可灵AI发布3.0系列模型:可连续生成15s视频,实现生产流程All-in-One
 图:可灵视频3.0 智能分镜
图:可灵视频3.0 智能分镜
文|晓静
编辑|徐青阳
2月5日,快手旗下的可灵AI正式上线3.0系列模型。本次发布涵盖了可灵视频3.0、可灵视频3.0 Omni、可灵图片3.0以及可灵图片3.0 Omni四大核心模型。目前,该系列已率先面向黑金会员开放,并预计在近期完成全量用户的覆盖上线。
01 “All-in-One”架构下的全流程整合
不同于传统AI视频工具将功能拆分为独立模块(如先生成图片、再转视频、后进行剪辑)的模式,可灵3.0采用了“All-in-One”集成架构。该架构将语义理解、内容生成与后期编辑功能整合在同一个底层模型体系内。
在实际应用层面,这意味着创作者可以在同一个操作窗口内,同时输入文字描述、参考图片、音频素材以及视频片段。模型能够直接识别并处理这些多模态信息,输出成品级的影像结果,减少了跨工具操作带来的信息损失和流程断裂。
02 提升主体“一致性”能力
针对行业性“一致性”问题的技术方案 在长视频创作中,如何保持同一主体在不同镜头间的稳定性一直是行业难题。
可灵3.0通过三项关键技术提供了解决方案:
1. 主体参考与上传: 允许用户直接上传特定的人物或物体素材作为模型生成的“基准”,确保生成内容在不同角度、光影下的高度一致。
2. 音色绑定: 实现了音频与视频人物的高度协同,确保生成的配音与人物特征、口型保持同步。
3. “图生视频+主体参考”技术: 这一行业首创功能使得模型在处理复杂镜头切换(如远景转特写)时,能够精准锚定角色特征。此外,该版本显著优化了画面中文字、品牌标识(Logo)的清晰度,并支持在多语言环境下维持角色风格的统一。
03 15秒连续视频生成
在具体的生成参数上,可灵3.0支持最长达15秒的连续视频生成,这相较于早期的短片段生成,大幅提升了叙事连贯性。 为了增强创作者对镜头的控制权,新系统引入了“智能分镜”与“自定义镜头控制”功能。
用户可以通过预设指令对镜头的移动(如推拉摇移)、景别切换和叙事节奏进行调节。这种“镜头语言”的自动化生成,使得创作者不再完全依赖于对碎片化视频的后期拼接,而是能够在生成阶段就构建出具备情绪递进和画面张力的连续镜头组。
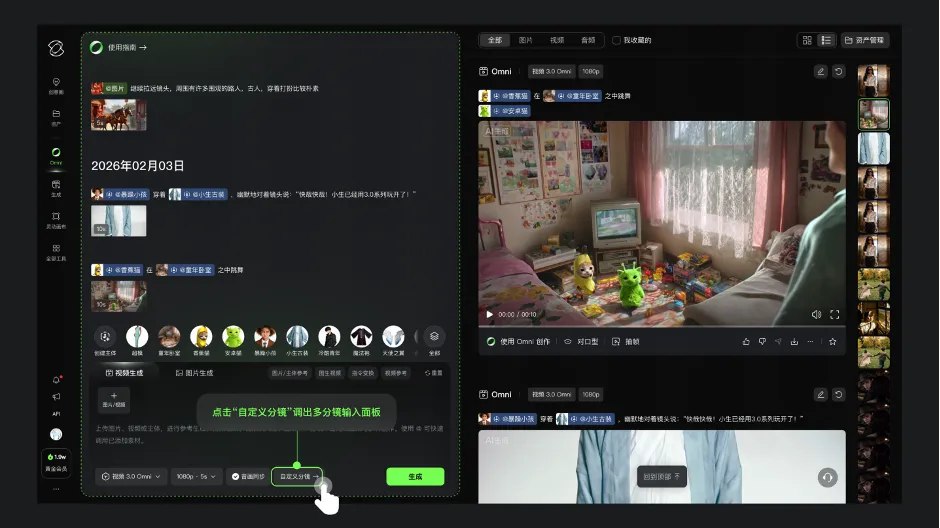 图:可灵视频3.0 Omni自定义分镜
图:可灵视频3.0 Omni自定义分镜
从目前披露的产品界面看,可灵3.0集成了完善的资产管理与智能分镜控制面板。创作者可以在侧边栏实时监控生成进度,并通过“智能分镜”开关对镜头的叙事结构进行微调。从这一系列更新来看,可灵AI已经在从内容生成工具,开始转型为覆盖影像制作全流程链条的生产力平台。