华为开源了个 “图片处理小能手”!OCR时延 160ms,落地场景超实用!
作为一个常年折腾 AI 工具的 “踩坑专业户”,过去半年我在多模态模型上栽的跟头能绕工位两圈:
要么是参数几十 B 的大模型,端侧跑起来像老牛拉车,推理半分钟还出不来结果;
要么是轻量化模型,OCR 识别个复杂表格就错漏百出,视觉定位更是 “指东打西”。
直到刷到华为昇腾社区团队(ascend-tribe)开源的 openPangu-VL-7B,才算在 “性能够用” 和 “部署够轻” 之间找到平衡
它是个十分优秀的端侧部署的图像识别模型,速度和准确率均优于同量级部分开源模型!

它最擅长的两件事:“找东西” 和 “读文字”
这个模型的核心本事,总结起来就是两大块:精准定位图片里的物体,以及把图片里的文字 “抠” 出来用(也就是常说的 OCR)。
举两个实实在在的例子,你就懂了:
要是给它一张装满樱桃番茄的沙拉图,它不光能数出 “一共 12 颗”,还能在图上精准标出每颗番茄的位置 —— 比咱们自己盯着数还准,还不用费眼睛;
要是拿一张公司年报的截图给它,它能直接把里面的表格、文字转换成 Markdown 格式(就是那种能直接复制到文档里编辑的格式),省去了咱们 “看一行敲一行” 的麻烦,省不少时间。
技术细节:7B 参数 + 昇腾原生优化
很多人看到 “7B 模型” 会疑惑:小参数能否搞定视觉 + 文本的多模态任务?openPangu-VL-7B 的核心优势在于 “昇腾原生适配”
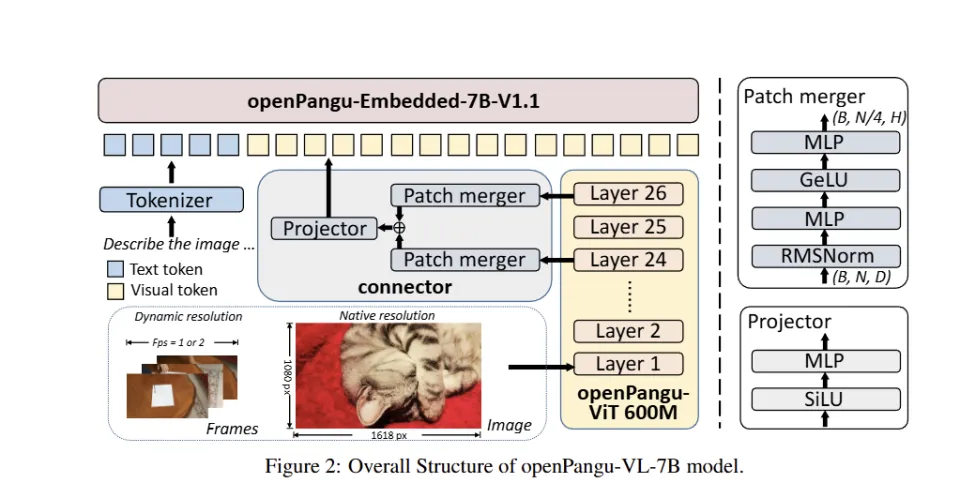
上图为架构图
从架构设计阶段就针对昇腾硬件优化,在轻量化参数下实现了较好的落地性能,以下数据均来自模型官方开源仓库及昇腾社区实测报告:
很多人觉得 “AI 模型越厉害,跑得越慢”,但这个模型偏不。它是华为专门为自家昇腾硬件(比如昇腾 Atlas 800T A2 卡)设计的,相当于 “量身定制的搭档”,跑起来又快又省资源:
处理一张 720P 的图片(差不多是咱们手机拍的普通照片分辨率),160 毫秒就能出结果—— 眨一次眼大概 0.2 秒,它比你眨眼还快一点;
每秒能处理 5 张图,不管是实时拍实时分析,还是批量处理图片,都不会 “卡壳”;
而且它 “学东西” 特别扎实:训练的时候读了足足 3T + 的 “数据书”(相当于海量图片和文字资料),还做到了 “无中断训练”,不会像有些模型那样学着学着就 “掉链子”,所以处理任务时准确率也比同量级的模型高不少。
怎么用?适配范围与上手指南
适配环境(据官方仓库整理,避免跨硬件误解)
支持硬件:昇腾 Atlas 800T A2、Atlas 300I Pro 等昇腾系列硬件(暂不支持 GPU/CPU 部署);
支持操作系统:openEuler 22.03 LTS、Ubuntu 20.04、CentOS 7.6 等(并非仅支持 openEuler 24.03 以上);
依赖工具:华为昇腾 CANN 软件栈(推荐版本 6.0.RC1 及以上)。
上手路径(分场景适配,降低预期落差)
快速试用:无需搭环境,直接访问昇腾社区 Demo 平台,上传图片即可测试视觉问答、基础 OCR 等功能;
本地部署:推荐具备 Python 开发基础、了解深度学习环境配置的用户尝试。
参考官方部署文档,从下载预训练模型、安装依赖到调用 API,步骤清晰,具备基础开发经验的用户通常 1-2 个工作日可完成部署;
https://ai.gitcode.com/ascend-tribe/openPangu-VL-7B/blob/main/docs/deployment.md
必须说明的局限性:理性看待模型能力边界
openPangu-VL-7B 虽表现亮眼,但并非 “全能模型”,存在明确局限性:
在超复杂图像(如低分辨率、多遮挡场景)、小语种文本处理、极端罕见领域(如专业冷门技术文档)中,准确率可能下滑;
财务数据处理、工业质检、教育批改等高精度场景,无法完全替代人工,必须结合人工核验;
开源地址:
https://ai.gitcode.com/ascend-tribe/openPangu-VL-7B/tree/main