从英伟达收购Groq,看甲子光年报告预言“非GPU”崛起 | 甲子光年智库
就在2025年,这个全球AI芯片行业波澜壮阔的年份行将结束之际,GPU游戏规则制定者英伟达又做了一件近乎疯狂的事情:掏出手头三分之一的现金储备,用三倍溢价买下一个曾经扬言三年内要超越它的“对手” ——可重构数据流芯片公司Groq。业界震惊了,戏称行业老大哥 “ 豪掷200亿美金买了一个芯片IP ” 。
然而,这一切的发生似乎早有征兆,从2025年4季度开始,谷歌的TPU,作为非GPU芯片的另一代表,接连 “抢下” 原本属于英伟达的一批大客户;中国科技产业智库「甲子光年」在其年末发布的《2025人工智能产业30条判断》中,也惊人地预言了这场算力迭代——“非GPU”阵营全面崛起,正成为资本与巨头争抢的焦点。
如果说在此之前,“非GPU”还只是一个纸面概念,那在英伟达真金白银投下自己的“选票”之际,一个清晰的拐点已经显现:GPU单纯依靠工艺迭代和规模扩张的“暴力计算”时代正在落幕,以效率、灵活性和经济性为核心的“架构创新”正在行业巨头、资本、市场的共同托举下,站到了全球AI芯片舞台的正中央。在这场重塑算力格局的变革中,中国本土的先锋力量,凭借与Groq同源的可重构数据流架构,是否也将会有一席之地?
2025算力焦点:从GPU到TPU,再到“高阶TPU”
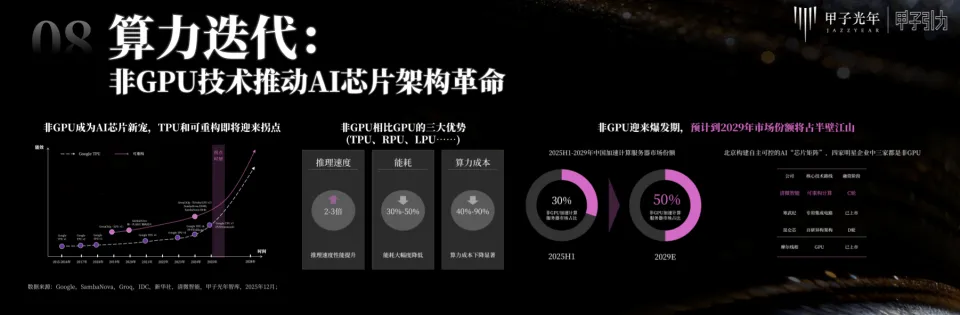
AI芯片的技术演进路径正从底层架构开始发生根本性变革。【甲子光年】报告指出,AI芯片已明确分化为“GPU”与“非GPU”两大阵营,而后者正从补充角色转变为挑战者。
这一趋势的底层逻辑,源于大模型产业化落地对算力提出的新要求:推理需求爆发、能效比成为核心成本项、应用场景碎片化。
传统GPU作为“通用计算”的王者,其基于图形处理演进而来的“共享式集中计算”架构,在应对上述新挑战时日益显露疲态,如内存带宽瓶颈导致的“内存墙”、高功耗以及为通用性付出的硬件冗余。
因此,非GPU路径以其为AI计算“量身定制”的效率优势强势崛起,且已形成两大技术流派。
一种是以谷歌TPU为典型代表的ASIC。通过硬件与算法的深度固化绑定,在特定任务上实现极致能效,堪称“计算特种兵”。但其灵活性是天然短板,难以适应算法的快速迭代。
而另一条创新架构路线则是以Groq以及国内清微智能为代表的可重构数据流。其核心是“软件定义硬件”,芯片内部的硬件资源可通过软件指令实时重组,像一条可以随时调整工序的智能流水线。它兼具了接近ASIC的高效能与媲美GPU的灵活性,被业界视为“高阶TPU”或“通用型TPU”。
此次英伟达收购Groq,表面是对推理场景的能力短板的补齐,本质是对GPU这一本不是为大预言模型原生开发的架构的极力救赎。
效率即正义:可重构架构的“降维优势”与数据验证
可重构数据流架构的价值,直接体现在对传统方案形成“降维打击”的关键性能数据上。这些优势并非实验室理论,而是正在转化为商业竞争力。
「甲子光年」报告中,通过将主流AI芯片置于同一基准测试平台进行对比,清晰地展现了不同架构间的效率差异。
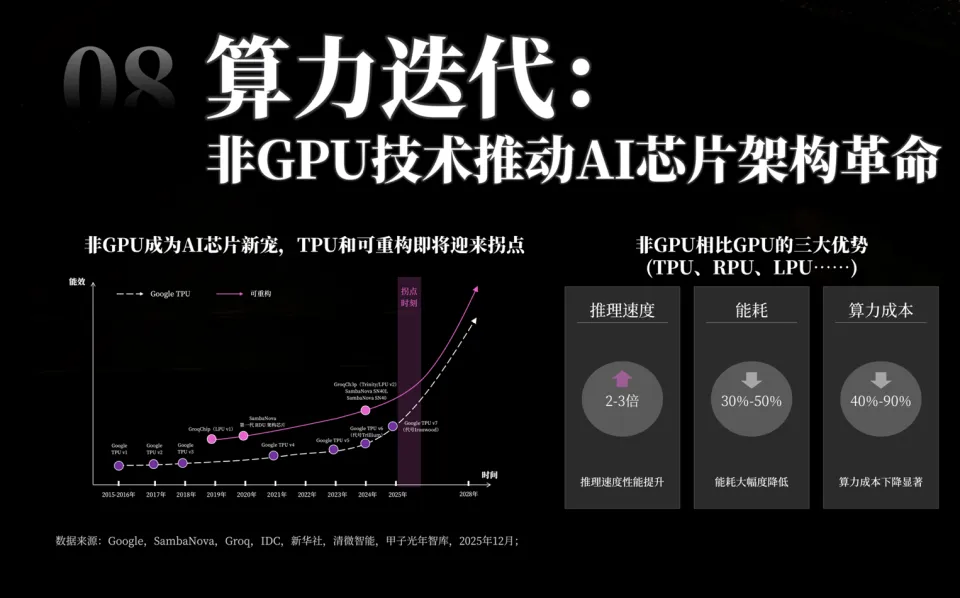
在推理速度与延迟上:凭借“流式处理”和硬件动态适配算法的能力,可重构芯片能够大幅减少不必要的数据搬运和调度开销。在处理大语言模型推理等序列任务时,推理速度可提升2~3倍,实现近乎实时的反馈。
在能耗与能效比上:由于硬件资源可根据算法精准配置,避免了GPU中大量通用计算单元的闲置功耗。甲子报告数据显示,在执行同类AI负载时,其能效比显著提升,可比同级GPU方案降低30%至50%。这对于建设大型数据中心以及国家倡导的绿色能源而言,意味着巨大的运营成本节约。
在综合算力成本上:高效的架构直接转化为更优的经济性。在规模化部署场景下,更高的利用率和更低的功耗共同作用,使得其全生命周期(TCO)算力成本有望低于传统GPU方案40%-90%,为核心行业用户提供更具性价比的选择。更为重要的是,可重构架构在非GPU阵营中实现了一种独特的“全能平衡”。它有效弥补了TPU在灵活性上的不足与LPU在应用范围上的局限,真正实现了“一芯多能”。当前,可重构架构芯片已在推理领域展现出显著优势,同时对AI大模型训练任务的支持也正成为其关键演进方向。这些特质共同使其成为应对复杂多变AI算力挑战,且极具竞争力的架构选择。
中国赛道:非GPU的“半壁江山”与清微的“范式引领”
这场全球性的架构革命,为中国AI芯片产业实现“换道超车”提供了历史性机遇。
「甲子光年」报告预测,中国非GPU加速服务器市场未来将迎来爆发式增长,其市场份额预计将从2025年上半年的约30%,飙升至2029年的50%,真正占据半壁江山。

这一预测的背后,是中国市场对算力性价比的极致追求,以及构建自主可控算力底座的坚定战略。
国内产业高地的布局已清晰指明了方向。以北京市构建的自主可控AI“芯片矩阵”为例,其重点布局的四家核心芯片企业中,三家选择了非GPU技术路线。这种“三比一”的结构,是国家与产业资本对下一代算力技术路线的前瞻性投票。
该图片疑似AI生成
在这幅由非GPU技术绘就的未来蓝图中,清微智能的战略价值日益凸显。
清微所深耕的可重构数据流架构,与此次被天价收购的Groq所代表的技术方向一致,底层技术逻辑均为“软件定义硬件”,其精髓在于硬件能够根据瞬息万变的计算任务动态重组,构建出最高效的专用通道,天然契合AI算法并行、流式、密集的核心特质。因此,它不仅仅是一种芯片设计,更是一条能够同步释放“架构优化”与“先进封装”双重红利的路径,是面向未来AI算力瓶颈的底层破局者。这条技术路径的价值,已在市场实践中得到验证。 目前,清微智能芯片已在全国十余个千卡智算中心实现规模化落地,算力卡订单累计超3万张,芯片总出货逾3000万颗。历史经验表明,每一次计算范式的转移,都会重塑产业格局。从CPU到GPU的过渡,成就了英伟达;而今,从固定架构到动态可重构的进化,正在打开一扇更广阔的大门。
对于眼下的中国芯片产业而言,一轮以市场需求为牵引、以架构创新为支点的“换道超车”战略机遇,正清晰地展现在眼前。