F1暴涨20分,推理速度恒定!新架构VGent:多目标定位又快又准

新智元报道
编辑:LRST
【新智元导读】多目标(Multi-target) 以及 视觉参照(Visual Reference) 为视觉定位(Visual Grounding)任务的推理速度和性能同时带来了全新的挑战。 为了解决这一难题,来自UIC和Adobe的研究团队提出了VGent模型。这是一种兼顾速度与性能的模块化设计,旨在将模型的推理与预测能力解耦,并辅以多种模块化增强方案 。最终,VGent凭借不到16B的参数量,在多目标及带视觉参照的视觉定位基准(Omnimodal Referring Expression Segmentation, ORES)上,大幅超越了Qwen3-VL-30B,实现了平均+18.24 F1的巨大提升!
在多模态大模型(MLLM)时代,视觉定位是MLLM细粒度推理能力的重要一环,同时也是实现人机交互和具身智能的核心能力。
现有的解决方案主要分为两类:
原生Token派(Native-token):像 Qwen2.5-VL 或 Ferret-v2 这样的模型,通过自回归(auto-regressive)的方式利用原有的词表逐个生成边界框坐标 。这种方式不仅速度慢(推理时间随目标数量线性增加),而且在多目标场景下容易产生幻觉(Hallucinations),即模型可能会在列举完所有目标对象之前就过早停止,或者在目标密集的场景中陷入无限生成的死循环。如图一所示,随着目标数量的增加,这类方法在多目标场景下的低效和不稳定性变得尤为明显。
新增Token派(New-token):另一类方法尝试通过引入特殊的token(如[SEG]或 object token)来指代目标物。他们需要收集大规模的数据集、从LLM起重新构建一个能理解这些新增token的MLLM。因此,这种方法不可避免地会破坏LLM在预训练阶段获得的通用推理能力。更严重的是,其导致无法直接利用现有的、先进的、进行了更大规模预训练的开源MLLM(如 QwenVL系列)。
来自UIC(伊利诺伊大学芝加哥分校) 和Adobe的研究团队提出一种模块化的编码器-解码器(Encoder-Decoder)架构VGent,其核心思想是:将高层的语义推理交给MLLM,将底层的像素预测交给目标检测器(detector),最终通过hidden state将这种解耦后的关系进行连接。

论文地址:https://arxiv.org/abs/2512.11099
研究人员认为,语义推理和精准定位是两种截然不同的能力,强迫训练一个单一的整体模型去同时精通抽象的语义推理和像素级别的底层预测,会导致性能和效率上的权衡。
更符合直觉的方式,应该是由不同的组件做各自擅长的事。
基于这一洞察,VGent提出了一种模块化的编码器-解码器设计,利用现成的MLLM和detector将高层多模态推理与底层预测解耦。
其核心理念在于MLLM和detector的优势是互补的: MLLM擅长多模态语义对齐和推理,而detector则擅长高效地提供精准的多目标检测框。
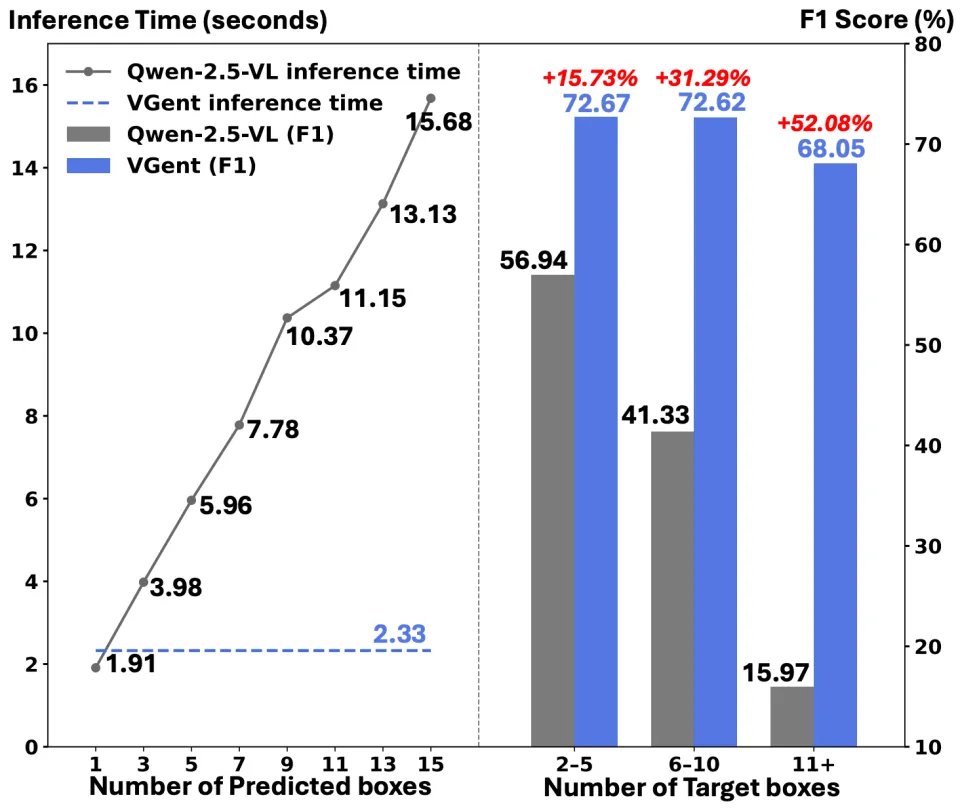
图一:VGent(蓝色)与现有先进的MLLM(Qwen2.5-VL,灰色)在多目标视觉定位任务上的对比。左图显示VGent的推理时间恒定且迅速,而 MLLM 随目标数量增加呈线性增长;右图显示VGent在F1分数上实现了显著提升,特别是在多目标场景下。

方法

基础架构
VGent主要由图二所示的encoder和decoder两部分组成,并引入了三种模块化增强机制(图三、四和五)。
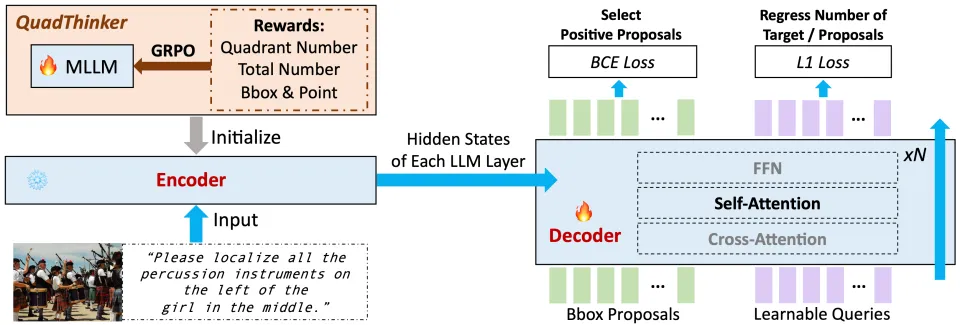
图二:VGent框架概览
如图二所示,左侧encoder是一个 MLLM,使用QuadThinker来提升其多目标推理能力。冻结的encoder输出hidden states并存储下来给到decoder。右侧decoder初始化自encoder的LLM 层,其将detector生成的object proposal作为query,通过cross-attention与encoder的hidden states交互。
研究人员在decoder内部新增了self-attention层(参数初始化自同一层的cross-attention),用于促进query之间的信息交流。 最终的输出进行yes / no的二元判断来选择每个proposal是否属于目标。相应的segmentation mask则通过 prompt SAM 得到。
QuadThinker:强化多目标推理能力
针对MLLM在多目标场景下推理能力下降的问题,研究人员提出了一种基于 GRPO 的强化学习训练范式QuadThinker,通过设计特定的prompt和reward functions,引导模型执行区域到全局、分步推理的过程:先分别统计图像四个象限内的目标数量,再汇总总数,最后预测具体坐标。

图三:QuadThinker所使用的prompt。
Mask-aware Label:解决检测与分割的歧义
在多目标场景中,检测(Box)与分割(Mask)任务的定义存在一定的差别。检测通常优化「一对一」的匹配,而分割则旨在召回所有前景像素。

图四:Mask-aware Label示意图。基于IoA的标签分配策略能召回被传统IoU忽略的细粒度部件。
这种差异导致了标注歧义:例如图四(左)中,检测器可能将「鹿头装饰」与其「挂绳」视为两个独立的框。
在检测任务的 IoU 标准下,由于挂绳的框比较小、相对于整体真值框的重叠率过低,往往会被当作负样本在标注阶段被过滤掉(被标上负标签)。但是对于分割任务来说,这个挂绳属于前景,其应该被标上正标签。
为此,VGent引入了Mask-aware Label,使用IoA (Intersection-over-Area) 指标进行额外的标签分配。如图四(右),IoA通过计算候选mask (通过proposal prompt SAM得到)与多目标真值的union mask的交集,并除以候选mask自身的面积得到。
因为IoA的分母是候选mask自身面积,该机制能精准召回那些虽然只覆盖了部分目标群(如细小的挂绳)但依然有效的 proposal。模型使用另一个独立的MLP head专门预测这种分割导向的标签,用于解决视觉定位中分割类型的输出。

Global Target Recognition:增强全局感知
为了提升候选框选择的准确性,VGent 引入了Global Target Recognition模块。
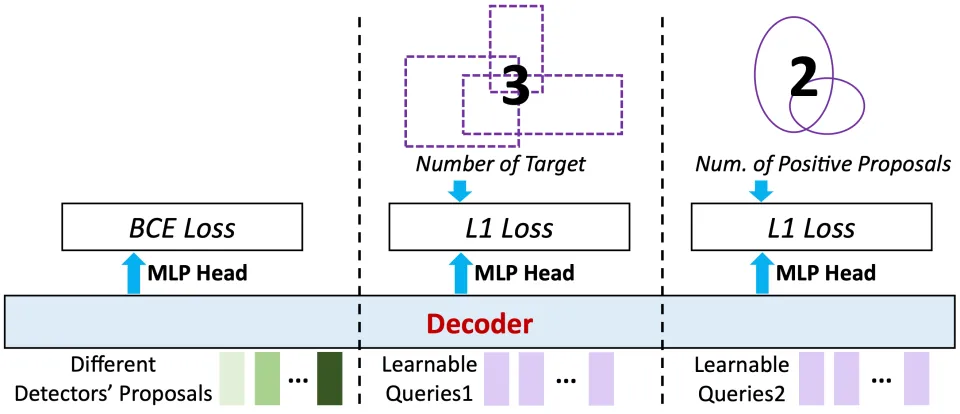
图五:Global Target Recognition示意图。利用Learnable Queries注入全局目标数量信息,并聚合多个detector的结果以提升召回率。
为了提高召回率,研究人员聚合了来自多个detector的proposal形成一个统一的query set,之后引入了额外的 learnable queries与这些proposal queries拼接作为decoder的输入。
这组query被专门训练用于预测目标的总数以及正样本proposal的数量。通过decoder层内的self-attention机制,这些包含全局统计信息的learnable query能够与proposal query进行交互,将「全局线索」传播给每一个候选框,从而增强其对目标群体的整体理解,实现更精准的选择。

实验结果
研究人员在最新的多目标视觉定位基准 ORES (MaskGroups-HQ) 以及传统的单目标数据集上进行了广泛评估。
多目标视觉定位(Multi-target Visual Grounding)
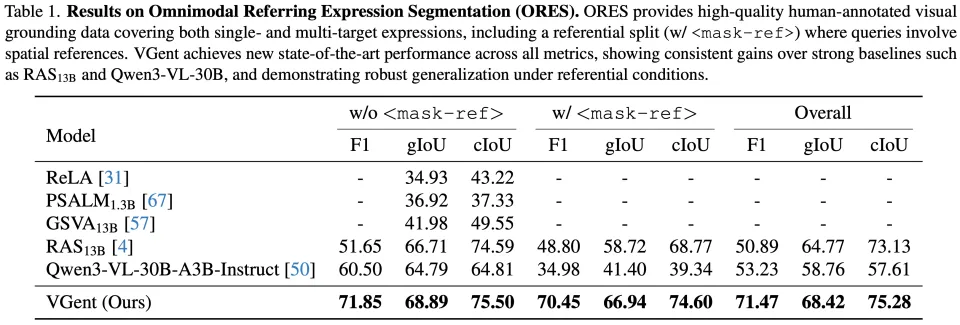
图六:在 Omnimodal Referring Expression Segmentation (ORES) 上的性能对比。ORES是多目标以及存在视觉参照(w/ < mask-ref >)的视觉定位基准。
如图六所示,在极具挑战的ORES基准上,VGent 取得了全新的SOTA成绩。相比之前的最佳方法RAS13B,VGent在F1分数上实现了+20.58%的巨大提升。VGent在gIoU和cIoU上都带来了明显的提升。
值得注意的是,即使对比参数量更大的Qwen3-VL-30B,VGent 依然保持显著优势。同时,得益于模块化设计,VGent 在目标数量增加时保持恒定且快速的推理速度,避免了自回归模型随目标增加而线性增长的推理延迟(如图一所示)。
单目标视觉定位(Single-target Visual Grounding)
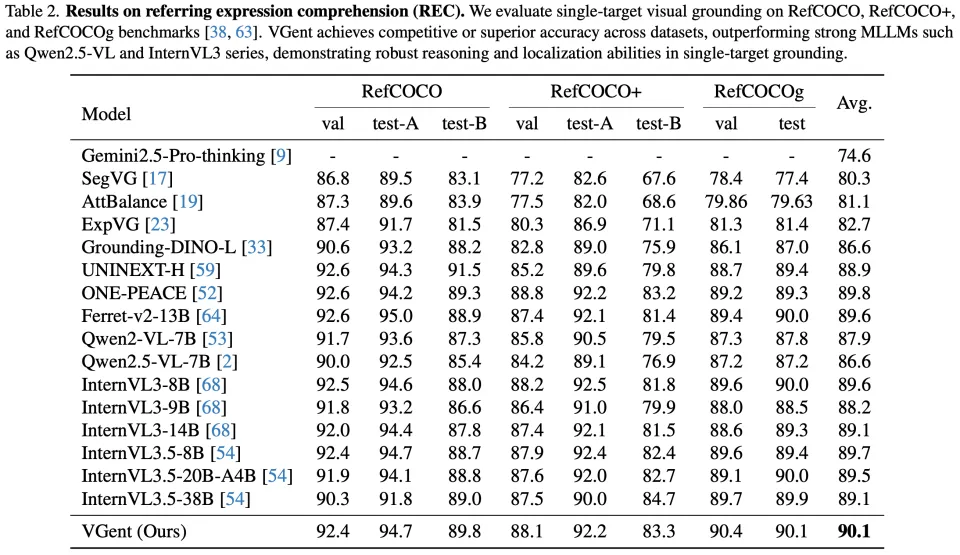
图七:在referring expression comprehension (REC) 上的性能对比。
VGent在传统单目标基准(RefCOCO, RefCOCO+, RefCOCOg)上也表现卓越。
VGent实现了90.1%的平均准确率,超越了InternVL3.5-20B和38B等更大规模的模型 。相比其backbone (Qwen2.5-VL-7B),VGent带来了+3.5%的平均性能提升。

可视化

图八:VGent在不同挑战下的预测结果可视化。
VGent在复杂场景中展现了极强的鲁棒性。
如图八(上)所示,VGent精准定位所有方形钟表,即使存在大量相似的钟表作为干扰项,展现了VGent在密集多目标场景下的优越表现。
图八(下)中,VGent 成功定位了视觉参照(蓝色 mask),并继续推断出左侧穿裙子的女士,排除了右侧的干扰项。
参考资料:
https://arxiv.org/abs/2512.11099