为什么 LLM 搞不定复杂任务?ReAct 与 Reflexion 技术综述
推荐语
探索大语言模型处理复杂任务的新突破:ReAct与Reflexion技术如何解决LLM的局限性?
核心内容:
1. LLM处理复杂任务时的五大关键挑战
2. ReAct框架的"推理+行动"协同机制解析
3. Reflexion技术如何通过自我反思提升模型表现

杨芳贤
53AI创始人/腾讯云(TVP)最具价值专家
在人工智能领域,特别是大语言模型(LLM)的应用中,尽管模型在许多任务上表现出色,但在处理复杂任务时仍存在明显局限性。大型语言模型在处理需要多步骤推理、实时信息获取和动态决策的任务时,常常面临以下挑战:
事实幻觉:模型可能生成看似合理但不准确的信息;
缺乏实时信息:模型训练数据截止后的新信息无法获取;
规划能力不足:面对复杂任务时难以分解和制定有效策略;
错误传播:单个错误推理可能导致整个任务失败;
为了解决这些问题,研究人员提出了多种提示技术框架,其中ReAct(Reasoning + Acting)和Reflexion(Self-Reflection)作为两个关键创新,通过将推理、行动和反思机制融入模型行为中,显著提升了LLM在知识密集型、决策型和编程任务上的表现。
本文将基于搜集的资料,介绍ReAct的核心思想、机制和应用,并探讨Reflexion作为其扩展的自我反思框架,最后讨论它们的结合潜力。
ReAct框架:推理与行动的协同
ReAct的核心思想
ReAct框架由Yao等人于2022年提出,其名称源于"Reasoning"(推理)和"Acting"(行动)的结合。该框架的核心灵感来源于人类决策过程:我们不只是被动思考,而是通过思考制定计划、执行行动、观察结果,并据此调整策略。ReAct将这一过程应用到LLM中,使模型能够动态处理复杂任务。
推理(Reasoning):模型生成内部思考轨迹,例如"我需要先做什么,再做什么",类似于链式思考(Chain-of-Thought, CoT)。这有助于分解任务、制定计划和处理异常。
行动(Acting):模型生成可执行的操作,例如"搜索[关键词]"或"计算[表达式]",以调用外部工具(如搜索引擎或计算器)获取实时信息。
通过"思考 → 行动 → 观察 → 再思考"的循环,ReAct使LLM能够融入外部知识,避免纯内部推理的局限性。
ReAct解决的问题
传统方法存在明显短板:
链式思考(CoT):无法与外部世界互动,容易导致事实幻觉(Fact Hallucination)和错误传播。
仅行动(Act-Only):缺乏规划能力,在多步骤任务中表现不佳。
ReAct通过行动步骤验证信息、减少幻觉,并通过推理步骤分解复杂问题。在知识密集型任务(如问答和事实验证)中,ReAct优于Act-Only,并与CoT结合时效果最佳。在决策型任务(如文字游戏)中,它显著提升性能,尽管与人类专家仍有差距。
ReAct的运作机制
ReAct依赖于特殊的提示方法:
1. 从训练集选取案例,改写成"思考-行动-观察"(Thought-Action-Observation)的轨迹。
2. 将这些轨迹作为少样本示例输入LLM。
3. LLM模仿格式,生成自己的循环直到得出答案。
示例:
模型生成的 ReAct 轨迹(模拟):
实践应用
ReAct框架在多个领域都有广泛的应用场景,以下是一些典型的使用场景和实践示例:
在需要准确事实信息的任务中,ReAct能够通过外部工具获取最新信息,避免模型幻觉。
在需要多步骤规划和决策的任务中,ReAct能够制定策略并动态调整。
结合计算器等工具,ReAct能够执行复杂的数值计算和数据分析任务。
在客户服务场景中,ReAct能够根据用户问题检索相关信息并提供解决方案。
在编程任务中,ReAct能够通过搜索文档、执行代码片段来辅助开发,以爱码仕ai编程工具使用为例,ReAct框架被用于智能代码生成、错误诊断与修复、技术选型建议等场景。
初始化LLM和工具(如Web搜索)。
使用
initialize_agent创建代理。
Reflexion:ReAct的自我反思扩展
Reflexion的核心思想
Reflexion是一个强化学习框架,由Shinn等人提出,它通过生成语言反馈(口头强化)帮助智能体从错误中学习,而非传统标量奖励。Reflexion模仿人类反思过程,让模型在尝试后获得具体改进建议,如"上次搜索范围太宽,下次更具体"。
Reflexion的三大组件
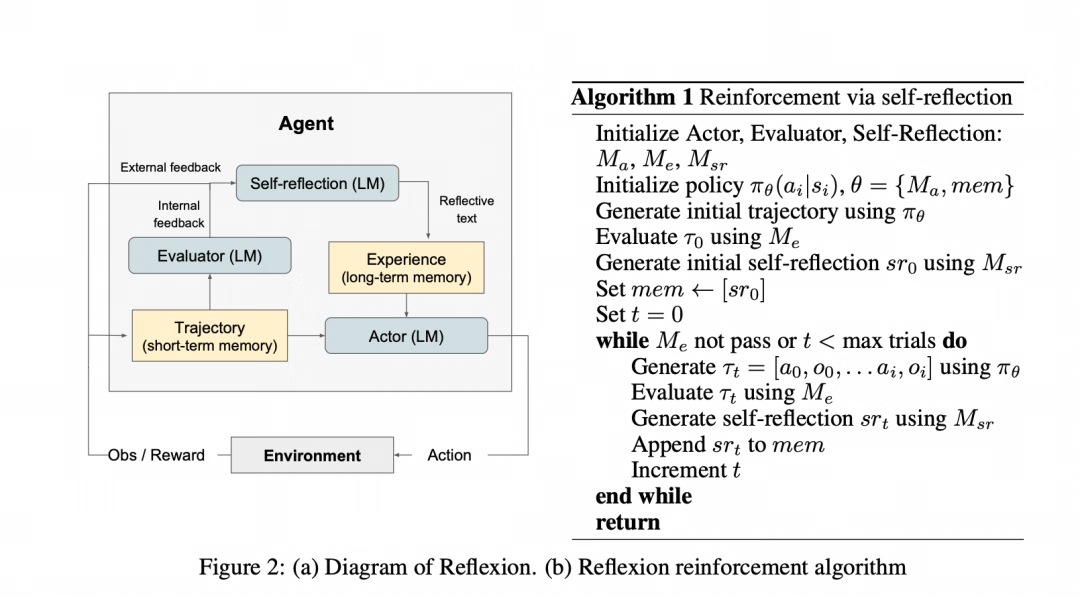
Reflexion构建在ReAct基础上,添加评估和反思机制,形成闭环:
参与者(Actor):基于ReAct或CoT生成行动轨迹。
评估者(Evaluator):对轨迹打分,判断成功或失败。
自我反思(Self-Reflection):核心组件,生成语言反馈并存入长期记忆,指导下次行动。
工作流程:行动 → 评估 → 反思 → 迭代。通过滑动窗口记忆,Reflexion保留反思内容,实现持续优化。
示例:
Reflexion 通过行动、评估、反思和迭代来优化响应。假设初始尝试失败,然后通过反思改进。
最终输出:详细步骤包括热水浸泡、添加洗洁精和小苏打、擦洗、冲洗和检查。
适用场景与局限性
Reflexion适合需要试错学习的任务,如决策、推理和编程。它计算效率高,无需模型微调,提供详细反馈和高可解释性。但局限包括依赖评估准确性、简单记忆机制,以及在非确定性编程任务中的挑战。
ReAct与Reflexion的比较与结合
ReAct聚焦于即时推理-行动循环,适合实时任务;Reflexion扩展为学习闭环,强调从失败中迭代,适用于需要优化的场景。两者结合(如在Reflexion中使用ReAct作为Actor)可发挥最大潜力:ReAct提供基础机制,Reflexion添加反思层,提升长期性能。
在提示技术中,这种结合减少了幻觉、提高了准确性,并增强了模型的自适应能力。
详细区别分析
虽然 ReAct 和 Reflexion 在示例中看起来相似(如两者都涉及思考-行动循环),但它们在机制和应用上存在关键差异:
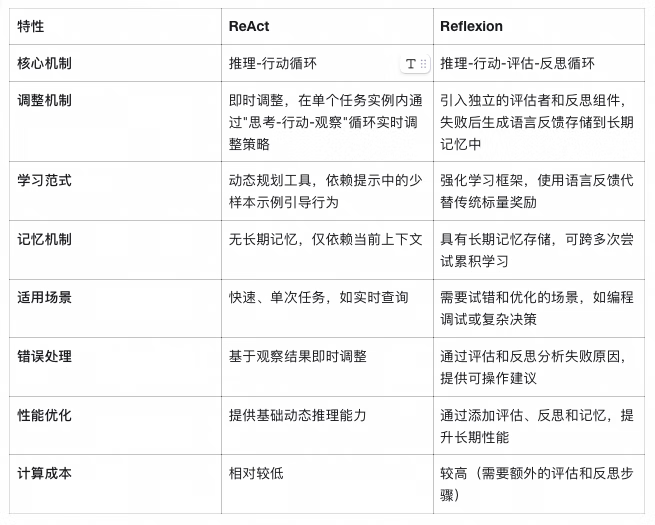
结合优势
在实践中,Reflexion 可以将 ReAct 作为其 Actor 组件,实现两者无缝结合:
ReAct 提供基础的动态推理机制;
Reflexion 添加评估、反思和记忆层;
结合后形成完整的"感知-行动-评估-学习"闭环;
总之,ReAct 提供基础的动态推理,而 Reflexion 通过添加评估、反思和记忆,将其提升为自适应学习系统。
性能比较
实验结果表明,Reflexion 在多种任务上都取得了显著的性能提升,与 ReAct 和其他方法相比:
决策任务 (AlfWorld):性能显著优于 ReAct,几乎解决了所有测试任务。
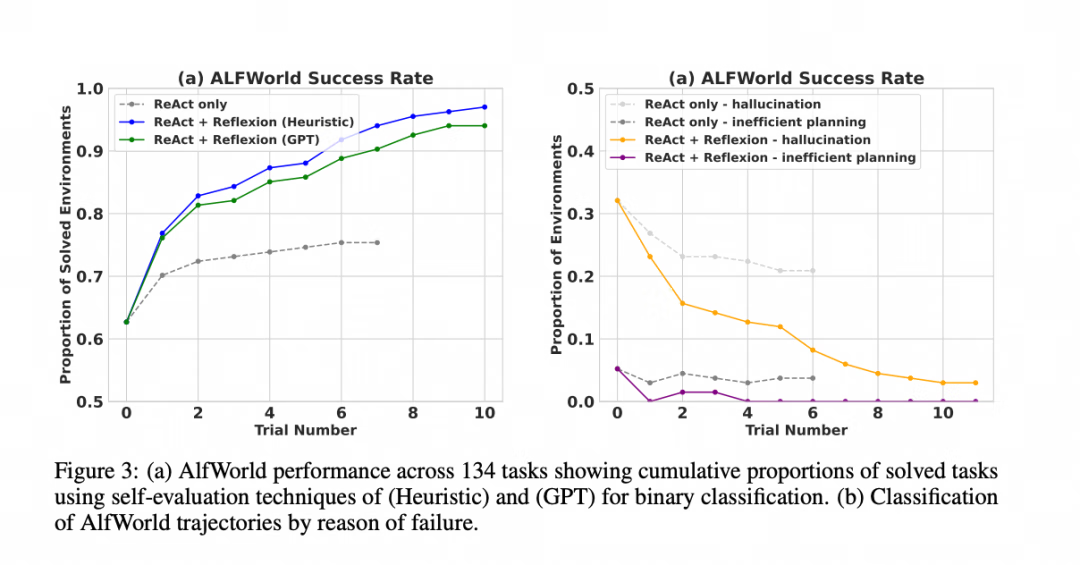
Reflexion Heuristic (启发式评估):本质上是一种简单、高效的硬编码逻辑(预先定义了一套成功或失败的规则,类似工程判断,快、便宜、黑白分明,但死板、僵化)
Reflexion GPT:使用一个强大的大语言模型(如 GPT-4)作为评估者(灵活智能、通用性强,但是贵)
推理任务 (HotPotQA):在几个学习步骤内,其性能就显著优于标准的 CoT 方法。
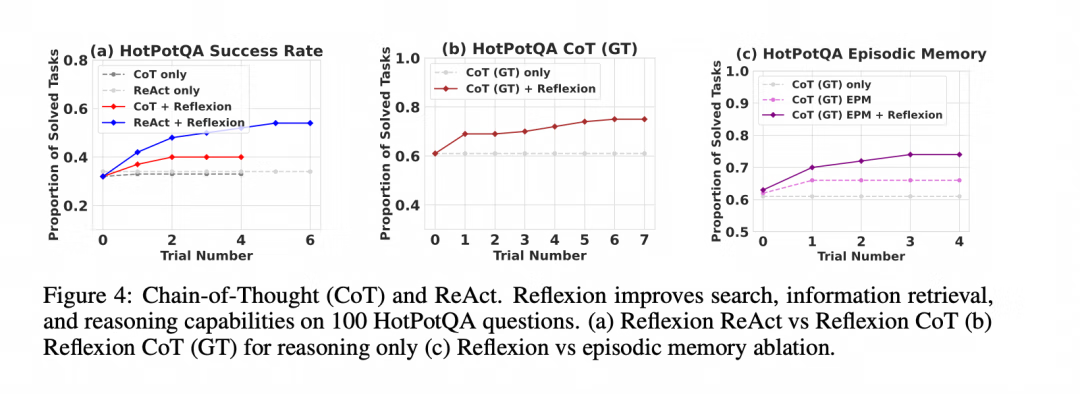
编程任务 (HumanEval 等):在 Python 和 Rust 代码生成任务上,通常优于之前的 SOTA (State-of-the-Art) 方法。
资料来源
https://arxiv.org/pdf/2303.11366
总结与未来方向
ReAct和Reflexion作为提示技术中的重要创新,为大语言模型在复杂任务中的应用提供了有效解决方案:
主要贡献
1.ReAct框架通过将推理和行动相结合,使模型能够与外部环境交互,获取实时信息,有效减少了模型幻觉问题。
2.Reflexion框架在ReAct基础上增加了评估和反思机制,形成了完整的"感知-行动-评估-学习"闭环,使模型能够从错误中学习并持续优化。
3.两者的结合充分发挥了各自优势,既保证了即时响应能力,又具备了长期学习和优化的潜力。
应用前景
随着大语言模型技术的不断发展,ReAct和Reflexion将在以下领域发挥更大作用:
智能助手:构建更智能的个人和企业助手,能够处理复杂的多步骤任务;
自动编程:辅助开发者进行代码编写、调试和优化;
科学研究:协助研究人员进行文献检索、数据分析和假设验证;
教育培训:提供个性化的学习路径规划和知识答疑;
未来发展方向
1.记忆机制优化:开发更智能的记忆管理机制,包括记忆的存储、检索和遗忘策略;
2.评估器改进:设计更准确、更高效的评估器,减少误判对学习过程的影响;
3.多模态集成:将ReAct和Reflexion与视觉、语音等多模态能力结合,扩展应用范围;
4.个性化适应:根据用户偏好和历史交互记录,动态调整策略和行为模式;
5.可解释性增强:进一步提高模型决策过程的透明度,增强用户信任;
通过持续的研究和优化,ReAct和Reflexion有望成为构建下一代智能系统的核心技术,推动人工智能在更多领域的深度应用。
Qwen-Image,生图告别文字乱码
针对AI绘画文字生成不准确的普遍痛点,本方案搭载业界领先的Qwen-Image系列模型,提供精准的图文生成和图像编辑能力,助您轻松创作清晰美观的中英文海报、Logo与创意图。此外,本方案还支持一键图生视频,为内容创作全面赋能。
点击阅读原文查看详情。
大模型技术原理大模型技术综述大模型技术架构