中国开源模型,如何超越2025年
临近年底,全球大模型竞争已提前拉开2026年序幕。
在中国,MiniMax与月之暗面相继开源旗舰模型,百度高达2.4万亿参数规模的文心5.0正式登场,社区还在等待阿里的Qwen以及DeepSeek的下一步。在美国,OpenAI的GPT-5.1今日发布,谷歌的Gemini 3已经拉满预期,马斯克也曾预告Grok 5年底登场。
短短一年,中国开源模型从不为世界所知,崛起至让硅谷倍感压力。“价廉物美”是今年中国开源模型主调,甚至,部分模型可以打着“发布时间差”,宣告在选定测试基准上后发制人的超越。但随着商业化压力剧增,明年,开源与闭源相互攻防,将围绕着token经济学展开。
基准饱和,扩展不灵
过去一年,中国开源模型参与的全球AI竞争,核心叙事就是在训练与推理上花更少的钱,接近前沿模型的水平。随着内部混乱不已的Meta逐步退出竞争,中国已经赢了开源AI的竞赛;明年的目标是进一步缩小与最领先的闭源模型之间的性能差距。
市场对中国开源模型在部分基准测试中取得短暂领先感到兴奋。但这种“错觉”不会一直持续下去。一方面,开源模型更新频率更高,追赶差距往往只是发布时间的错位;另一方面,扩展定律边际放缓,也在为中国短期内逼近前沿打开了时间窗口。追赶者天然具备成本优势。
基准测试已经饱和。大模型的真实进步,越来越难被基准捕捉。行业正在吸取Meta在Llama4上的教训,拒绝以打榜基准为目标而主动“作弊”,但很多时候,模型被测试集“污染”的情况仍然难以避免。当模型在基准分数上差距越来越难以分辨,各家公司开始靠营销来“差异化”自己,进一步降低了基准公信力。这又放大了外界对开源模型测试成绩的质疑。某些情况下,第三方配置环境与参数的不同也会导致测试水平波动。
行业需要更新验证创新的基准,也需要重新探索创新的路径。硅谷大神卡帕西批评传统强化学习,只依赖最终奖励的强化学习,往往会误奖中间的错误步骤,也错过过程中的灵光一闪。中国研究团队也质疑,可验证奖励强化学习(RLVR)并未真正涌现超出预训练的推理能力。大模型对这个世界的理解,仍然是预训练数据集“分布内”的知识,但是,大模型预训练扩展定律却已经“死亡”。
行业正在探索新的可能。Transformer八子中的Ashish Vaswani,批评业界对后训练的沉迷是短期驱动,掩盖了预训练创新的长期改进空间;Llion Jones正在重新审视那些可以追溯到Transformer之前的想法。传言离开Meta的杨立昆,酝酿在世界模型领域创业,加入与李飞飞团队的竞争。但这些尝试都仍处于早期,解不了近忧。
创新“停滞”倒逼着商业变现,对AI泡沫的质疑愈发激烈。明年,开源模型与闭源模型的性能竞争,最终将落在token经济学之上。它与当前绝大多数评测基准没有直接关系。这次,OpenAI发布GPT-5.1,就已经跳出了这个数字游戏。一切,最终用户说了算,在工作场景中创造价值说了算。
token经济学
这一轮AI创新的基本元素是token。它的单位成本与消耗量决定了任务成本,任务的经济价值又决定了token的价值。当然,经济还涉及“周转率”。吞吐这些token的速度,决定着单位时间能创造多少价值。
中国开源模型仍在以极致性价比,向美国闭源阵营施压。目前,在Artificial Analysis的榜单中,最新发布的MiniMax-M2与Kimi-K2-Thinking,都处于性能表现略逊于GPT-5(high),但单位成本优势明显的象限内。其他处于这一象限模型,也大多出自中国企业之手。价廉物美是中国开源模型今年崛起的基调,明年也将如此。
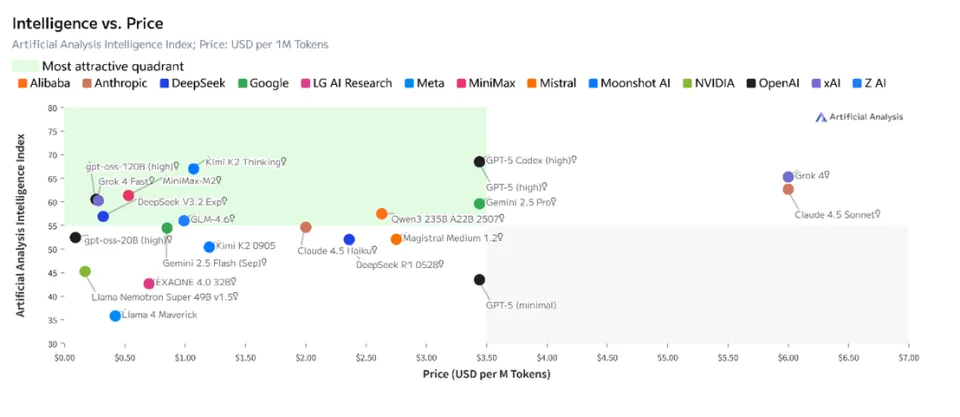
中国的这一优势,来自算力“卡脖子”的倒逼创新。为了突破算力限制,中国开源大模型普遍将自注意力机制等优化作为创新重点,尽可能地通过算法创新压榨芯片算力。DeepSeek与智谱还将语言压缩成视觉,以应对越来越长的上下文窗口。今年,DeepSeek带动了中国开源模型的快速迭代,也引发了一波又一波的价格战。明年,中国开源模型会不会进一步卷到自研模型的欧美企业数量进一步收敛?
但并非只有算法才会影响的token单位成本。AI芯片与内存、通信硬件的性能及其能效,也发挥重要作用。黄仁勋一直鼓吹“买得越多,省得越多”,就是从硬件与基础设施层面优化能效,降低运营成本的逻辑。这是美国的强项。
今年以来,中国开源模型已经开始推进软硬件层面的协同优化。蚂蚁集团在国产异构集群上完成了对2900亿规模参数Ling-Plus的训练,成本较H800降低20%;DeepSeek“指导”芯片与基础设施厂商针对性地优化,尤其是DeepSeek V3.2-Exp发布后,华为昇腾和寒武纪均第一时间宣布完成适配工作。明年,中国开源模型是否会交付一款完全基于国产算力技术栈的前沿开源模型?
但token的单位成本不是决定token经济学的一切。甚至,完成一项任务的总token成本,都不是上述因素所能完全左右的。
如果算力一定,那么,大模型的速度、性能与成本在实际工作负载中需要权衡。大模型的速度,包括延迟(Latency,即首个token的生成时间)与吞吐率(Throughput,即每个token的生成速度)等。中国开源模型在算力资源有限的情况下,要追平性能,价格更低,不得不牺牲部分速度优先级,这直接影响用户体验。事实上,很长一段时间,这也是Anthropic所面对的问题,直至今年它与亚马逊、谷歌深度绑定,账面投入数百亿美元,补上与OpenAI的算力差距。
此外,token单位成本优势还可能被“冗长思考”侵蚀。很多用户和开发者已经注意到,似乎DeepSeek-R1等开源模型,在回答问题时往往缺乏“节制”,使用了过多的token。尤其是简单问题,它想得过于复杂了。Kimi-K2-Thinking也犯了这个毛病,影响了用户体验,削弱了成本优势。月之暗面创始人杨植麟解释,现阶段该模型优先考虑绝对性能,token效率会在后续得到改善。
未来,在多智能体协作中,冗余消耗和记忆占用,短板效应会更加明显。OpenAI就非常重视这一问题,即使初期体验不佳,被用户指责“黑箱”,还是坚持让实时路由系统,根据对话类型、复杂度、所需工具和明确意图快速决定调用哪个模型。这次的GPT-5.1也不例外,它能更精准地根据问题调整思考时间。
声势强,商业弱
中国的开源模型正在赢得硅谷的青睐。无论AI基础设施层还是应用层的企业,都乐意在合适场景下部署或调用这些“够好用又够便宜”的模型。悬念在于,它们能否在不断增长的市场中,分得更大的一块。
中国开源模型确实能够创造价值。月初,在多模型API聚合平台OpenRouter上,对中国开源模型的API的调用,占据了20%以上的市场份额。它还没算上用户私有部署的开源模型。今年8月,中国开源模型的全球累计下载量就已经超越了美国。对于成本敏感的全球南方国家而言更是如此。上个月,彭博社惊呼中国AI模型正在非洲崛起,当地企业家齐聚一堂,聆听华为云撒哈拉以南非洲地区首席架构师宣讲DeepSeek。

中国开源模型往往会针对某些细分应用场景迭代。它们往往是基于业务数据积累与实际需求的微创新。今年,腾讯、阿里、字节跳动几乎同时开源了自己的翻译模型Hunyuan-MT-7B、Qwen3-MT与Seed-X-7B。针对特定市场的翻译问题远未解决,而且需求巨大,社交、电商等场景下高频调用,值得做到像编码模型这样专。共享民宿巨头Airbnb的CEO布莱恩·切斯基(Brian Chesky)就说,他们使用OpenAI的最新版本,但很大程度上更依赖于Qwen模型。非洲企业也反馈欧美模型对非洲语言的token切分并不合理。
但是,从价值创造总量看,中国开源模型仍然无法与美国前沿模型相匹敌,也难以撼动硅谷巨头的生态。开源模型的市场份额,并没有体现为这些企业的收入份额。年底,OpenAI的ARR或达200亿美元,Anthropic则有望实现90亿美元。没有一家中国初创企业可以达到这一体量,它们面临投资者的压力。
越来越多中国开源模型已经加入了智能体功能,这次Kimi-K2-Thinking就强化了工具调用能力。中国SaaS企业先天不足,明年,开源模型加持的智能体能否打开中国企业服务的市场?
事实上,规模就是创新。开源模型初创企业并不直接占有ChatGPT那样的海量用户数据,同时缺乏集中、持续的用户反馈机制,在长尾需求、细节优化与真实交互方面存在劣势。阿里巴巴与字节跳动等具备全栈技术、垂直整合能力与庞大用户生态的互联网巨头,可以通过赋能内部业务形成闭环,而初创企业很难逾越这一壁垒。
此外,尽管大模型在基准测试中考得越来越好,但诸多研究证实,它嵌入实际工作流的效果仍然不佳。Anthropic、OpenAI和Cohere正在招聘“前沿部署工程师”,以应对定制服务挑战。而开源模型厂商对此的响应更为困难。
2026年,开源仍然是中国的确定叙事。它意味着国产算力生态协同,也意味着科技普惠与自立自强。但是,开源模型的阵容或将随着商业闭环的推进而改写,美团、小米、蚂蚁等公司可能频繁地露脸。竞争品类的激增,将让更多欧美模型厂商承受价格压力,不断构建差异化体验,或者挤破泡沫。