关于豆包的Seed2.0,简体中文没有告诉你,这些非常要害和诚实的细节
字节在过年前发了Seed2.0,准备加持豆包投入一场首次中国全民参与的AI场景。
我们认真阅读了全英文的模型卡,Seed2.0: Towards Intelligence Frontier for Real-World Complexity。这份79页的文件,可能是自DeepSeek V3/R1以来,中国AI实验室最有意思的AI技术说明文献。Seed2.0的全部意义,并不在简体中文稿件里。
下面我们划下重点。
1,Seed想摆脱它与中国的开源模型站队,而是想定位为一家全球性的、一流的AI实验室。
读下这段:“Seed 模型并非轻量化对话模型,而是面向工作流的模型即服务(MaaS)基础模型,其核心能力聚焦于多模态理解、长上下文推理、结构化生成与工具增强执行,以可靠地完成企业端到端任务。
在全球范围内,这一技术路线与 OpenAI、Anthropic、Google Cloud 近期发布的企业人工智能报告方向一致,这些报告均将软件工程、科研、分析、客户支持与知识工作列为增长最快的企业人工智能应用领域。”
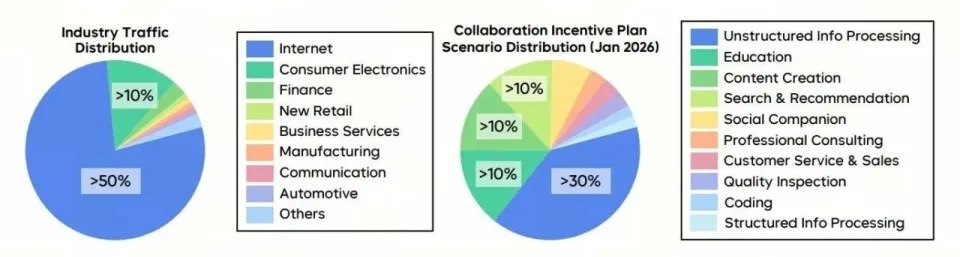
2,Seed公布了中国内地各行业和各应用场景的初步token用量,从中可以看出,中国的AI应用仍然由互联网绝对主导,从应用场景上看,高经济价值的应用占比非常小。
token消耗量
(来源:Seed2.0模型卡)
行业:从左图可以看出,互联网行业的流量(应该是token消耗量)占比超过75%,消费电子占比略超10%,其他所有行业如金融、新零售、商业服务、制造业、通信、汽车等,各自占比都不及1%。
应用场景:从右图来自字节合作奖励计划中的数据分布,可以看到非结构化信息处理占了近40%,其余的教育和内容创作各自占比约12%左右,搜索和推荐占比超过10%,社交陪伴约占8%左右,其余企业服务部分(to B)如专业咨询、消费服务和销售、质量检验、编程、结构化信息处理等,各自都占5%以下的比重。
以上说明中国大模型的应用,与中国的互联网行业高度同构,即绝大多数用于消费场景,而在企业服务方面发展较慢。
顺便说一句,当字节开始定期宣布它的token消耗数量时,就很快与Gemini和OpenAI处于一个量级。未尽研究也领先从token统计分析进行token经济研究:
从中美科技巨头的AI差距,看如何为自己创造出资本激励(2024/05)
英伟达4万亿美元,AI时代的叙事新起点(2025/07)
当世界被token淹没,价值去哪里了(2025/10)
豆包-Seed-1.8,每天50万亿token,字节跳动真实的世界野望(2025/12)
谷歌真正的token消耗、AI收入,还有翻倍的资本投入(2026/02)
3,Seed建立了一个新型的评测基准体系,包括这次新推出的完全自研、基于外部基准优化 / 适配、和自研子集 / 衍生版本三类。
完全自研且新推的基准:主要集中在 长尾专业知识(LPFQA/Encyclo-K)、中文复杂场景(中文复杂指令基准)、端到端生产任务(NL2Repo-Bench/Trae In-House Bench)、价值导向场景(ToB 系列 / WorldTravel)和 模型诊断(自动化行为诊断基准),核心是填补现有外部基准的评估缺口(如中文适配、企业实用价值、Agent 长周期任务)。
非完全自研的基准:主要是对外部成熟基准的 适配优化 或 质量提纯,目的是确保评估的客观性(与国际前沿模型对比)和可靠性(剔除低质量用例),避免重复造轮子。
设计逻辑:Seed2.0 的基准策略是 “自研补缺口 + 外部做对比”—— 自研基准聚焦真实场景、中文需求、价值落地等外部基准覆盖不足的领域,外部基准用于验证核心能力与国际前沿的差距,两者结合形成完整评估体系。
4,Seed在报告中披露,它在评测中采用了自己的token统计方式,与OpenAI的统计方式有所不同。

在长上下文多步推理基准(Graphwalks)中,Seed使用了内部自研的分词流水线,这导致在token统计方式上与OpenAI官方Graphwalks的分词和评分设置存在不一致,主要影响Graphwalks这类对token计数敏感的评测,但也会在一定程度上影响其他项目的结果。
在声明评测差异的前提下,Seed2.0公布与其他模型的对比,是为了清晰展示自身能力的区间和独特价值,这是行业内的一种惯例,客观上也能淡化“跑分竞赛”式的刷榜行为。
5,非常罕见,Seed2.0在中国的AI实验室的官方报告中没有隐瞒自己的差距。
“Seed2.0系列与国际前沿LLM相比仍存在差距。以SWE-Evo和NL2Repo为例,Seed2.0系列在编码方面与Claude存在相当大的差距。以SuperGPQA和SimpleQA-Verified为例,Seed2.0系列在与用户体验密切相关的长尾知识方面与Gemini存在较为明显的差距。”
SWE-bench 验证结果:Seed得分 76.5%,Opus 得分 80.9%。在业内公认的编码代理基准测试中,两者相差 4.4 分。在 NL2Repo(根据规范构建完整代码库)测试中,Seed 得分 27.9,而 Opus 得分 43.2。差距悬殊。
在SimpleQA-Verified这一事实准确性基准测试中,Seed的得分为36.0,而Gemini的得分为72.1。这相差36个百分点。
6,吴永辉参与过谷歌DeepMind追赶OpenAI;领导Seed实验室,正在追赶Gemini,OpenAI,还有Anthropic。
吴永辉2008年博士毕业后加入 Google,参与了谷歌最核心的搜索排名工程,在Google Brain推动深度学习改变翻译领域、并提升搜索排名算法;2023,在DeepMind与Google Brain合并后,成为谷歌DeepMind 研究副总裁,参与了Gemini对GPT-4的追赶与翻盘 。
2025年2月初,吴永辉加入字节,担任领导Seed实验室的副总裁。当时DeepSeek震撼了中美,并把Seed甩下。吴永辉相当于又在中国参与了一场追赶与翻盘。这一次是在中国闭源打开源。
模型卡中没有透露参数规模,据《晚点》报道,2.0是吴永辉接管Seed一年最核心的产出。它是一款类似Gemini的多模态模型,是Seed成立以来训练的最大模型,达到了万亿参数。
吴永辉的工作方式和模型目标,都带一定的谷歌DeepMind色彩,如多模态、长上下文,深度思考与分析能力,以及对科学智能的追求。他想把Seed做成一个研究品牌,同时具备很强的工程与产品能力,其中大量的经验,来自DeepMind。同时,2.0又强调它是一个能完成实际工作的目标,在AI编程方面对标Anthropic。
7,既然Seed2.0大方地承认了它在一些方面的不足,那么其他更多方面的逼平或者超越世界一流的评测得分,它也就当仁不让了。且看下表(字体加粗就是第一):
先看大型基础语言模型。Seed2.0 Pro落后于GPT-5.2 High和Gemini-3-pro-High,但领先于Clause-Opus-4.5。

再看效率型的基础语言模型,Seek2.0 Lite,落后于Gemini-3-Flash-High,和GPT-5-mini High

在视觉-语言的评测分数上,Seed2.0 Pro明显领先。
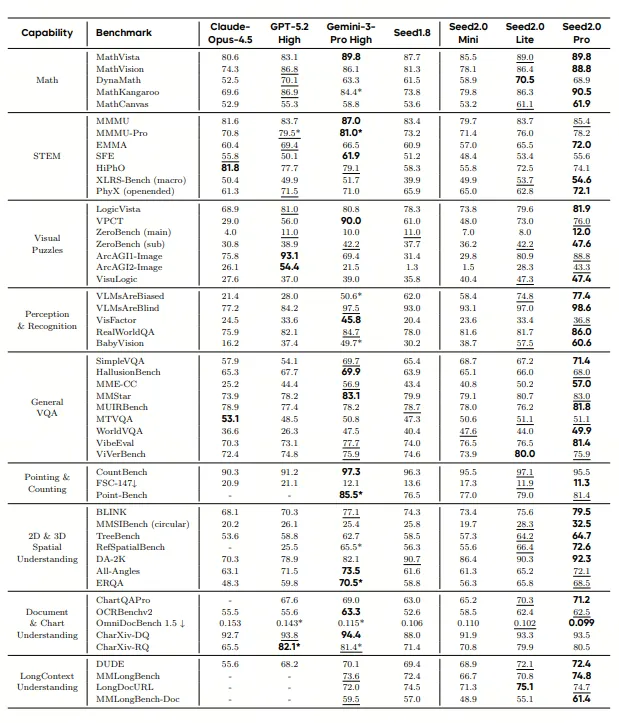
在公共视频理解方面,Seed2.0 Pro更是遥遥领先。

在大模型的基础智能体能力中,Seed2.0明显领先Gemini-3-pro-High,与GPT-5.2 High和Claude-Opus-4.5处于相当水平 。

在效率型的基础智能体能力方面,Seed2.0 Lite比GPT-5-mini-High和Gemini-3-Flash-High显示出一定优势。
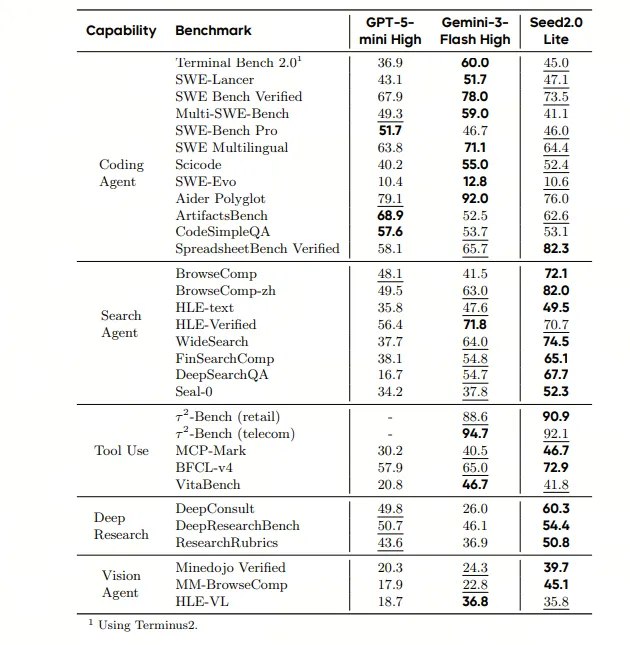
在大模型完成高经济与科学价值的评测中,Seed2.0落后于GPT-5.2-High,与Gemini-3-pro-High处于相当水平 。
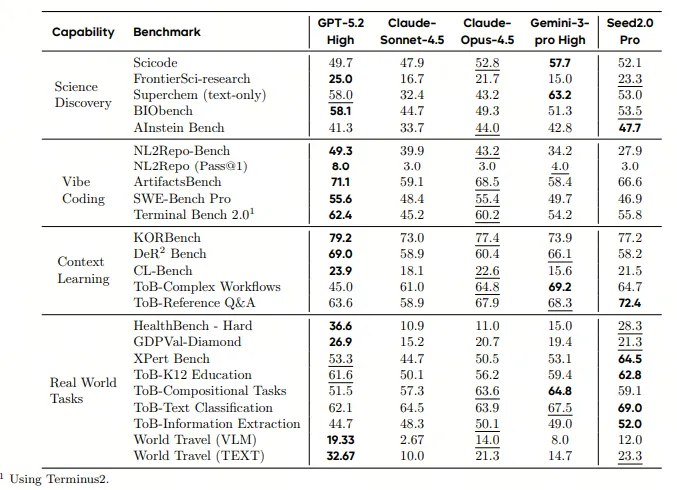
在效率基础模型完成高经济与科学价值的评测中,Seed2.0开始显示出优势,尤其是在真实世界的任务中。
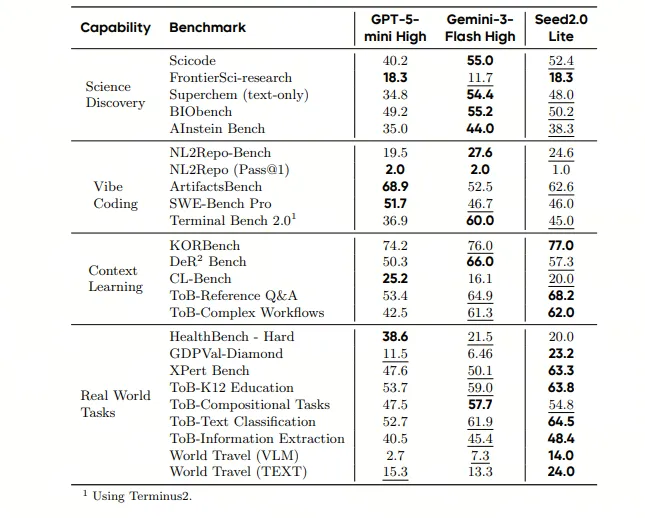
8,总之,Seed2.0在多模态、智能体的实际工作能力等方面实现了赶超,尤其是在视频理解方面,占据了明显的优势。在效率型模型的各方面能力上,开始显示出优势,这点表现与中国开源模型的比较优势一致。总体来说,作为中国的一家闭源模型,它理应达到总体上更加接近世界顶流AI实验室的水平——现在基本上实现了。但是,它还有一个巨大的优势,在于价格:
下面是API token预填充/解码(prefill/decode) 的价格比较(美元/百万token),Seed2.0在各个量级上,都保持了低一个数量级的价位。但是,在与美国对手竞争之前,它首先面临着中国开源模型更加激进低价的内卷。

Seed2.0的标志性意义在于,中国以开源模型军团作战、快速跟随为特色的AI竞争力,现在补上了闭源模型这一块,也有一家中国的实验室,可以步步紧逼和局部超越国际顶流AI实验室了。
One More Thing
与此同时,Seed还处于“技术补债”的过程当中,尤其是它的infra能否马上满足它的模型雄心,如它的视频生成的时延,在普通用户那里已经超过了一个小时;它的Seedance2.0视频训练数据引发了国际上的侵权谴责和调查;以及在发布和内部评测初期,在引起测评小圈子和自媒体尖叫的同时,一度违反了禁止deepfake、保护真人权益的国际AI惯例。
Seed2.0加持的豆包大模型,即将登场春晚,与参与地方电视春晚的其他模型一起,将共同形成第一个全国大型活动上的全民AI应用场景。Seedance2.0目前暂不支持输入真人图片或视频作为主体参考,也不支持生成涉及迪士尼、熊出没等IP形象的视频内容。
--
参考:
Seed2.0模型卡:
https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card.pdf