阿里发布Qwen3-Coder-Next!不震惊、不颠覆、实打实看看到底如何!
这玩意儿到底是干嘛的?
它的核心定位不是简单地堆参数,而是专攻编程代理。训练时特别强化了可执行任务、环境交互反馈、工具调用、长程推理,以及从执行失败中自我恢复的能力。

简单说,它不是那种只会写Hello World的模型,而是真正能像一个“程序员助手”一样,接手复杂任务、调用工具、甚至在出错后自己调整。
硬实力:参数、配置与核心能力
编程语言支持:官方称覆盖数百种主流和专业语言。
之前很多人担心 80B 跑不动,这次官方数据出来了,门槛比想象中低,但也绝对不低:
显存/内存门槛,4-bit 量化(GGUF/GPTQ),需要约 46GB 的显存或统一内存。FP8 高精度:需要约 96GB。
推荐配置:土豪方案:双卡 RTX 3090 / 4090(24G x 2 = 48G),刚好能跑 4-bit 版本,速度飞快。
Mac党方案:Mac Studio / MacBook Pro (M3/M4 Max),内存选 64GB 或更高,这是最优雅的本地方案。
因为激活参数只有 3B,只要你显存塞得下,它的 Token 生成速度会让你怀疑人生——极快。它解决了大模型 “跑得慢” 的千古难题。
性能到底怎么样?看数据说话
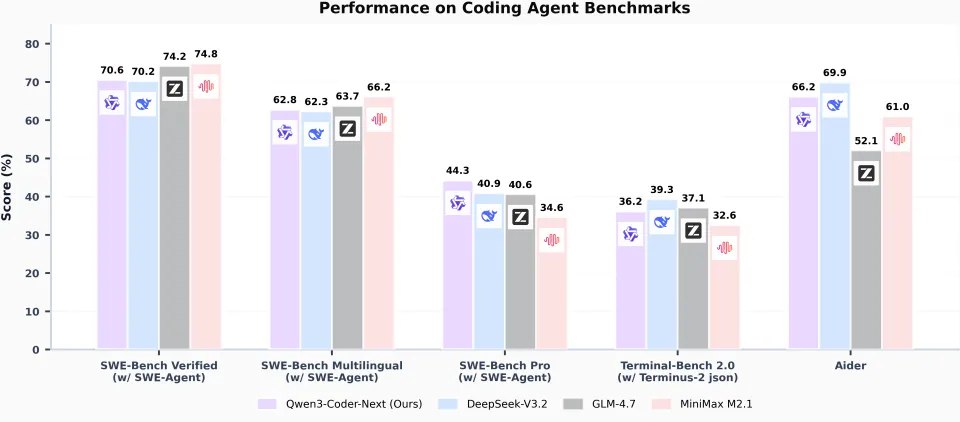
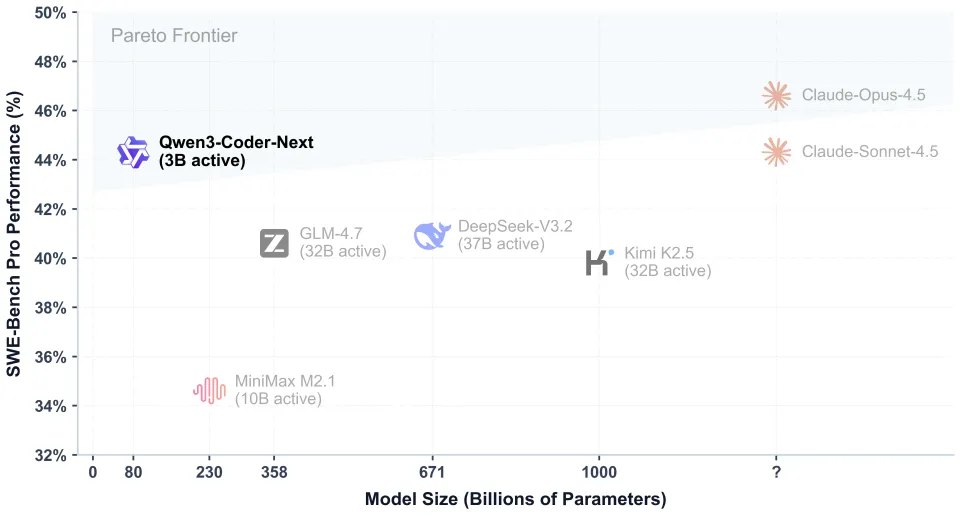
上面图张图是 Qwen3-Coder-Next(图中紫柱)在各大主流 Coding Agent(编程智能体) 评测集上的表现。
对手也都是狠角色:DeepSeek-V3.2、GLM-4.7 和 MiniMax M2.1。我仔细盘了一下这张图,咱们不吹不黑,客观地拆解一下它的真实水平。
真正的亮点:啃“硬骨头”的能力
大家把目光聚焦到图中间那个 SWE-Bench Pro (w/ SWE-Agent)。
数据表现:Qwen3-Coder-Next 拿到了 44.3% 的高分。
DeepSeek-V3.2:40.9%
GLM-4.7:40.6%
MiniMax M2.1:34.6%
解读:这是这张图里含金量最高的一个数据。SWE-Bench Pro 通常比 Verified 版本更难,涉及更复杂的工程逻辑和长链路任务。
Qwen3 在这里大幅领先(领先第二名近 4 个百分点),说明了一个核心事实:在处理复杂、高难度的实际工程问题时,它的逻辑链条是最稳的。 它是真的能干“重活”。
稍显弱势:标准任务与辅助工具
再看两边的 SWE-Bench Verified 和 Aider,这里的情况就很有意思了。
SWE-Bench Verified测评分数,Qwen3 (70.6%) 居然排在末尾,虽然和 DeepSeek (70.2%) 半斤八, 但输给了 GLM-4.7 (74.2%) 和 MiniMax (74.8%)。
解读:在经过人工验证的、相对标准的 Issue 修复任务上,Qwen3 并没有展现出统治力,反而是 MiniMax 这种黑马表现抢眼。这说明在“标准题”上,各家模型差异不大,甚至 Qwen3 还有点“偏科”。
Aider 评测上,Qwen3 (66.2%) 输给了 DeepSeek-V3.2 (69.9%)。
解读:Aider 是非常流行的命令行编程工具。这个分数低一点,可能意味着在代码编辑的指令跟随或者diff 生成的格式准确性上,DeepSeek 目前的手感还是要更顺滑一些。
总体评价:强,但不是最强
Qwen3-Coder-Next在当前开源Coding Agent模型中,属于稳扎稳打的第一梯队偏上位置。
它不是“全面最强”,但凭借MoE的高效设计,在资源消耗远低于对手的情况下,拿到了极具竞争力的分数——尤其在难度最高的Pro基准上领先,证明了“小激活参数也能打硬仗”的潜力。
如果你追求绝对峰值性能和最均衡表现,DeepSeek-V3.2或GLM-4.7可能更稳;
但如果你更看重本地部署效率 + 复杂任务实战能力,Qwen3-Coder-Next目前是性价比最高的选择之一。
它的定位很清晰:不是堆参数争榜首,而是用最低成本接近顶级Agent效果,这点做得相当成功。
兄弟们,这才是基于最新官方数据的理性判断。有不同测试体验的欢迎留言,咱们一起讨论。继续关注后续更新,看它能不能在弱项上再优化一波。