互。通过在模拟环境中试错,模型可以学到长链条推理、复杂决策等 pretrain + SFT 难以获得的能力,提高可靠性和泛化性。
这个趋势下我们认为 RL 有机会迎来自己的 GPT-3 时刻:模型训练从在少数环境上微调,转向多种环境的大规模训练。通过将交互环境的规模和多样性提升到远超当前的数量级,带来具备强泛化和快速适应新任务能力的 RL 模型。
今年 AI Community 热议的 RLVR 指的是设计出可自动验证结果正确与否的任务和奖励,让强化学习过程不用过多依赖人类反馈,实现高度自主的优化。对于 RL Infra 提供商来说,RLVR 趋势是其最直接和最强劲的增长动力。
当前很多 RL 训练的数据总量相对有限,比如 DeepSeek-R1 的 RL仅在约60万道数学题上训练,相当于人类连续工作6年的任务量;而GPT-3的训练语料达到3000亿 token,相当于数万年的人类写作。要让RL训练获得与GPT-3相当的“经验”规模,可能需要把 RL Scaling 做到和 Pretrain 一个量级的计算量, 上万年等效任务时长的交互经验数据。实现这一点的前提可能是显著 scale RL 环境的数量和多样性,并且让这些环境能通过 RLVR 的方式自动评估。
2、现有 Infra 和生产环境的不足
RL 要实现上述愿景仍面临瓶颈,首先是训练环境的稀缺和受限。当下的 RL 环境非常初级,支持的任务和工具有限,远不能模拟现实工作的复杂性。如果让一个人当软件工程师,不能开虚拟机或Docker、不能使用 Slack 搜索历史信息和 at 同事,而且无法与两个人以上协作——大多数行业目前能实现的 RL 环境还如此受限。过去这些限制可以理解,因为早期AI智能体能力弱,经不起复杂环境的考验。但现在模型能力在提升,新兴的 RLVR 范式要求更丰富的环境,否则进展将受严重制约。
生产环境悖论(The Production Environment Paradox)是构建RL环境中常见的问题。理论上,让 AI Agent 在真实的生产环境中学习是最高效的方式,因为它能获得最真实的反馈。然而,这在实践中会带来很多风险:安全和合规风险难控(涉及用户敏感数据和政策限制)、用户对错误容忍度极低(尤其多步交互场景下出错代价高)、线上系统的事故预算、Agent 在支付系统中大量支出等等。
其次,奖励设计的难题依然突出。如果奖励函数不够精确,智能体往往会“钻空子”去优化错误的目标(即所谓的 reward hacking),在训练环境中表现很好却学偏了目标,导致迁移到实际场景时失败。这些挑战使得 RL 模型在训练环境之外泛化不佳,极大限制了RL在更广泛任务上的应用效果。
近期行业动向也印证了这一需求:例如 AI 云服务商 CoreWeave 就在这个月收购了主打 RL 训练工具的初创公司 OpenPipe,开始将可训练的交互 Agent 平台和团队纳入自身产品。

02.
RL Infra Mapping 框架
当前涌现的 RL 基础设施创业公司大致分为两类:一类专注提供RL 环境(Environment),另一类提供“RL 即服务”(RL-as-a-Service)解决方案。此外,还有少量公司从数据切入,为RL提供高质量的反馈数据和评估工具:
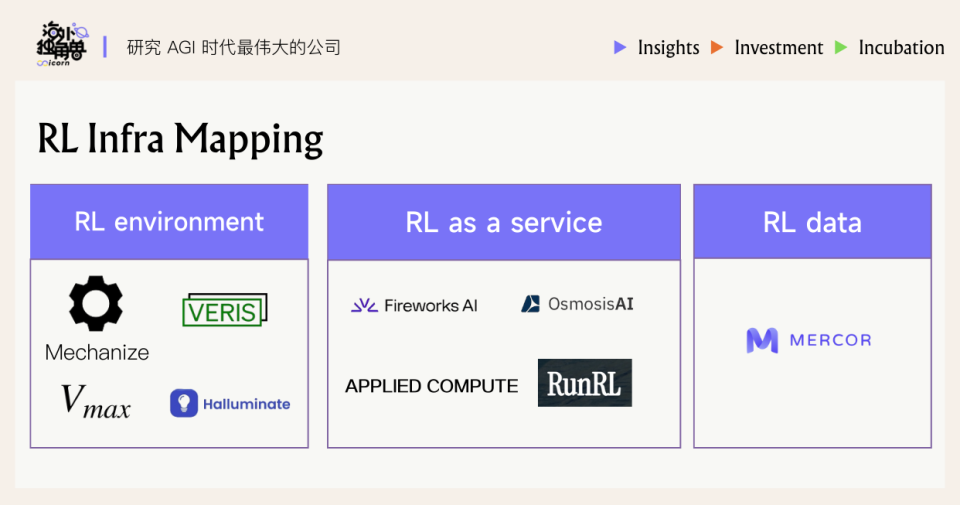
• RL 环境类公司:这类公司是模拟环境的搭建者,面向需要训练 Agent 的AI Lab、中小团队,提供模拟训练环境、任务平台和基准测试。目标是将真实世界的工作流“可模拟化”,让AI Agent 在虚拟环境中反复练习,从而产生规模化的交互数据。理想情况下,这些环境是标准化、scalable 可扩展的,可以供不同模型反复使用。这种模式如果跑通,将极具规模效应——一家环境平台公司可以服务众多 Agent 开发者,就像游戏引擎服务众多游戏开发一样。不过,打造逼真的通用环境本身极具挑战,往往带有浓厚的 research bet 属性:短期商业化不确定性高,但一旦技术突破可能诞生新平台型公司。
• RL 即服务(RLaaS)公司:这类公司可以看作 RL 技术下的 Palantir 模式。它们主要瞄准大型企业的具体需求,与企业深度合作,将 RL 应用于企业现有工作流以解决实际业务痛点。类似技术咨询或专业服务:深入了解企业业务 -> 定义强化学习任务和奖励 -> 准备数据和模拟环境 -> 训练专属模型 -> 持续监控迭代。每个企业的方案都是高度定制化的,因此短期内这类业务难以标准化,扩张更多依赖人力投入。不过RLaaS公司直接创造商业价值,企业客户愿意为效果买单,单个合同金额往往可观(有创业公司以千万美金级别的大合同切入市场)。因此这是一个更适合“观察 traction 后重仓”的领域。
• 数据/评估类公司:随着RL兴起,也有团队专注于提供高质量的数据和评价工具。例如 Mercor 等公司开始开发RL时代的评测基准和数据集,充当“数据军火商”。这些公司的切入点是,目前构建RL所需的大量交互数据和精细评分标准仍然稀缺,他们通过专家标注和自动化工具,为训练和验证RL模型提供支持。从长期看,环境和数据是相辅相成的:逼真的环境能产生有价值的数据,而丰富的数据反过来可以拓展环境场景。因此在投资上,环境平台和数据工具可能构成一个 hedge 组合(这一点我们会在后文讨论)。
总的来说,目前 RL Infra 领域还处于早期探索期,各类创业公司的切入方式都有微妙的差异。下面我们将深入剖析 RL Environment 和 RL-as-a-Service 两大类别的技术要素和代表公司案例,来勾勒这个新赛道的版图。
03.
RL 环境:构建软件的Unreal Engine
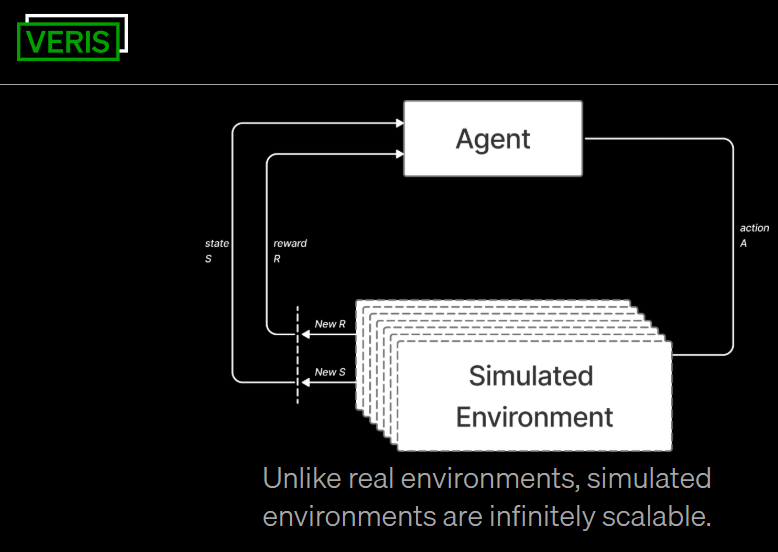
这类公司致力于搭建高保真模拟环境,让AI Agent 能够在接近真实的条件下进行训练。其本质是一个可以安全、大规模、可复现地生成“经验数据”的工厂。构建这样一个环境,远比听上去要复杂,因为要面对现实环境中常见的奖励稀疏、信息不完全等难题。只有通过模拟环境提供丰富且即时的反馈,让模型的每一步动作都能获得评估信号,才能更有效地学习。一个典型的模拟环境至少包含这样三大核心要素:
1.状态管理系统 (State Management System):用于记录和更新环境的状态,定义了 Agent 可以感知和影响的世界。这个系统里包括了任务开始时的初始世界快照、agent 的行为如何改变世界状态的转换逻辑,以及对所有相关资产(如模拟的 API、数据库、合成用户)的精确建模。
2.任务场景 (Task Scenarios):agent 需要解决的问题情境,包括任务描述、背景信息、成功标准和约束条件等。比如在一个客服环境里,任务场景可能是一系列客户询问和帐户信息,Agent 需要最终完成退款流程且符合业务政策。
3.奖励/评估系统 (Reward/Evaluation System):这是 agent 学习的指挥棒,通过验证函数来判断任务是否被正确完成,并为复杂的多步骤任务提供中间奖励信号 process reward。这个系统可以使用 LLM 作为裁判、传统的 unit test,或是行业定制的评分规则。
当前涌现的RL环境平台主要有几种形态:
• 应用级沙盒:针对特定软件应用或工作流程构建沙盒环境,例如 CRM/ERP 系统、客服票务系统的模拟器。在这样的沙盒中重现应用的 UI 和功能,agent 可以像人在真实软件中一样操作完成业务流程。例如 Salesforce AI Research 近期推出的 CRMArena-Pro 就是一种典型案例,在 Sandbox 环境中注入了高度仿真的合成CRM数据,模拟企业客户服务、销售报价等复杂流程。这代表着 SaaS 应用有机会封装成标准化的基准环境。
•通用浏览器/桌面环境:这个方向更接近 computer use agent 路线。提供一个虚拟的网络浏览器、操作系统或者办公软件环境,让AI Agent 练习网页导航、表单填写、文件编辑。这类环境通常需要模拟鼠标键盘交互、UI元素识别,以及处理真实互联网中的各种不确定性(如随机弹窗、验证码、网络延迟等)。
• 环境世界模型:这是更具 research 色彩的一个方向,利用大量历史交互数据训练一个环境模型,模拟现实环境对 Agent action的响应。简单来说,让另一个 Coding Agent 生成环境,AI Agent 在这个“模型想象”的世界中与之互动,以获得近似真实的经验。这类似于“世界模型”思路,由环境模型对 Agent 动作进行滚动预测,提供练习所需的反馈。这种方法的好处是可以摆脱对手工搭建环境的依赖,用 AI Synthtic Data 驱动的方式生成新环境。
合作伙伴生态方面,不少环境平台公司选择与算力提供商或模型提供商合作。例如有的创业团队负责搭建环境和训练管线,但将模型托管和大规模算力任务交给第三方(如 Fireworks、Together 等)来运行。这种模式让初创公司无需自建大型基础设施,就能为客户完成RL训练。
Case Study
Mechanize - Replication Learning 平台
这家公司是新锐环境平台的代表,Founder 来自 Stripe 和 Epoch AI 这个 AI frontier banchmark startup,得到了 Nat Fridman 和 Daniel Gross 的天使支持。
Mechanize 提出了复制训练(Replication Training)的新范式。它的核心思想是:让 AI Agent 去完整复现现有软件产品或其中的特定功能,并以此作为训练任务。任务成功与否,可以通过自动化的方式进行验证,例如 agent 生成的代码是否通过了原始仓库的所有单元测试。这种方法巧妙地将一个开放、模糊的创造性任务,转化为了一个有明确、可验证奖励信号的 RL 问题,从而解决了为长周期、复杂任务设计奖励函数的难题。
这个思路利用了人类已经开发的大量软件作为蓝本,可以源源不断生成训练任务,就像预训练用互联网语料一样丰富。软件在互联网中比比皆是,AI可以通过复制这些软件来积累能力。这使扩展RL环境规模成为可能。
虽然“逐字复刻”一个程序听起来不是常见的工程目标,但这是现在头部 AI Lab 明确需要的,可以有实验环境供 AI Agent 作为 playground。同时这种任务锻炼了AI一系列核心技能:精确阅读并理解长规格说明、严格 instruction following 不犯错、发现并纠正自身早期步骤中的错误、在长达数万行代码的项目中保持连贯。
Veris – 企业属性更强的训练场
Veris AI 选择了一条更为务实的、以企业级市场为导向的 GTM 策略。他们意识到企业在采用 agentic AI 时,最关心的问题是安全、合规和可靠性。因此,Veris 的切入点是为金融、制造业、人力资源等高风险领域提供一个绝对安全的训练场。他们近期完成了由 Decibel 和 Acrew 领投的 850 万美元种子轮融资,以加速这一进程。
Veris 的核心差异化在于其 Mirror Your Stack的能力,他们为每个企业客户构建其生产环境的“数字孪生”,这个孪生体不仅包含了通用的软件,更关键的是,它精确复刻了客户独特的内部工具、API 接口、数据结构和用户交互模式。这种高度定制化的环境,最大限度地缩小了模拟与现实之间的差距(sim-to-real gap),使得企业可以在一个隔离的沙盒中,放心地用自己最核心、最专有的工作流来训练 agent,而不用担心任何风险。通过上述机制,Veris 致力于解决企业部署 AI Agent 时的两大痛点:环境安全(提供安全的离线环境训练,避免在生产中不成熟 Agent 带来得问题)和训练有效性(让AI学到企业任务的精细要求)。
据报道,一些制造业、Fintech 行业的公司已经在使用 Veris 平台训练它们的AI Agent,并取得了成效。一个代表性的例子是 “供应商谈判 AI Agent”:Enterprise 客户希望用AI自动化采购谈判。他们与Veris合作,模拟了一个Slack对话和邮件往来的环境,内含大量业务细节和敏感信息,让AI Agent 在其中练习如何与供应商周旋。训练后在语气拿捏、问题提问、条款让步等方面表现出色。
Halluminate,computer use 环境平台
Halluminate 则代表了 computer use 环境平台的思路。他们发现,目前很多 Browser Agent(浏览器自动化智能体)表现不理想,解决方案是同时提供 “真实沙盒”和数据/评估服务:
1.真实感沙盒:他们构建了一系列可高度并行的模拟环境,覆盖常用的企业软件和网站(例如模拟版的Salesforce、Slack,仿真的电商网站等)。这些沙盒过滤掉了真实网络环境中的噪音因素(如广告、验证码),但保留了核心交互逻辑,使 Agent 既能安全练习,又能快速重复试验成千上万次,加速迭代。并行化意味着可以同时跑许多 rollout,加快数据收集效率。
2.专有数据集和评估:Halluminate 构建了自己的基准任务和数据集,配以专家注释,用于严格评估 Agent 的性能。他们的评估服务可以帮助客户识别 Agent 在哪些环节出错最多,从而有针对性地优化。这种“数据驱动的失败模式分析”让模型开发迭代速度大大提升。

当然,RL 环境方向也存在明显的不确定性。环境构建本身投入高且见效慢,要真正做到通用和高保真并非易事。于是我们看到不同创业公司采取了截然不同的市场定位:小而快 vs. 大而深。一类公司偏向产品化和规模化,希望快速开发出大量中等保真度的环境,覆盖各种场景,服务长尾客户;另一类则专注于拿下少数大客户,深度定制高保真环境解决方案(有点类似顾问式项目),后者就是我们接下来要讨论的 RLaaS 方向。
04.
RLaaS : 打造AI-native Palantir
当大量传统企业意识到RL的价值,却苦于自身缺乏相关人才和技术时,“强化学习即服务”(RLaaS)应运而生。RLaaS 提供商应运而生,为企业提供托管的 RL 训练平台和专业支持,将 RL 直接应用到企业的关键工作流和专有数据中。其服务模式通常涵盖以下环节:
1.奖励建模(Reward Modeling)
RLaaS团队首先与企业一起梳理出业务最关心的指标(KPI),并将其转化为可计算的奖励函数。因为企业目标往往是抽象的(如“提升客户满意度”),需要分解成具体的度量标准。RL专家会借助领域专家的知识,不断试验调整,把模糊目标变成 Agent 可优化的数字信号。例如,在客服场景也许需要综合考虑响应准确率、解决时长、客户情绪评分等多个维度来设计奖励。
2.自动化评分(Auto Scorer)
有了 reward model 后,团队会搭建自动评分管道,对AI Agent 在模拟环境中每次回合(rollout)进行严格打分。这通常通过事先准备的一系列测试用例或规则来实现:例如客服任务,可以准备100个标准问答流程,Agent 每完成一步就检查其操作是否与理想步骤匹配;又或者在财务报告审核任务中,设计一系列已知错误的报表让 Agent 挑错,看其是否能抓出所有关键问题。这个评分器相当于AI 的自动化裁判,提供即时、客观的反馈信号,是RL训练的关键一环。很多RLaaS公司积累了一套自己的评估工具链作为护城河,能够针对不同领域快速定制出有效的评分方法(这常涉及到一些规则脚本、模式匹配,并训练一个辅助的判别模型来评估AI输出)。
3.模型定制与强化微调(RFT,Reinforcement Fine-Tuning)
在环境和奖励就绪后,RLaaS团队会选取一个合适的基础模型(可以是开源大模型,也可能是客户自有模型)进行定制化微调,不断让模型与环境交互,根据奖励信号调整策略。这个过程可能使用策略梯度、进化策略等RL算法,但对客户来说这些细节是隐藏的,他们看到的只是模型在持续改进的效果。值得一提的是,新兴的 inference 平台也正努力让训练管线更自动化。例如 Fireworks 推出的强化微调功能就允许用户用一段Python代码定义评价函数,平台即可接管剩下的训练流程。这种工具的出现使RLaaS能以更产品化的方式交付,而非完全人力密集的项目。
Case Study
• Fireworks AI,从 Inference 到 RFT 标准定义
作为一家创立三年的 AI Inference Infra 公司,Fireworks 近期把强化微调(RFT)也做得很好。他们的平台让用户可以方便地对开源大模型进行RL训练,只需提供一个评分函数,其他诸如GPU资源、训练循环、实验管理等全部由平台处理。Fireworks 称多家早期客户已用其平台将开源模型微调后,效果追平甚至超过封闭的顶尖模型,且推理速度提升10~40倍。例如,Fireworks与 Vercel 合作,用RFT训练了一个代码自动修复模型,性能可媲美 GPT-4 衍生模型,而运行速度快数十倍。Fireworks 本质上是在降低RL的使用门槛,并用模型 inference customization 的商业模式接下这些用户。

• Applied Compute,OpenAI 明星团队
由OpenAI前研究人员创立于2025年,属于RLaaS中高举高打的路线,他们在 pre-launch 阶段就以 1 亿美元的估值获得了由 Benchmark 领投的 2000 万美元种子轮融资。他们选择和少数大企业深度绑定,以项目制形式落地RL方案,每单合同可能高达数千万美金。这种模式更像 AI 咨询公司。尽管产品细节仍处于保密状态,但公开信息显示,他们可能将初步重点放在能源、制造等传统工业领域,利用 RL 优化复杂的工业流程。
• RunRL,从开发者切入 service 的平台
同为YC出身的初创,名字直白地点明了其愿景:让任何人都能“一键运行RL”。他们将底层的 GPU 集群管理、算法选择、模型预热等所有繁杂工作全部包揽,开发者只需提供初始提示(prompts)和奖励函数即可。其定价模式也极其透明,按节点小时收费($80/node-hour),清晰明了。RunRL 代表了 RLaaS 领域里偏民主化的方向:以低门槛的方式开放给企业开发者,其平台表示大多数14B以下模型在单节点即可跑RL训练。
05.
RL 趋势下的未来展望
RL环境 vs RL数据:此消彼长还是相辅相成?
“环境”与“数据”常被对立地讨论:一种观点认为与其钻研构建复杂环境,不如投入人力收集高质量交互数据来训练模型;另一种则相信逼真的环境能生成出无限数据,才是可持续、指数级增长的来源。环境和数据确实像是一枚硬币的两面,数据公司在生成 observations from a world,而环境公司就在模拟 the world。
• 在线学习(RL 环境):其最大优势是能生成完美的 on-policy 数据,即 agent 从自身的行动中直接学习,反馈最直接有效。但它的缺点是成本高昂且速度较慢,因为每一个数据点的产生都需要运行一次完整的模拟交互。最近 Cursor 发布的 Online RL 还只是为 Tab 这个短链路、高频反馈的场景设计,需要更好的环境来走到 long horizon agentic 任务的 online RL。

• 离线学习(RL 数据):其优势是成本低、速度快,可以直接利用已有的海量数据。但其根本缺陷在于这些数据是“离策略”(off-policy)的,即数据是由其他 agent 或人类产生的。直接在这些数据上学习,模型很容易学到一些虚假的关联性,导致其泛化能力差,在真实环境中表现不佳。
Mercor 团队也在密切关注 RL 前沿进展
对于如何最高效地训练出最顶尖的 agent,业界尚未形成统一的定论,很可能是这两种方式的某种结合。一个稳健的投资策略,是同时布局这两条路径。如果未来证明,构建和运行高保真模拟环境的成本是主要瓶颈,那么拥有海量高质量离线数据的公司将变得极具价值。反之,如果离线数据被证明不足以训练出真正通用的 agent,那么通往 AGI 的唯一路径就必须经过更丰富、更逼真的交互式环境。这是在押注 Era of experience 这个宏大主题本身,而对冲了具体实现路径的不确定性。
RLaaS 的 Palantir模式会带来垂直行业垄断?
AI 时代更多公司在效仿 Palantir 的模式:通过 forward-deployed engineer 的方式,深入企业垂直领域,解决具体、高价值的业务问题。这个模式的执行路径非常清晰:
1.嵌入专家:将顶尖的 RL 工程师派驻到客户(如一家投行、一家制药公司)内部,与客户的业务团队紧密合作。
2.解决核心问题:利用 RLaaS 平台,为客户构建一个定制化的 agent,该 agent 的优化目标直接与客户最核心的业务指标挂钩,例如交易欺诈识别率、新药研发的成功率等。
3.构建专有数据飞轮:这个 agent 在客户的真实业务流程中运行,持续不断地从客户独有的、实时的运营数据中学习。RLaaS 平台负责管理和优化这个学习闭环。
4.形成护城河:随着时间的推移,这个由专有数据喂养的 agent 会变得越来越“懂”客户的业务,其性能将远超任何通用模型。它深度嵌入到客户的工作流中,形成了极高的替换成本。此时,RLaaS 提供商的角色已经从一个软件供应商,转变为一个不可或缺的战略合作伙伴。
这种模式极有可能在特定的垂直行业中催生出“赢家通吃”的局面。第一个成功将自己的 RLaaS 平台嵌入某个行业头部公司的服务商,将积累起该领域内无人能及的数据和领域知识优势使得后来者难以进入。因此,RLaaS 的未来格局,可能不是由一个巨大的平台所主导,而是由一系列在各自垂直领域内占据垄断或寡头地位的“小 Palantir”所构成。
排版:傅一诺
