Memori:让 AI 拥有 "持久记忆" 的开源RAG引擎
推荐语
开源RAG引擎Memori为AI打造"持久记忆",解决LLM对话中的"失忆"难题,让AI真正记住用户需求。
核心内容:
1. Memori如何解决RAG开发中的三大痛点
2. 项目的五大技术亮点与创新设计
3. 从架构层面解析"记忆"功能的实现原理

杨芳贤
53AI创始人/腾讯云(TVP)最具价值专家
👆关注趣谈AI,后台回复“源码”获取源码实战
作者简介:
徐小夕,曾任职多家上市公司,多年架构经验,打造过上亿用户规模的产品,聚集于AI应用的实践落地。
最近推出了《架构师精选》专栏,会分享一线企业AI应用实践,并和大家拆解可视化搭建平台,AI产品,办公协同软件的源码实现。

最近发现了一个能解决 AI 开发核心痛点的工具 ——Memori。这个被称为 "AI 第二大脑" 的开源项目,正在用一种巧妙的方式解决 LLM 对话中 "记不住事" 的经典问题。

今天我们就来深度拆解这个项目,看看它到底有什么过人之处。
github地址:https://github.com/GibsonAI/memori

做 RAG 的朋友都知道:
向量数据库只存“外部知识”,对话一关就“失忆”;
提示词长度有限,历史记录一多就“断片”;
多租户场景下,用户隐私数据混在 prompt 里,极易泄露。
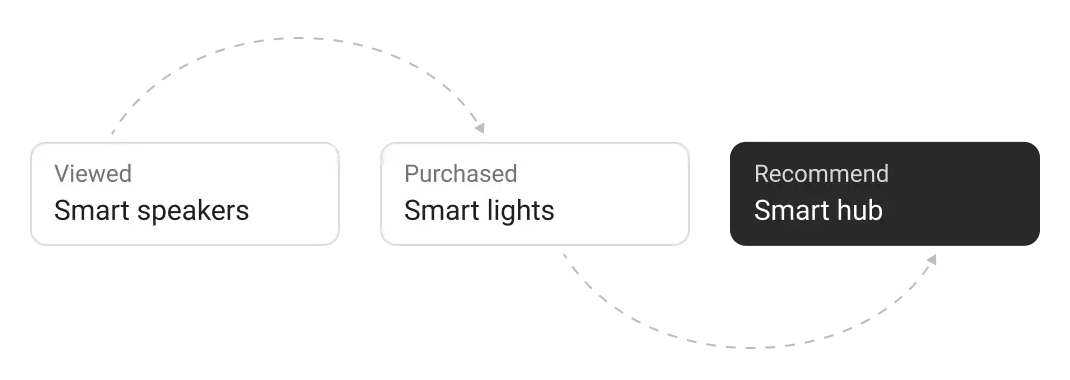
memori把“会话级记忆”抽象成独立层,让大模型在每次请求时自动携带“相关往事”,既省 token 又合规。一句话:给 LLM 装上“私人日记本”,且日记本归用户自己保管。
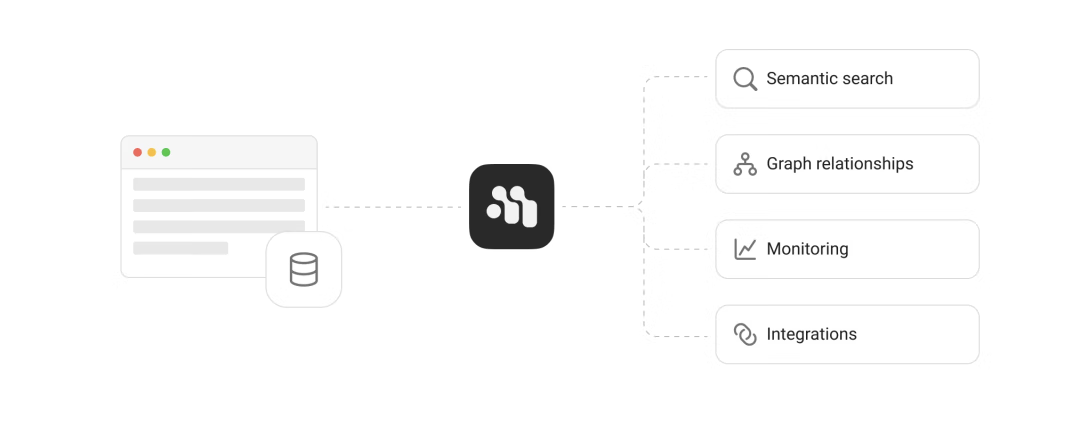
会话持久化:自动分段、去重、加密落盘。
零配置召回:基于 Hybrid Retrieval(向量 + 关键词 + 时间衰减),Top-K 自动可插。
多租户隔离:Namespace + 端到端 AES, SaaS 直接抄作业。
生命周期管理:支持 TTL、手动遗忘、GDPR 一键导出。
边缘部署:50 MB 内存即可跑,树莓派当“记忆盒子”。
理解Memori的架构,关键要抓住 "拦截 - 处理 - 存储" 这个核心流程。下面我总结了一个它的架构总览图:
我们可以把它拆成三个层面来看:
从项目结构看,Memori采用了高度模块化的设计:
这种设计的好处很明显:想加新数据库?改 database 模块;想支持新 LLM?加个 integration 适配器就行,核心逻辑不用动。
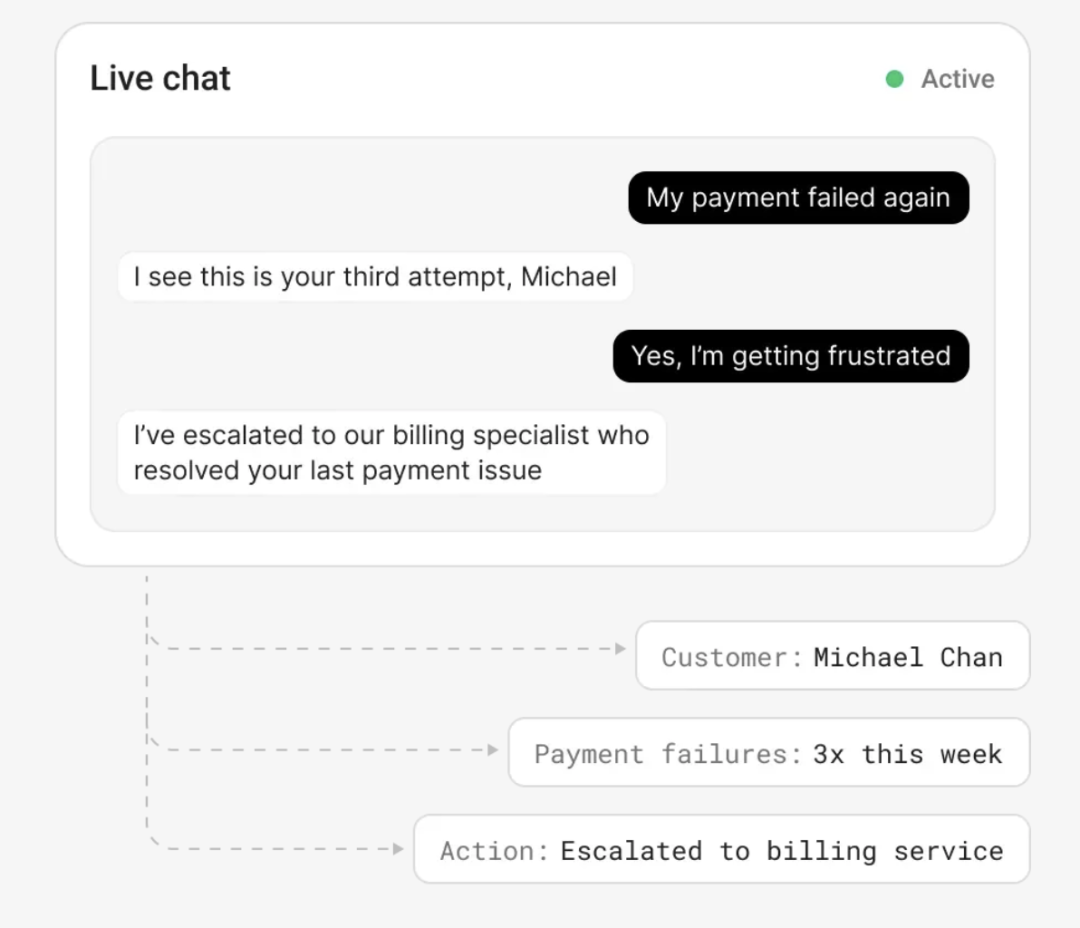
Memori支持两种记忆模式,这点我认为特别贴心:
我总结了一下Memori采用的技术方案,大家可以参考一下:
Memori的适用范围比我想象的更广,举几个典型场景:
AI 伴侣
连续聊天 30 天不重复劝睡
法律助手
案件材料按小时增量更新,律师随时追问“上次提到第 3 条证据在哪”。
官方 demo 里的 "个人日记助手" 特别有意思,它能分析用户的情绪变化和生活规律,提供个性化建议 —— 这就是记忆能力带来的进阶体验。
想亲手试试?3 分钟就能跑起来:
运行后会生成memori.db(SQLite 数据库),所有记忆都存在这里,下次运行还能复用。
在 AI 应用从 "单次对话" 走向 "长期交互" 的趋势下,Memori解决的 "记忆问题" 其实是个底层刚需。它的聪明之处在于:不用发明新的存储方案(直接用 SQL),不用复杂的集成步骤(一行代码搞定),却能实实在在降低 80% 以上的开发成本和 token 消耗。
对于开发者来说,这意味着我们能更专注于业务逻辑,不用重复造记忆系统的轮子;对于企业来说,数据存在自己的数据库里,既安全又灵活。
如果大家正在开发需要 "长期记忆" 的 AI 应用,或者受够了反复传递上下文的麻烦,不妨试试这个项目。开源社区也在快速成长,贡献代码或反馈问题,都是不错的参与方式。
关于架构专栏

开源大模型开源大模型是什么意思开源大模型有哪些