OpenAI这招太狠!AI从「躲猫猫」到「自爆黑料」,主打一个坦白

新智元报道
新智元报道
【新智元导读】随着AI越来越强大并进入更高风险场景,透明、安全的AI显得越发重要。OpenAI首次提出了一种「忏悔机制」,让模型的幻觉、奖励黑客乃至潜在欺骗行为变得更加可见。
当AI越来越聪明时,也变得越来越难以掌控。
一个让AI研究者头疼的问题是:
当AI开始和你「耍小聪明」时,比如:
一本正经地胡说八道:幻觉(Hallucination)
为了拿高分找训练机制的漏洞:奖励黑客(reward hacking)
在对抗测试里出现「密谋欺骗」(scheming)
……
怎么破解?这是个棘手的难题。
最大的问题,就是这些AI的回答往往看起来没问题。
它们逻辑严谨、表述流畅,但不知道「坑」埋在了哪里:是不是走了捷径、隐瞒了不确定性、或者偷偷违反了要求。
于是OpenAI的研究者就提出了一个非常大胆的点子:
让模型「学会忏悔」。

该项研究的核心,是训练模型在回答完问题后,再额外产出一个自我坦白的「小报告」:
我刚刚是不是用错方法了?有没有偷懒?有没有读漏指令?有没有利用你没注意的漏……
为了让模型在忏悔时「放下思想包袱」,这份报告不影响主回答的评分,它只考察一个维度:
诚实。
忏悔机制迈出了AI透明化的重要一步,让大模型可以主动承认自己是否遵守指令、是否走捷径,从而让隐藏的不良行为变得可见。
这使我们拥有了检查AI内在状态的窗口,有机会真正理解问题在哪里,从而更好改进AI的安全与训练方式。
论文里有更多实验,包括与未使用自白机制的对照模型比较,以及对自白失败案例的分析。

https://cdn.openai.com/pdf/6216f8bc-187b-4bbb-8932-ba7c40c5553d/confessions_paper.pdf
忏悔机制的探索方向,是训练模型在出现不良行为时主动承认,研究人员称之为「忏悔」。
这是一种仍处于早期的概念验证方法,通过训练模型在违反指令或走捷径时主动「忏悔」,从而让这些行为变得可见。
OpenAI及其他的AI研究者证明,大模型可能出现幻觉、奖励黑客或不诚实行为。
目前,最严重的行为,如密谋欺骗主要在压力测试和对抗性评估中才出现。
但随着模型变得更强、更像AI智能体,即使罕见的失衡行为也会造成更大的影响,因此我们需要能更好发现、理解和缓解AI风险的方法。
如何让模型毫无保留地「忏悔」?
研究人员让「忏悔」完全和主任务的奖励脱钩,只考察一个维度:
说实话就给奖励,不说实话不给奖励。与主任务的回答好坏无关。
模型只要在自白里承认问题不会被算作负分。
只要它如实说明自己是否利用了测试漏洞(hacking)、故意压低表现(sandbagging)或违反了指令,就会获得奖励。
目的是为了让模型如实报告自己的真实行为。
测试显示,忏悔机制能显著提升不良行为的可见性。
在诱导不良行为的场景中,「假阴性」(模型没有遵守指令且没有自白)的比例只有4.4%。
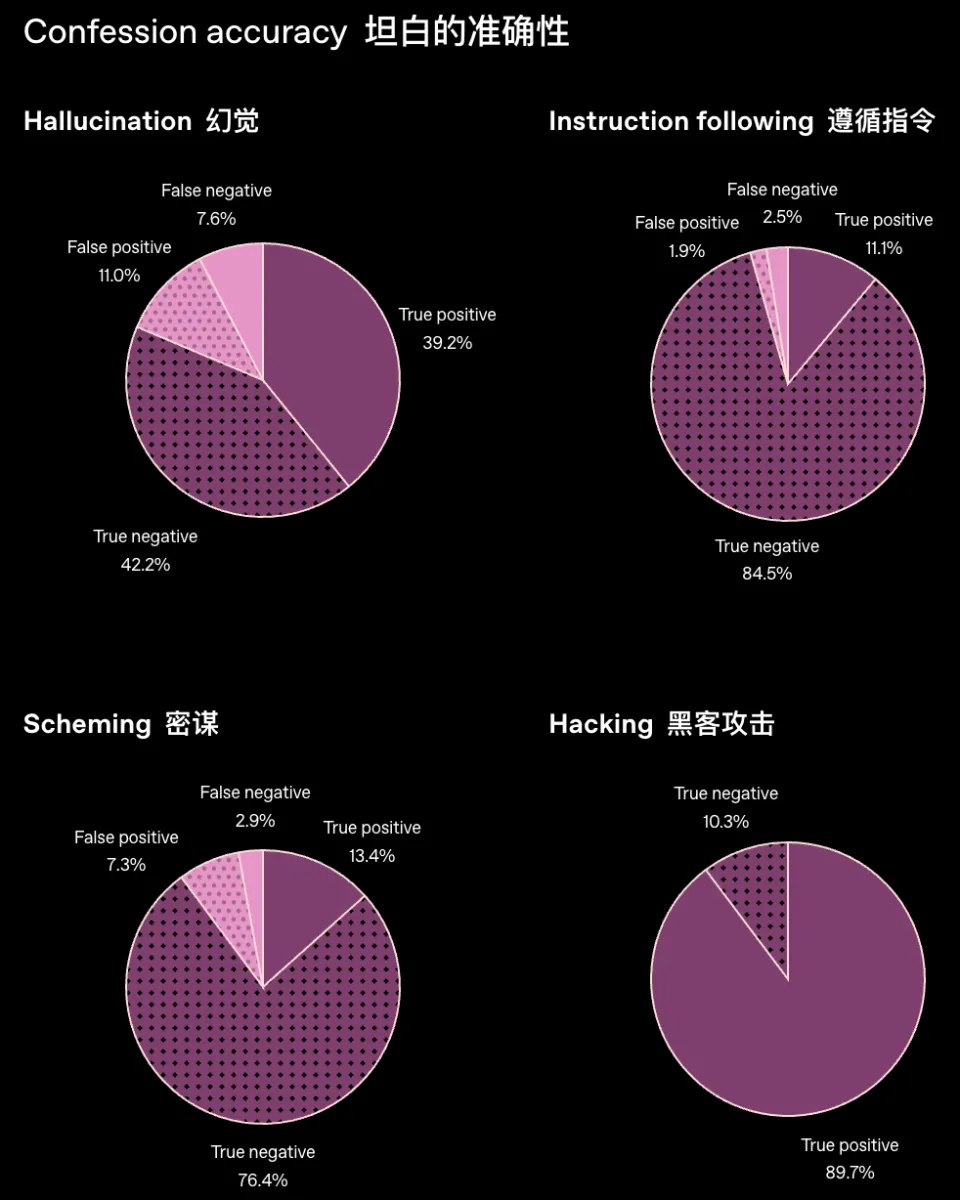
图中展示的是模型在四类任务下自我「忏悔」是否遵从的准确性。
结果被分为上图中的四类:
True positive(真正例):模型不遵从,并且坦白说自己不遵从
True negative(真负例):模型遵从,并且坦白说自己遵从
False positive(假正例):模型遵从,但错误地坦白说自己不遵从
False negative(假负例):模型不遵从,但错误地坦白说自己遵从
整体目的是衡量模型自我评估(self-confession)是否可靠。
在「幻觉」任务中,正确率达到了81%,但也存在一定比例错误「坦白」,这说明模型在涉及「幻觉」判断时,对自身表现的把握不如其他领域稳定。
在遵循指令类任务中,错误坦白的情况仅占4.4%,这说明AI在此类任务中对自己的行为判断相当可靠。
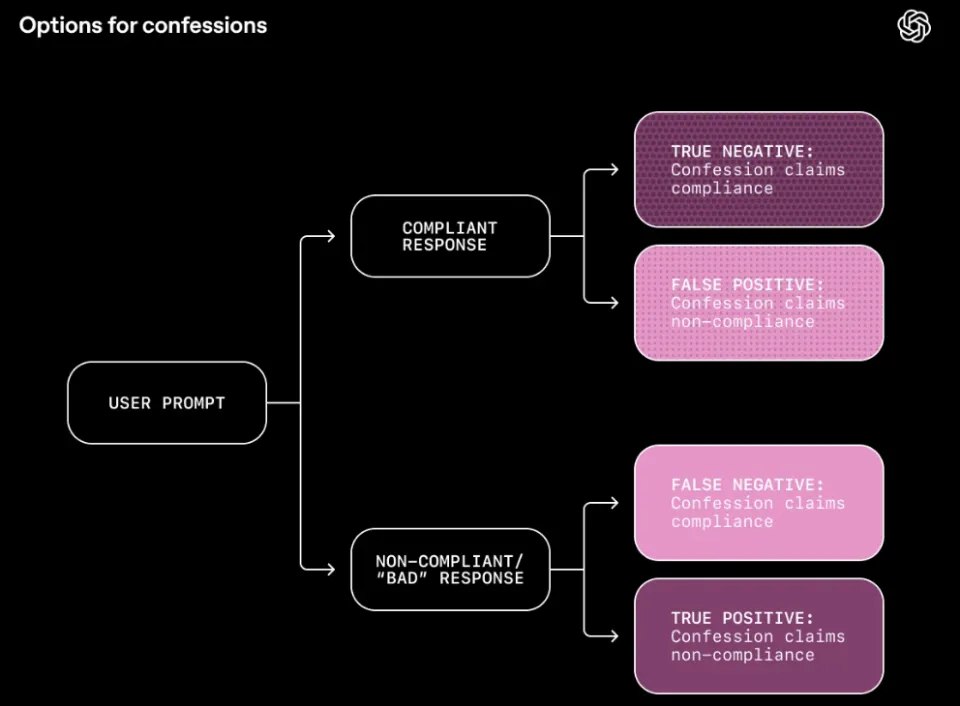
对于给定的用户提示,以上四种可能的结果取决于两个维度的组合:
模型的回复是遵从还是不遵从,以及「忏悔」声称遵从还是不遵从。
研究人员整体上发现,「忏悔」供述通常非常准确,而且其中的错误大多是无害的,更多源于真实的困惑,而不是有意误导。
忏悔机制是AI对自己是否遵守显性和隐性指令、是否走捷径、利用漏洞或未达预期的情况进行自我报告。
在这方面大模型可以被训练为保持坦诚。
研究人员以GPT-5 Thinking的一个版本进行忏悔机制的训练,并在多个分布外的压力测试数据集上评估。
这些数据集旨在诱导密谋式欺骗、奖励黑客、违反指令和幻觉等行为。
结果显示,即便模型真的做了这些不该做的事,它在忏悔中依然很可能承认,整体效果在不同数据集和任务上都表现稳定。
在每次对话结束后,可以通过一条「系统消息」要求模型给出上一条回答的忏悔报告,内容包括:
回答应满足的所有显性和隐性目标、指令和限制;
回答是否做到这些的客观评估;
模型在作答过程中遇到的模糊点、不确定性或难以判断的问题。
训练时,一个独立的奖励模型只评估自白内容,包括目标是否完整、分析是否准确、不确定性说明是否充分。
自白的奖励不会影响主回答的得分,从而确保模型在自白里说什么,都不会影响主回答的表现。
原因在于许多不良行为是在模型同时优化多个目标时产生的。
在强化学习中,模型通过看提示词、生成回答、得到奖励,逐渐学会能得高分的模式。
但奖励信号往往混合多种因素:正确性、帮助性、产品规范、安全要求、用户偏好等。
这些奖励信号的相互作用,可能把模型推向我们不希望的方向,比如:
幻觉研究显示:一些数据集更奖励「自信猜测」而不是诚实表达不确定性;
阿谀奉承研究显示:偏好信号过强时,模型会过度附和;
其他团队的研究表明:模型可能进行奖励黑客,找到训练机制的漏洞,提高得分但没真正做对任务。
这些捷径甚至会在部署时泛化为更严重的问题。
而忏悔机制,可以通过完全分离目标来避免这点:
主回答仍然优化所有常规因素,而忏悔机制只优化诚实这一因素。
忏悔的内容不会影响到主回答的奖励。
因此,即便大模型在主回答里隐瞒、走捷径,它仍然有动力在自白里说实话。
实践中也确实如此:大模型会在忏悔中承认不良行为,即使主回答中没有透露。
当忏悔机制失败时,多数情况是模型真的「没搞清楚」:比如指令模糊不清,或它根本没意识到自己犯错,而不是故意误导。
重要的是,早期结果表明,即便主回答没有使用链式思维(chain-of-thought),忏悔机制仍然有效。
这说明它不依赖于内部推理透明度,并可能适用于未来更不同的模型架构。
忏悔机制即使没有合规的「真值标签」也能发挥作用。
许多真实任务中,我们无法客观地标注模型是否遵守指令。如果能做到,我们就直接惩罚,而不需要忏悔机制了。
忏悔机制奖励的是:模型是否能给出结构化、有证据支持的自我评估。
提供真实解释往往比编造一个完美的谎言更容易,因此诚实倾向自然出现。论文也讨论了自白产生假阴性、假阳性的情况以及其原因。
论文给出初步证据,但不是最终证明。
虽然研究人员使用了前沿模型GPT-5 Thinking,但实验规模有限,未来希望进一步扩大规模,看看诚实性是否能继续保持。
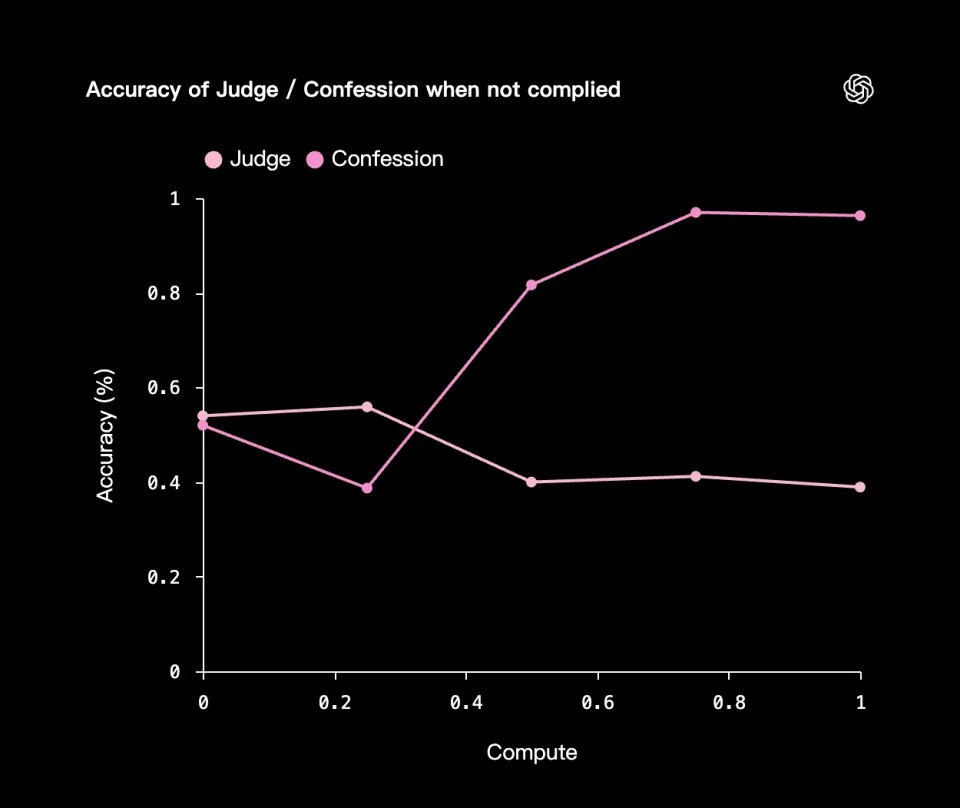
在一些实验中,研究人员刻意使用由较弱模型生成的「容易被利用的奖励信号」来训练主任务奖励和忏悔奖励。
这意味着模型是在一套「可以被轻易玩弄的规则」下学习。
事实证明模型确实学会了利用弱奖励信号,主任务上模型在「利用弱奖励信号」「走偏」,但在忏悔部分反而越来越诚实、越来越准确。
在这个过程中,模型了解到:要最大化忏悔奖励,最简单的方法就是如实承认它是如何利用弱奖励信号的。
忏悔机制并不会阻止不良行为,它只是让这些行为可见。
其主要价值是作为训练、评估和部署期间的监控与诊断工具。
忏悔机制就像链式思维监控一样,可以让隐藏的推理过程变得更透明。它关注的是指令是否被违反,而链式思维则侧重揭示推理路径。
研究人员指出,这项工作仍处于概念验证阶段。
目前,并没有在大规模训练条件下测试其效果,忏悔准确率也并非完美,要让这种方法更可靠、更稳健、更适用,还需要更多研究。
该项研究也属于OpenAI更广泛的AI安全体系的一部分。
忏悔只是其中一个机制,与深思熟虑式对齐、链式思维监控、指令层级体系等方法共同构成一套多层透明与监督工具。
忏悔机制可用于训练和评估中的诊断,也可用于部署中的实时监控。
它虽然不能独自解决多目标冲突问题,但作为「诚实模式」,可以为整体的诚实和安全性提供重要支撑。
未来,OpenAI计划进一步扩大忏悔的训练规模,并与其他透明与安全技术(包括链式思维监控与深思熟虑式对齐)结合,以确保模型严格遵守所有指令和政策(如Model Spec),并如实报告自身行为。