深度解析世界模型:新范式的路线之争,实时交互与物理仿真
作者:Cage、Haozhen
我们相信 26 年会是多模态技术的大年,其中视频生成会快速进步让应用大规模落地,而世界模型则会有研究上的科学突破,甚至开始从 research 走向 production。
在相当长的一段时间内, World Model 这一概念始终处于较为混沌的状态;直到近半年,随着技术路径逐渐收敛,尤其是在具身智能与真实交互场景中出现了初步落地的案例,世界模型的轮廓开始变得清晰。
如果和语言模型对比:语言模型解决的是语义层面的压缩和推理,预测下一个 token;世界模型是在解决下一步更根本的问题,AI agent 是否能真正理解时间与空间,并进行预测下一帧、下一个行动。如果和视频生成模型对比:世界模型在交互性、实时性、长时记忆和物理合理性这四点上都需要更进一步。
于是行业中的玩家开始在这些提升方向有了各自的 bet, World Model 领域逐步分化出两条路线:一条以实时视频生成为核心,服务文娱、游戏等 for human 的消费者场景;另一条以显式 3D 结构为中心,服务机器人、自动驾驶等 for AI 的领域。
本文沿着这个路线分化展开,拆解两条路线的技术趋势和落地场景,并通过四象限框架梳理当前主要大公司和创业公司玩家的真实定位,来讨论世界模型会以怎样的产品形态进入市场。
01.
世界模型是什么?
目前市场上对世界模型的定义有很多:
• 前 Meta AI 科学家 Yann LeCun 将世界模型类比为人脑中的分区和内部 representation,能够模拟未来一系列行动,并预测行动对世界的改变;
• Nvidia 对世界模型的定义是理解现实世界中物理规则和空间特性的神经网络。

我们深入研究后对世界模型给出这样的定义:能理解时间和空间规律,且能够根据当前环境和动作,模拟未来世界演化的模型。
为什么世界模型在变得越来越重要?背后至少有三个明显的趋势:
1. 语言毕竟只是有损压缩,语言 base 的智能进步开始遇到局限,空间可能是下一个重要的智能来源。
2. 架构融合与算法进步:Autoregressive Transformer 与 Diffusion 模型的算法优化进步很快,这两者的融合效果更好了,使得生成模型具备了智能层面的 scaling law。
3. 具身智能的需求倒逼: 机器人行业依靠现实世界的数据采集难以满足指数级的 Scaling Law 的需求,需要一个高保真的虚拟世界。
02.
世界模型 vs 视频生成,在哪里更进一步?
世界模型和视频生成模型的进步息息相关,同时两者之间的边界还不够清晰。我们梳理下来以下几点是世界模型范式下最需要提高的:
1. 长时记忆:能否生成持续、连贯的长时间记忆
当前视频生成模型通常只能生成十秒级的视频片段,理想的 world model 应该具备无固定时长限制的持续生成能力,并在长时间跨度内保持全局一致性。几十秒前生成的场景布局和物体状态,在后续生成中仍应被稳定保留,而不会出现物体凭空消失或位置突变的现象。
但目前 Transformer 受限于有限的序列长度,简单的拉长上下文不仅会让内存爆炸,还会导致推理逐渐变慢、交互延迟增加。
因此业界开始探索其他方式,目前一种常见的方式是引入显式的3D 结构表征,将环境以 NeRF 或 Gaussian Splatting 等形式存储为“外部记忆库”,比如每隔一定帧生成环境的 3D 要素并存储,以供后续参考,类似“生成-重建-再生成”的循环。
长时记忆仍然是 world model 和 LLM 业界公认的核心难题:隐式记忆机制不可避免地存在信息遗失,而显式记忆在面对动态 4D 场景时又会遭遇表示和维护成本过高的问题。这一领域的技术突破,将决定世界模型能否迈向“开放世界级别的持续模拟”。
2. 交互性:能否随时接受外部动作指令
World model 不仅要生成世界,还需要用户可以指导世界的生成,模型必须支持在任意帧动态注入动作信号(例如玩家按键、机器人关节指令等),并据此影响后续画面。
这个挑战在于训练数据需要同时包含视频帧序列和对应的动作。针对互联网无标签视频,DeepMind 的 Genie 系列创新性地提出潜在动作空间(Latent Action)概念,模型可以从纯视频中无监督学出隐含的“动作因子”,让大型无标签视频也开始参与用于交互模型训练。

另外还有一些工作使用的是游戏引擎数据,这类数据有明确的动作标签,可以用于训练条件化的视频生成模型。但无论哪种方法,在这一路线下,支持动作条件控制的视频生成能力都是构建可玩的世界模型的必要条件。
3. 实时性
对于交互式应用来说,需要保证用户每次操作后的反馈延迟够低。一般来说,直播场景通常可容忍约 1 秒延迟,而游戏对交互延迟的要求一般需低于 0.1 秒,VR 等沉浸式应用在理想情况下应控制在 0.01 秒以内。而只要用到扩散模型就需要每帧数十步去噪,优化推理比较难达到 30FPS 以上,更不用说将延迟控制在 0.1 秒以内了。
从落地角度来看,实时性往往决定了此类产品能否应用于游戏、VR 等场景,因此目前业界正在尝试通过蒸馏和架构改进来解决这个问题:DMD (Distribution Matching Distillation) 将 50 步扩散压缩为 4 步,大幅提升帧率;Self-Forcing、APT2 等训练策略让模型在训练时就模拟自身推理过程,从而直接优化延迟与鲁棒性,在单卡上实现了 17FPS、亚秒级延迟且保持高画质。
Self Forcing 是一种自回归视频扩散模型的训练范式,它在训练阶段让模型像推理时那样基于自己生成的输出(而不是真实帧)进行下一步预测,从而消除训练与测试(推理)之间的分布不匹配问题,从而提升长序列生成质量、稳定性和实时性。

4. 物理合理性
对娱乐应用而言,只要“视觉上过得去”就可以了;但对自动驾驶、机器人等高风险领域,模拟结果必须符合真实物理规律,否则可能误导下游 AI 决策。
虽然当前的视频模型在常规物理现象上已有一定“隐式理解”,例如 Veo3 在视频中展现了相当合理的动力学效果。然而,在训练数据罕见的极端物理条件下(如超高速碰撞、复杂关节力学),生成模型还是容易出现物理幻觉。
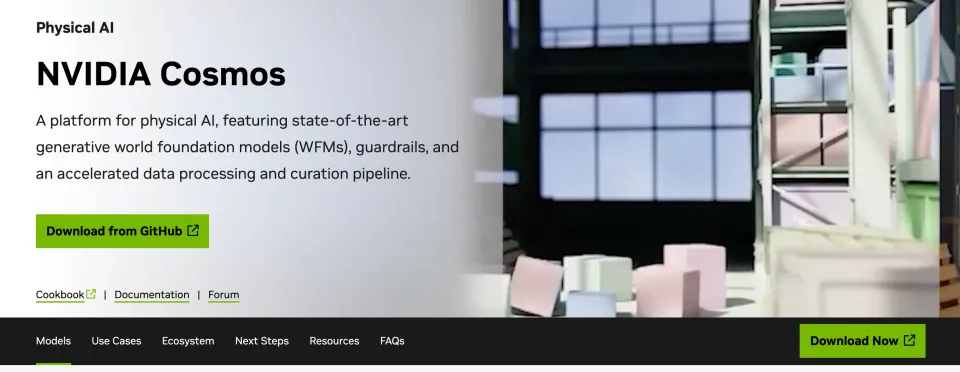
为提升生成结果的物理一致性,目前研究者们已从多个方向展开探索:最常见的是在生成阶段之后引入物理约束的后处理机制,或直接结合可微物理引擎对结果进行校正。例如 NVIDIA 的 Cosmos 在扩散模型生成视频后,利用内置的 PhysX 引擎对帧间运动进行修正,使物体运动符合基本的碰撞与重力规律。
03.
两种路线:空间 vs 时间
在世界模型还没有成功 scale up 的情况下,学界和业界都有了很多重要的早期探索。探索很难面面俱到,不同团队和科学家会有自己最希望 bet 和优化的目标,比如前面说的实时性和物理准确性很难在当下同时实现。
因此我们观察到出现了两种路线的世界模型:
• 更在乎实时性的视频世界模型,主要适用于文娱、游戏等 to C 的场景;
• 更注重物理准确性的 3D 世界模型,更多用在机器人、自动驾驶等 for agent 的领域。
路线一:实时视频世界模型
这一路线下实时性是最核心的优化目标,同时还需要保证模型的可交互性和一定的长时记忆,物理合理性相对是排在最后的。因此这类模型的训练数据也会以带有交互行为的视频数据流为主,很多团队从 Minecraft 这样的第一视角游戏数据出发。
于是在这一路线下的应用场景会偏向于文娱、游戏这样的 to C 场景,具体来说可以分成三类:
1)互动内容创作和新型“引擎”
这个形态未来可以演进为一种视频版的 Unity / Unreal:
• 简单的关卡设计可能会减少复杂的 3D 建模流程,而是转变为“画出场景并走两圈采集数据”;
• 引擎的核心也将从传统的 3D 实时渲染,转向由视频世界模型(video world model)驱动的生成式推理,以视频原生的方式完成世界模拟与内容生成。
2)直播和虚拟形象
在这个场景中,主播只需上传人脸或角色素材,世界模型即可在运行时实时驱动虚拟形象,虚拟形象的动作与表情由摄像头或动作捕捉设备直接输入。
3) AR/VR
在这个场景中,世界模型更接近于一种“动态背景生成器”的角色:它可以替代部分传统的环境建模工作,负责生成和更新用户所处的虚拟环境,而用户的视角变化与交互动作则由头显和控制器等硬件实时提供。
从商业化节奏来看,我们认为世界模型在未来 1–3 年内更可能以 SDK 或 API 形态给 MCN、游戏工作室和独立开发者做插件,有机会演进为“新型引擎 + 工程服务”的组合方案,与 Unity / Unreal 等传统引擎形成互补甚至并行关系。进一步放眼 3–5 年周期,可能会出现 video-native engine 平台公司,也有可能以爆款新形态内容的形式走向用户。
路线二:3D/4D 结构化
这条路线对前文所说的交互性、持久性、实时性这三个特点也都比较关注,但最在意的还是物理世界的准确性。
这一类方法通常先采用 NeRF、3D 高斯散点(3D Gaussian Splatting)等显式 3D 表示对场景进行建模,再训练生成模型直接输出这些 3D 表示,最后通过渲染得到不同视角下的图像。斯坦福李飞飞团队的 World Labs 就是典型代表:模型生成的并非视频帧序列,而是可供转动视角的 3D 场景表示。
这条路径的优势在于 3D 一致性强:在多视角条件下,物体的形状与空间位置能够保持稳定,整体几何拓扑关系清晰可辨。这一特性对机器人导航、AR 数字孪生等应用尤为关键,使 agent 能够在生成环境中可靠地完成定位、路径规划与避障等任务。同时,显式 3D 表示与物理引擎结合,可以在几何结构之上叠加质量、碰撞等物理属性,从而进一步提升环境的真实性与可交互性。
但劣势在于数据获取和计算成本高。一方面,大规模且标注完善的 3D 场景数据远少于 2D 视频,数据获取成本高;另一方面,这些模型通常参数巨大且推理复杂,需要专用硬件支持。这一路径的适用场景往往是带有强几何约束的仿真。对于这些场景,视觉逼真度可以适当牺牲,但空间定位和测量必须可靠。比如机器人室内导航,需要生成一个房间或建筑物的 3D 模型供机器人探索,要求门窗、墙体位置精确。
如果要降低这种端到端获取数据的成本,可以考虑和现有的经典物理模拟方法结合。NVIDIA 的 Cosmos 就是在生成模型中融合经典物理模拟的典范。
Cosmos 能根据文本、图像等输入生成物理一致的视频或状态序列,特色在于内置物理守护(guardrails)机制,比如利用 PhysX 引擎对生成结果进行约束过滤,以剔除穿模、违背能量守恒等不合理现象。NVidia 一如既往地把自己的产品定位为开放平台,允许开发者微调模型来适配自己特定的机器人或仿真需求。
04.
市场玩家的四象限格局
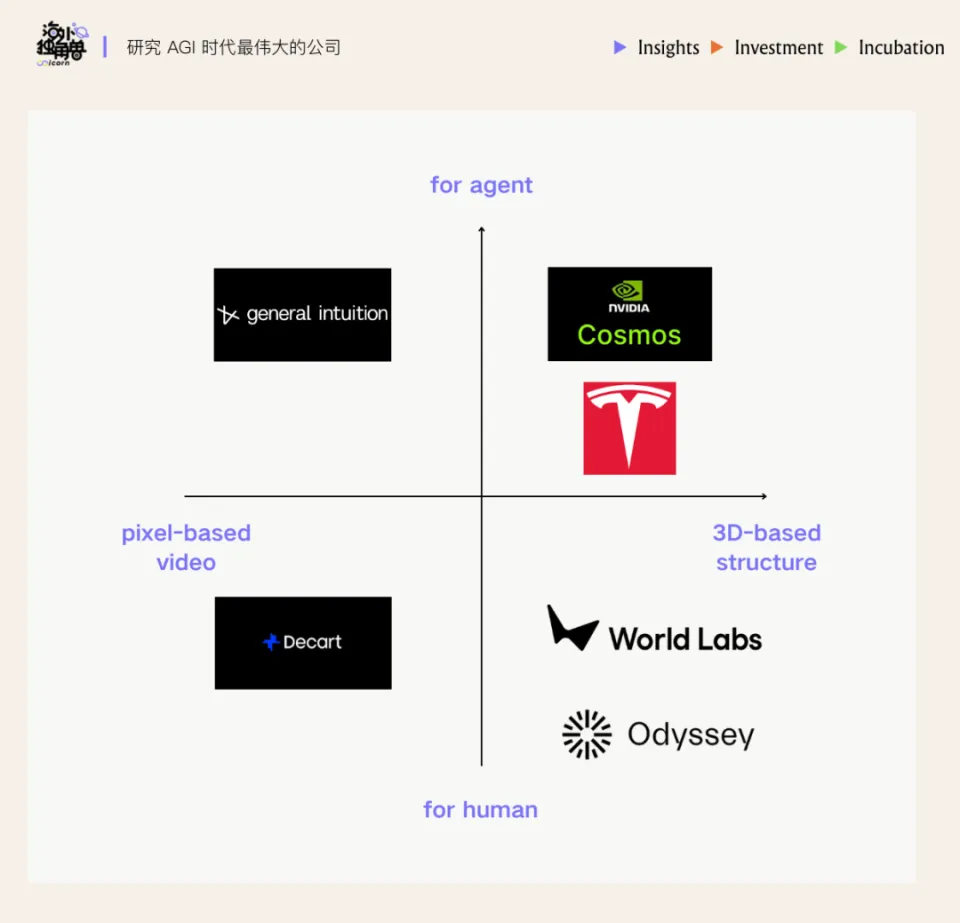
基于上述两条发展路径,我们进一步将市面上的玩家以四象限框架分类。
• 横轴表示世界模型的表示形式:左侧以直接生成视频像素为主(Video-based),右侧则采用显式的 3D 或物理结构表示,例如 3D Gaussian Splatting;
• 纵轴表示模型的主要服务对象:上半部分面向人类用户,侧重文娱、游戏、XR 与内容创作等体验型应用,下半部分则主要服务于 AI 与机器人,用于仿真、训练与评估等智能体相关任务。
在这个四象限下:
• Decart、Odyssey 等偏娱乐与游戏的视频生成模型主要分布在左下象限;
• World Labs 等强调可漫游空间体验与 3D 内容生成的公司位于右下象限;
• General Intuition 和其他视频导航类世界模型会落在左上象限;
• Cosmos、Tesla 世界模型等机器人世界模型,集中在右上象限。
1. World Labs
World Labs 可以说是当前硅谷世界模型领域估值最高的初创公司之一,公司核心愿景建立在李飞飞提出的 Spatial Intelligence 理论之上。她认为仅掌握语言逻辑的 AI 是不完整的,真正的智能必须具备在三维空间中感知、推理、行动并构建世界模型的能力。
World Labs 强调 3D 一致性(3D Consistency)与持久性(Persistence)。在 Sora 这样模型生成的视频中,如果摄像机旋转 180 度再转回来,原本在那里的物体可能会消失或变形(物理幻觉)。而 World Labs 致力于构建的模型,生成的不是一系列像素的堆叠,而是一个具有内部几何结构和物体恒常性的“世界”。

• 技术架构:LWM 与 RTFM
World Labs 的技术护城河在于独创的大世界模型(Large World Models,LWMs),特别是核心推理引擎,即实时帧模型(Real-Time Frame Model,RTFM)。
RTFM 不是简单地预测下一帧像素,而是要学习成为一个神经渲染器 Neural Renderer。这个技术的特点在于:
1. 端到端学习物理规律:RTFM 是一个自回归的 Diffusion Transformer,在海量视频数据上进行端到端训练。它不需要人工编写的光线追踪代码或物理引擎,而是通过观察数据,自动学习了光照反射、阴影投射、透视变换等复杂的物理现象;
2. 隐式 3D 表征:与传统的 NeRF(神经辐射场)或 3D Mesh 不同,RTFM 不一定在显存中构建一个显式的 3D 模型,相反,它将输入的 2D 图像转化为高维的神经激活状态(KV Cache),这种状态隐式地包含了场景的 3D 结构;
3. 空间记忆:为了解决长时记忆和场景一致性问题,RTFM 引入了“姿态帧”(Posed Frames)的概念,也就是模型生成的每一帧都带有空间坐标信息,当用户在虚拟世界中漫游时,模型会根据当前的视角位置,从记忆库中检索空间上邻近的帧作为上下文。
RTFM 的思路其实是模糊了计算机视觉中长期存在的两个独立领域:三维重建(Reconstruction)与生成(Generation)。
1. 当输入视点密集时,模型表现为高质量的重建算法(类似 NeRF),精确还原真实场景。
2. 当输入视点稀疏时,模型则平滑过渡到生成模式,利用学习到的先验知识“脑补”出未见区域的合理几何结构。
• 产品:Marble
World Labs 的首个对外披露产品名为 Marble。这是一个基于浏览器的交互式 3D 世界生成平台,用户只需上传一张图片或输入一段文字,Marble 就能生成一个可交互、可漫游的三维场景。
与其他仅提供在线视频流的模型不同,Marble 生成的是可下载的完整 3D 环境,支持导出为高斯点云、网格模型或视频等格式。这种方式减少了场景“morphing”漂移不一致的问题,用户还可以对生成世界进行 AI 原生编辑:例如利用 Chisel 工具先搭好空间结构,再由 AI 填充视觉细节,实现对生成内容更精细的控制。Marble 支持多模态输入(文本、图像、视频或 360°全景),也可通过导入 3D 草图精确控制布局,随后持续生成任意长度的世界。
此外,与传统的全景图不同,Marble 生成的世界允许用户自由移动视角,且场景中的光影、反射会随着视角的改变而实时渲染,呈现出极高的物理真实感。
目前 Marble 已开放免费和订阅模式,定价层级根据每月生成次数和功能权限划分,为游戏开发者、影视内容创作、VR 场景搭建等提供工具支持。
目前 World Labs 融资总额约为 2.3 亿美元,估值超过 10 亿美元。主要投资方包括领投的 a16z、NEA 和 Radical Ventures,以及战略投资方 NVIDIA(NVentures)、AMD Ventures 和 Adobe Ventures,其中 NVIDIA 和 AMD 的加入表明 World Labs 模型对算力基础设施有深度依赖并具备潜在的硬件优化合作可能,Adobe 的投资则暗示 World Labs 在创意工具领域的落地前景。此外,投资方还有 Geoffrey Hinton、Jeff Dean 和 Eric Schmidt 等个人投资者。
2. General Intuition
General Intuition 是一个公益性公司(Public Benefit Corporation),作为游戏短视频平台 Medal 的衍生公司,与其它公司直接销售世界模型不同,General Intuition 并没有试图去生成“给人看”的视频,而是专注于利用海量的游戏数据,训练能够进行时空推理(Spatial-Temporal Reasoning)的 agent,用于游戏 NPC 和机器人等领域。

General Intuition 最大的优势就在于 Medal 独特的数据源:每年可获得约 20 亿个游戏视频片段,主产品拥有 1000 万 MAU,覆盖了数万种不同的游戏环境,从写实风格的射击游戏到抽象风格的独立游戏。据报道,OpenAI 曾出价 5 亿美元试图收购 Medal,目的就是为了获取这一庞大的游戏数据集。
公司的核心理念在于:视频游戏是训练 AGI 的最佳合成数据源。因为传统的视频数据(如 YouTube)是被动的,缺乏动作标签。而游戏数据天然包含了“状态-动作-奖励”的闭环。玩家的每一次按键(Action)导致屏幕画面的变化(State Change),这种因果关系是训练 agent 的核心。
而且 Medal 平台上每天上传的数百万游戏片段中,不仅有高光时刻,还有大量的失败、Bug、物理碰撞测试等“边缘情况”。这些数据对于训练 AI 理解物理边界和鲁棒性至关重要。
• 技术架构:从像素到行动的端到端学习
General Intuition 的模型训练专注于视觉输入(Visual Input)到动作输出(Action Output)的映射。也就是说,agent 不会访问游戏的底层代码或 API,而是像人类一样只“看”屏幕像素来做出决策。这种“像素级”的训练方式理论上有更强的迁移能力。因为现实世界中的机器人同样没有“上帝视角”或底层 API,它们也只能通过摄像头(视觉传感器)来感知环境,因此在《使命召唤》中训练出的导航与避障策略,理论上可以迁移到现实世界的无人机或机器狗身上。
目前公司正在构建的基础模型就是为了赋予 Agent“通用直觉”(General Intuition)。这种直觉不仅仅是识别物体,更是理解物体在时间和空间中的运动规律,比如理解当前动作会导致何种物理后果;在未见过的复杂环境中进行路径规划,而无需预先构建高精地图。
• 团队与融资
General Intuition 在今年 10 月完成了 1.34 亿美元的种子轮融资,这一金额远超常规种子轮规模,显示了资本对公司数据价值和技术路线的高度认可。此次融资由 Khosla Ventures 和 General Catalyst 领投,其中 Vinod Khosla(Khosla Ventures 创始人)作为 OpenAI 的早期投资人,再次下注 General Intuition ,也表明了他将“基于游戏数据的 Agent 训练”视为继 LLM 之后的重要机会。
公司创始人兼 CEO Pim de Witte 同时也是 Medal 的创始人,这种创始人延续性确保了 General Intuition 能够无缝接入 Medal 的数据生态。此外,团队还汇聚了来自 DeepMind、Epic Games 以及发表过 DIAMOND、IRIS 等世界模型相关论文的顶尖研究员,为公司的技术研发提供了强有力的支持。
3. Decart
Decart 是一家由以色列技术团队创建的 AI 初创公司,2024 年 10 月首次公开亮相并宣布获得 2100 万美元种子轮融资(红杉资本领投,Zeev Ventures 参与)。公司总部在旧金山,在以色列设有研发运营。2024 年 12 月,Decart 又快速完成 3200 万美元的 A 轮融资(Benchmark 领投,红杉和 Zeev 跟投),投后估值提高到 5 亿美金以上。
公司创始人兼 CEO Dean Leitersdorf 年仅 26 岁,拥有以色列理工学院快速完成本硕博学位的背景;联合创始人 Moshe Shalev 曾在以色列国防军 8200 部队构建 AI 情报系统,有资深工程经验。

公司在推出核心产品前,就通过一款面向企业端的 GPU 训练推理优化软件实现了数百万美元营收,公司结束 stealth 状态时已经实现盈利。这款软件据称可将模型训练推理成本从每小时 100 美元降至 0.25 美元。凭借基础设施技术带来的现金流,Decart 得以全力研发 AI 生成引擎。
Decart 发布的最引人注目的成果就是首个可交互“开放世界”AI 模型 Oasis。Oasis 可以看作 AI 驱动的沙盒游戏引擎:无需任何传统游戏引擎或预设关卡,完全可以由 AI 根据用户操作即刻“生成”游戏世界。这个模型以大量 Minecraft 游戏视频为训练数据,采用 Transformer 结合扩散模型的架构,自回归地逐帧生成画面。
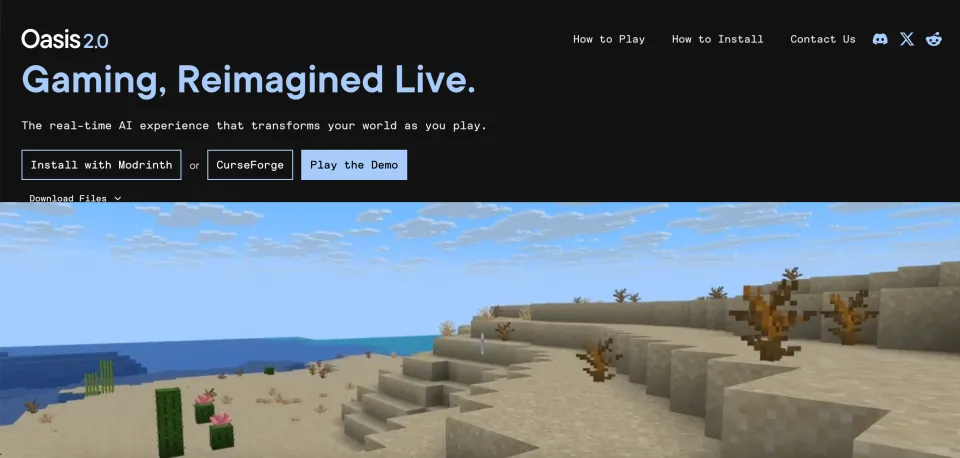
当玩家通过键盘、鼠标发送操作时(如行走、破坏方块),Oasis 会实时输出下一帧的游戏画面,并在这一过程中同时模拟物理和游戏规则,实现基本的物理碰撞和物件交互效果。也就是说,Oasis 在无需任何预编程脚本的情况下,做到了从键盘、鼠标输入到画面输出的端到端实时闭环,每帧生成间隔约 40 毫秒,达到接近 25 帧/秒的速度。
这意味着 Oasis 完全抛弃传统游戏引擎,验证了纯 AI“视频生成引擎”的可行性。用户甚至可以上传一张图像让模型生成对应风格的世界,从而定制自己的关卡。
为了支持如此高强度的实时生成,Decart 对模型架构和推理框架进行了专门优化,并与硬件初创公司 Etched 合作:后者即将推出的 “Sohu” AI 芯片据称可将 Oasis 提升至 4K 分辨率,并可以以当前成本支持 10 倍用户量。
我们认为,作为第一个吃螃蟹的人,Oasis 当前还有明显局限,比如在画面质量上,生成环境较模糊、分辨率低;在持久性上,模型容易“遗忘”先前生成的布局,例如玩家转身再回头看,身后的地形可能已变样。这些问题本质上是长程记忆和全局一致性不足,Decart 团队已在研究通过滑动窗口或显式内存等方案改进模型的时空一致性。
4. Odyssey
如果说 Decart 追求的是速度与效率,那么 Odyssey 追求的则是极致的真实感(Photorealism)与可编辑性(Editability)。他们代表了“高保真重建派”,目标是为电影、3A 游戏和虚拟制片提供工业级的世界模型资产。
Odyssey 推出的 Explorer 模型是一个能够将单一图像转化为高保真 3D 场景的生成模型。但与其他竞品不同,Explorer 生成的结果是可以导出并编辑的 3D 资产,而非一段死视频。
• 高质量数据驱动的 3D 资产
Odyssey 采取了目前业内最“重”的数据采集策略,他们开发了一套重达 25 磅的专业采集背包,集成了 6 个高分辨率摄像头以实现 360 度全景覆盖,并配备 2 个高精度 LiDAR(激光雷达)传感器和 IMU(惯性测量单元)。通过这一硬件系统,Odyssey 能够采集最高达 13.5K 分辨率的视觉数据,并同步获得精确的物理深度信息,从而构建高质量的 Ground Truth 数据集。这种依赖真实世界重装备采集的数据护城河,是任何纯软件公司无法比拟的护城河。

Odyssey 的核心算法采用了 3D 高斯泼溅(3D Gaussian Splatting)技术。与 NeRF 的神经网络隐式表达不同,3DGS 使用数百万个带有颜色、透明度和方向的“椭球体”(高斯球)来表示场景。
一方面,这个技术的优势在于渲染速度快,可以支持实时渲染。另一方面,相比于 Sora 等模型,这个技术让 Odyssey 的可编辑性非常强,因为场景是由离散的高斯球组成的,艺术家可以直接在 Unreal Engine 或 Blender 中对这些球体进行移动、删除或修改。这使得生成的资产可以无缝接入现有的好莱坞 VFX 工作流。
• 团队与融资
公司创始人是 Oliver Cameron (CEO) 和 Jeff Hawke (CTO)。两人均为自动驾驶领域的资深人士(曾任职于 Voyage,Cruise,Wayve)。他们将自动驾驶领域严苛的数据采集方法论带入了创意产业。公司的董事会成员包括 Ed Catmull。作为 Pixar(皮克斯)的联合创始人、图灵奖得主,Ed Catmull 的加入是对 Odyssey 技术路线最强有力的背书。这表明 Odyssey 的目标直指电影工业的变革。
去年 12 月,Odyssey 完成 1800 万美元的 A 轮融资,本轮由 EQT Ventures 领投,GV(Google Ventures)和 Air Street Capital 跟投。
排版:夏悦涵
