GPT-5.2,对Gemini-3反手一掌,2026做牛马比当学霸重要
你方唱罢我登场,各领风骚十几天。
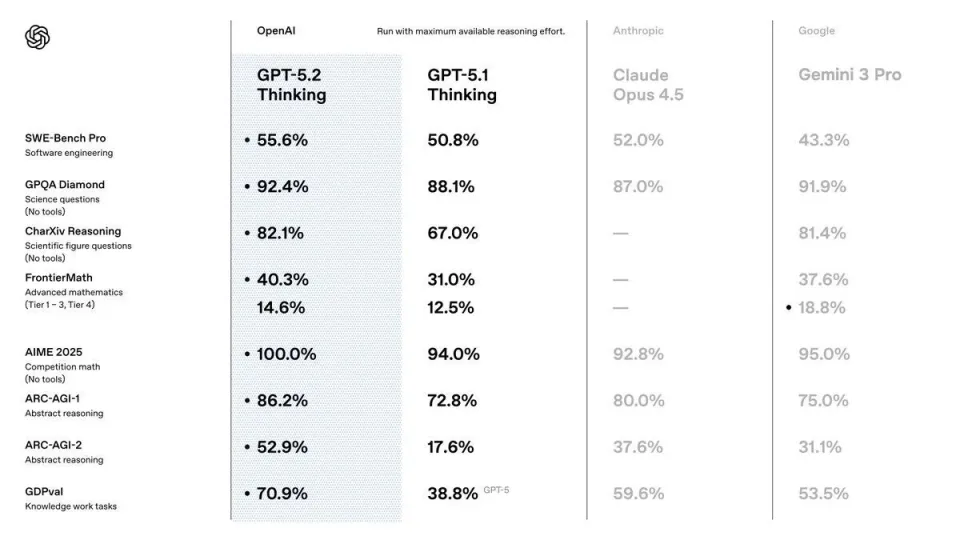
GPT-5.2出来了,它实现了对Gemini-3和Claude-4.5的部分反超,在多个实用领域都更强了:做表格、弄PPT、写代码、理解长文档、调用工具、处理复杂多步骤项目……视觉理解能力也大幅提升,能辨别出板卡上的螺丝钉。
(来源OpenAI)
从5.1到5.2,仅用了30天,OpenAI回答了市场上对其前景的质疑,证明了团队实力,预示了2026年,扩展定律依然是前沿大模型的竞争的最重要法宝,基础设施将起到更重要的作用。
OpenAI首次引入了它自己开发的打工能力的测评基准GDPval,要证明它既会做学霸,也能当牛马。
结果5.2成为首个达到或超过人类专家水平的模型。根据人类专家评审的结果,5.2 Thinking 在 GDPval 的知识型任务中,有 70.9% 的项目表现优于顶尖行业专业人士或持平。这些任务包括那些白领打工基本技能,如制作演示文稿、电子表格以及其他活儿。5.2 Thinking 的输出速度在 GDPval 任务中比专家快 11 倍以上,成本却不到其 1%。这表明,在有人类监督的情况下,GPT‑5.2 能有效辅助专业工作。
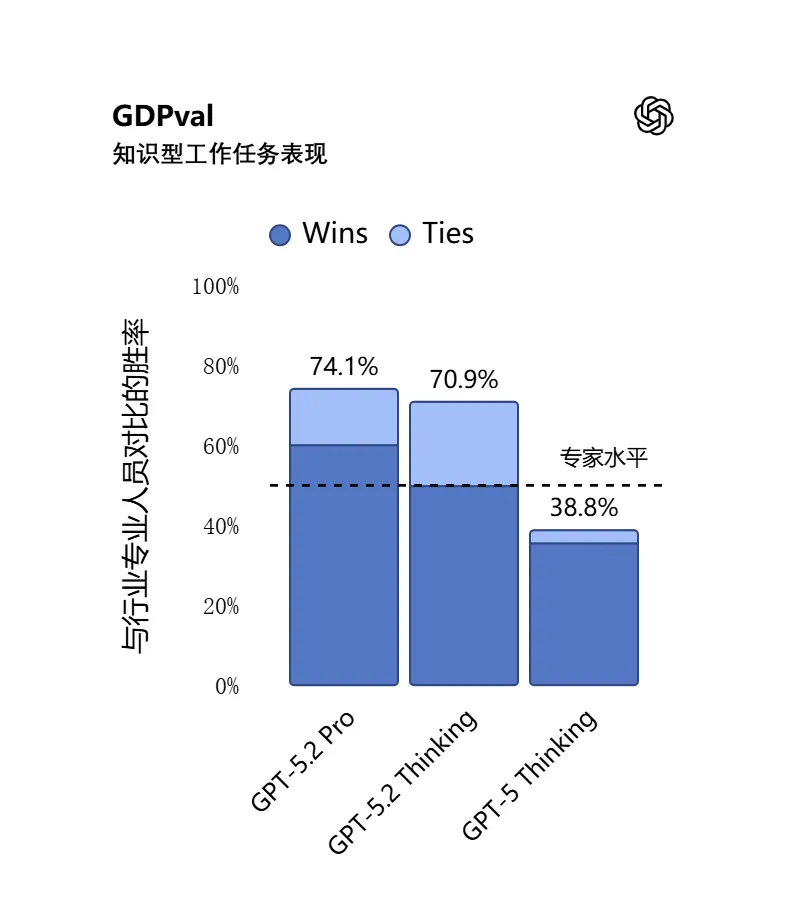
(在 GDPval 测试中,模型尝试完成定义明确的知识型工作,内容涵盖美国 GDP 贡献度最高的 9 个行业中的 44 种职业。任务要求生成真实的工作成果。)
两个半月前,OpenAI公布这个测评体系时,GPT-5的得分,不及当时的Claude最高版本Opus 4.1,但是胜过Gemini 2.5和Grok-4。如今,5.2得分几乎翻倍。
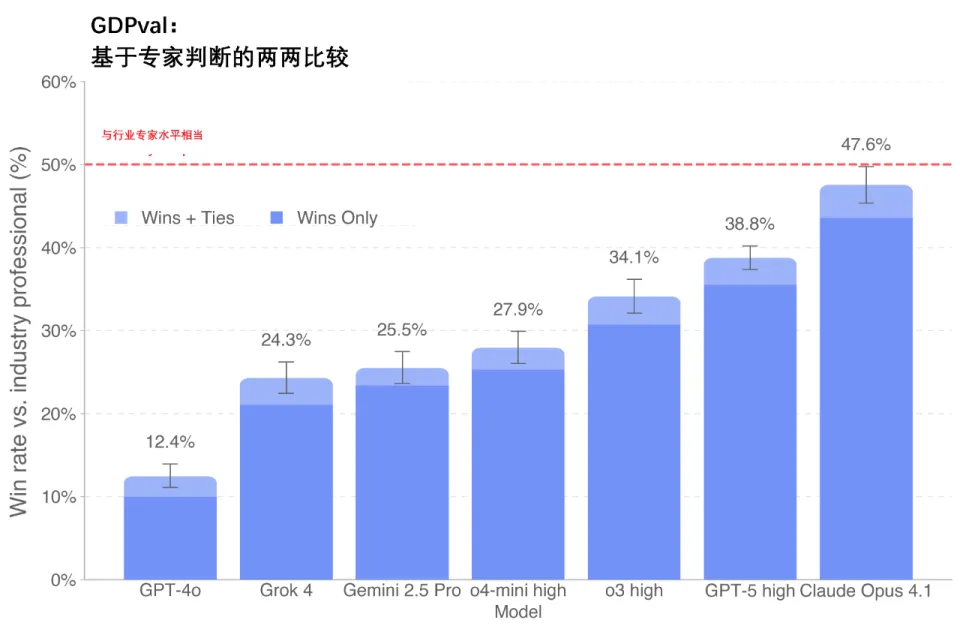
(来源OpenAI)
尽管如此,GPT‑5.2 Thinking想要在实际工作中替代OpenAI的员工仍然相当遥远。在最新系统卡(system-card)的AI自我改进(Self-Improvement)能力测评中,GPT‑5.2 Thinking并没有未达到一名表现优秀的中等资历(mid-career)研究工程师的水平。OpenAI 基于20个曾导致重大项目至少延迟一天的真实研发瓶颈问题,构建了OPQA 测试基准。结果,即使在可访问历史代码、日志和实验数据的条件下,GPT-5.2 Thinking仍缺乏有效诊断问题根源并提出合理解释的能力,它做得比GPT-5.1 Codex Max更差一点。不能自主发现、分析、解决新问题,意味着AI距离“自我改进”所需的能力仍有巨大差距。
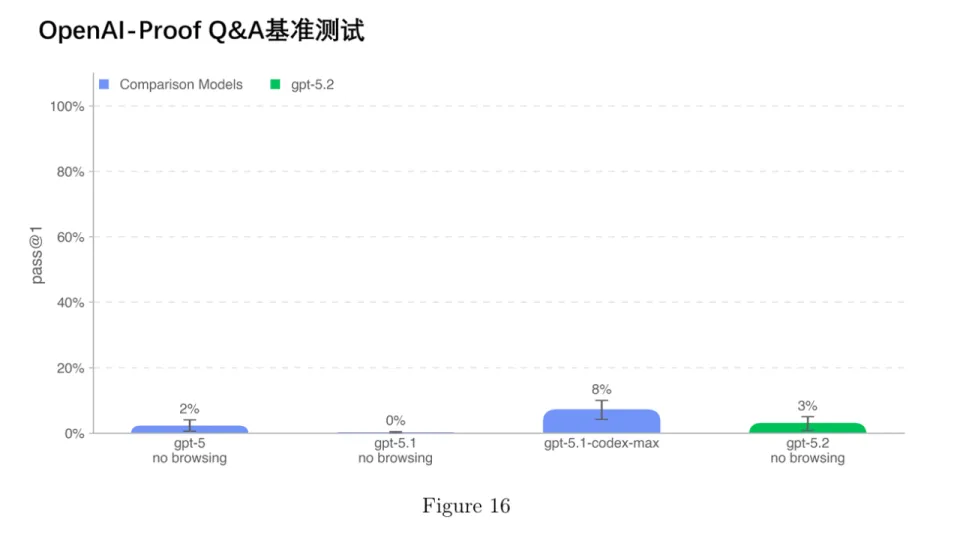
(来源OpenAI)
也就是说,大模型仍然是“高分低能”,干活出活能力,还没有摆脱最初级的水平。
但我们也不得不服前沿大模型的学霸级考试水平。ARC-AGI也在第一时间发布了测试结果。5.2的准确率高达 90.5%,每个任务的成本仅为 11.64 美元,一年内效率提升了约 390 倍。回顾过去 12 个月,在 ARC-AGI 测试中,任何超过 85% 的准确率都需要近乎疯狂的计算资源。早期对 o3-preview 的估算显示,每个任务的成本在 3000 美元到 3 万美元之间。基本上,每次想要得到一个答案,你消耗的算力成本相当于一辆汽车。现在GPT-5.2 Pro 登场,取得了 90.5% 的准确率,而价格却只相当于几杯咖啡。已经相当接近人类95%的水平了。
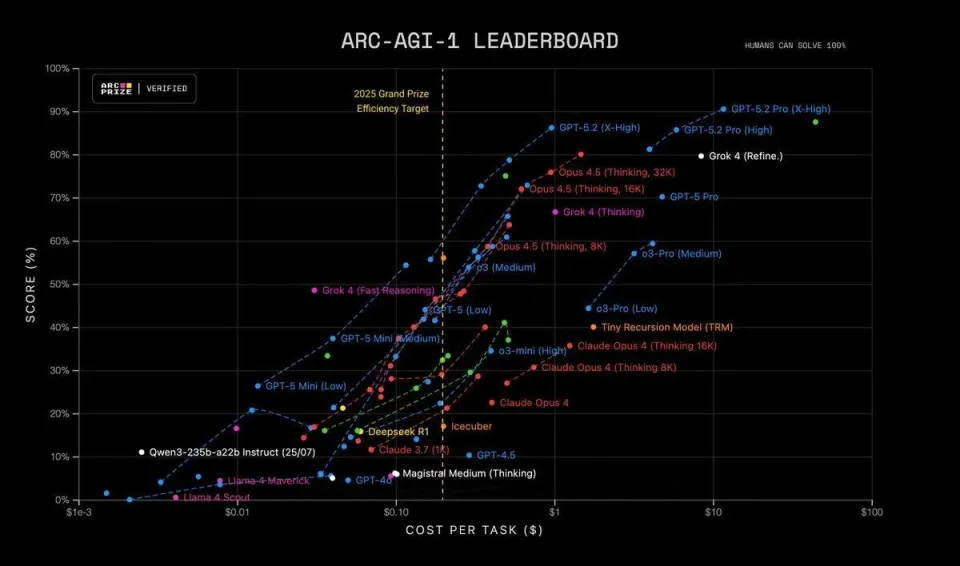
(来源ARC-AGI)
让智能体干活,我们正悄无声息地跨越与人工成本持平的界限,几乎无人察觉。整个推理的经济格局正在发生翻天覆地的变化。我们才刚刚开始,接下来会有更快的优化。
谷歌用TPU-6集群首次训练出最领先的前沿大模型Gemini-3,动摇了英伟达GPU一统天下的格局。Anthropic与谷歌TPU和亚马逊Trainium的合作,明年分别都达到了百万卡级。
OpenAI与xAI主要依靠英伟达GPU。这次OpenAI还披露,5.2 是其与长期合作伙伴英伟达和微软共同打造的成果。Azure 数据中心与 英伟达的 H100、H200、GB200-NVL72 等 GPU 构成了 OpenAI 大规模训练的核心基础设施,为模型智能带来了显著提升。“正是这种合作,使我们能够更有信心地扩展算力,并更快速地将新模型推向市场。”
这预示着到了2026年的大模型之争,也将是一场基础设施之争。今年砸下的数千亿美元,明年将实现滚滚算力。一代GPU,一代大模型。B200和B300的全面担当主力,英伟达Rubin CPX预计年底上市,专为长上下文推理和视频生成应用设计。还有TPU-7、Trainium-3的上市。大模型新一波扩展,值得期待。
小结一下,5.2对于明年意味着什么:
1,前沿大模型将会继续拼扩展定律,也就是拼基础设施。明年的下一代模型竞争值得期待。在基础设施门槛显著提升的情况下,明年中国的DeepSeek-3.x或4用什么基础设施预训练?
2,在这样的大模型竞争升级态势下,美国已经放开对中国H200的出口,它用来训练GPT-5,仍然起到了主力作用。这样,中国领先的开源模型,在训练阶段是否需要H200?
3,面向真实工作场景,扩展可验证性,建立相应测评基准,加快大模型的实际使用,实现其经济性,智能体完成复杂真实任务,将是明年一个竞争重点;也就是说,AI大模型公司拼ARR,比争当学霸更重要了。这也是中国快速学习、打分优异的开源模型需要直面的价值变现问题。
5.2各项能力的得分,最权威和最详细的,以及它的系统卡,可以看OpenAI官网的公布:
https://openai.com/zh-Hans-CN/index/introducing-gpt-5-2/
https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf