Boss直聘开源Nanbeige4.1-3B:小模型全能新标杆
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
近年来,大语言模型效果提升的背后也伴随着模型规模的不断膨胀,这一过程中带来的高昂推理成本与二次开发门槛,让众多企业与开发者望而却步。正因如此,"如何用更小的模型逼近甚至超过大模型的能力"成为业界一大火热课题。小模型推理速度快、部署成本低,若能在核心能力上媲美大模型,无疑将成为推动AI普惠落地的关键力量。
然而,现实中的挑战依然严峻,当前市面上的小模型普遍存在"偏科"问题:专注于解题的模型往往在长程交互(如深度搜索)上力不从心;而专注于代码或Agent的模型,又缺乏扎实的通用推理能力和人类偏好对齐能力。用户不得不在不同场景下切换不同模型,既增加了部署复杂度,也割裂了使用体验。
能否用一个3B参数的模型,同时做好通用问答、复杂推理、编程和深度搜索?Boss直聘南北阁实验室(Nanbeige LLM Lab)给出了肯定的答案——Nanbeige4.1-3B,一个"小而全"的统一通用模型。
Nanbeige4.1-3B的模型权重、技术报告、深度搜索合成数据均已开源,欢迎社区使用和研究。
ModelScope:https://modelscope.cn/models/nanbeige/Nanbeige4.1-3B
深度搜索合成数据:https://www.modelscope.cn/datasets/nanbeige/ToolMind-Web-QA
技术报告:https://modelscope.cn/models/nanbeige/Nanbeige4.1-3B/file/view/master/Nanbeige4.1-3B-Report.pdf?status=2
01
整体介绍
Nanbeige4.1-3B 基于Nanbeige4-3B-Base 进一步优化,是一款统一的通用小模型。它的核心突破在于:在同规模开源小模型中,首次将强推理能力、人类偏好对齐能力与深度搜索 Agent 能力系统性地整合于3B参数之中。
从评测结果来看,Nanbeige4.1-3B不仅显著超越同规模的开源小模型(如Qwen3-4B、Qwen3-8B),更在综合指标上超越了参数量大10倍的Qwen3-32B与Qwen3-30B-A3B:

这些成绩表明,通过精细的训练配方设计,小模型有能力在多个维度上同时达到甚至超越部分大尺寸模型的效果。
02
方法详解
Nanbeige4.1-3B的能力提升来自三个核心方向的协同优化:通用能力、深度搜索能力和代码能力。以下分别介绍这三个方向的技术亮点。
2.1 通用能力
在通用能力方面,从SFT数据构建到RL训练进行了全链路的优化。
SFT优化
相比前代Nanbeige4-3B-2511版本,Nanbeige4.1-3B在SFT阶段做了三方面升级:
指令配方优化:增加了代码相关数据的比例,同时引入更多数学和通用领域的难题,以强化推理深度;
上下文长度扩展:从原来的两阶段课程(32k → 64k)扩展到三阶段(32k →64k → 256k),更好地支持复杂推理和长程场景
回复质量提升:Solution Refinement与CoT Reconstruction框架的迭代升级,增加迭代优化的轮次提升答案质量,并训练了更强的CoT重构模型,生成更加忠实的推理路径

通过这些改进,Nanbeige4.1-3B相比Nanbeige4-3B在SFT阶段取得了显著效果提升,也为后续RL打下坚实基础

通用RL优化
在通用RL中,官方结合Point-wise RL与Pair-wise RL两阶段训练方式来提升偏好对齐能力,抑制模型错误回复。
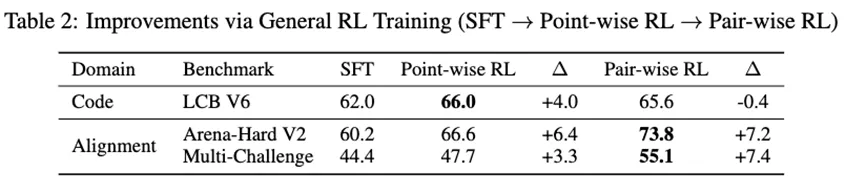
Point-wise RL:官方训练了一个通用Reward Model来评估模型生成的回答质量。这个Reward Model在大规模人类偏好数据上训练,能够自然地抑制过度冗长、重复和低可读性的回答。实验发现这一阶段Arena-Hard V2的表现显著提升,并且LiveCodeBench-v6上因格式错误率从5.27%降至0.38%,也带来了效果提升。
Pair-wise RL:在有了Point-wise RL的基础上,研究官方将模型置于和其他对手模型的PK竞赛场景下进行训练,并用一个Pair-wise Reward Model来给出奖励信号。实验发现,在进行过Point-wise RL的模型基础上,引入Pair-wise RL还可以进一步拔高效果,不仅能提升Pair-wise打分评测的Arena-Hard V2,而且也对
Point-wise打分的Multi-Challenge也取得了明显收益。
2.2 深度搜索能力
深度搜索是一种以检索为中心、需要复杂多跳推理和长上下文的任务范式。在这一任务下,模型需要与环境迭代交互来获取信息,从而解决具有挑战性的搜索问题。深度搜索能力是Nanbeige4.1-3B区别于其他通用小模型的重要特色。
为了增强模型的搜索能力,研究官方构建了一个大规模、复杂的搜索数据集,包含大量从Wikipedia实体关系图中衍生的多跳QA对,以及经过多阶段严格过滤的高质量长程搜索轨迹。
时序感知的随机游走问题合成
为了确保合成QA数据的时效性和复杂性,研究团队首先从Wikipedia中提取2025年更新的信息性首实体。然后执行条件随机游走以提取预定义长度的关系路径。这些关系链及其详细的时序上下文被输入到强LLM中,合成复杂QA。
轨迹合成与轮次级判断
在使用合成QA数据进行SFT轨迹构造和RL训练中,为了进一步保证合成数据的质量,实现了一个严格的轮次级判断机制。具体来说,研究团队使用一个critic模型从三个维度评估每次交互:逻辑合理性、工具调用准确性和信息增益。任何未能满足这些标准的轮次在SFT中不会参与loss计算,在RL中则会为模型提供负向reward。这种细粒度过程奖励与监督为SFT和RL提供高保真信号。

研究团队在Nanbeige4-3B-2511模型上验证了该数据合成管道的有效性
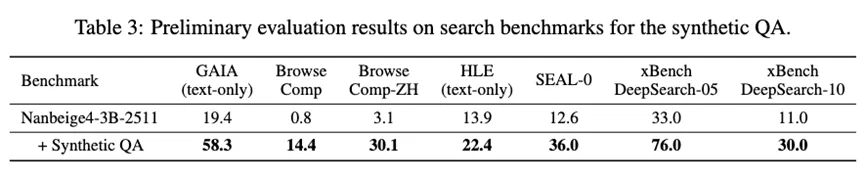
可以看到,引入合成数据后,模型在所有基准测试上都取得了显著的提升,这充分证明了数据管道的有效性,能够有效赋予模型充分的长上下文多跳推理能力,官方也将这一数据进行开源来支持社区的搜索agent相关研究。
2.3 代码能力
在代码能力方面,研究团队设计了一套多阶段训练策略,让模型写的代码不仅正确,而且具有更低的时间复杂度。
两阶段RL训练
Stage 1:正确性优化
第一阶段优化解决方案的正确性,使用pass-rate reward,定义为每个问题通过的测试用例比例。这一阶段的目标是确保模型能够可靠地解决问题。
Stage 2:复杂度优化
当模型能够可靠地做对算法问题后,在第二阶段额外鼓励更高质量的解决方案。
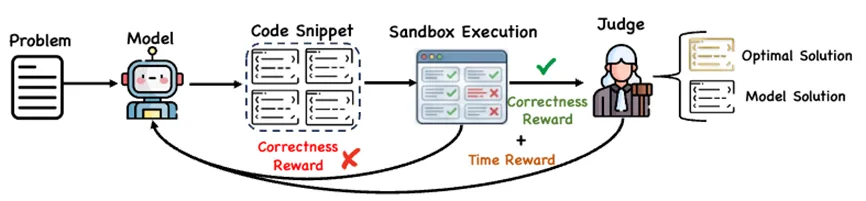
具体来说,仅当所有测试用例都通过时才引入时间复杂度reward;否则reward退化为仅与正确性相关的信号。Judge系统通过在线比较模型输出的预测时间复杂度与参考最优边界来提供反馈,reward公式如下所示:
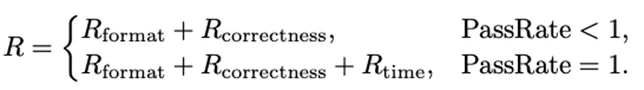
这种"门控"设计确保模型首先学会正确解题,然后在此基础上优化算法效率。
训练动态曲线
在两阶段代码RL过程中,观察到reward信号和下游代码指标的一致提升:
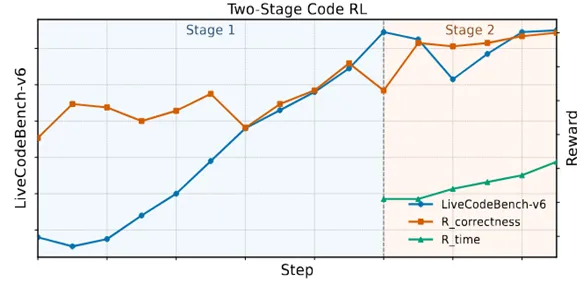
Stage 1中,正确性reward快速上升,反映出生成正确解决方案的能力迅速提升
Stage 2中,正确性reward提升较为平缓,而时间复杂度reward大幅上升,表明策略在正确性达成后,聚焦在生成兼顾正确性与低复杂度的代码
2.4 Nanbeige4.1训练配方
Nanbeige4.1-3B的整体训练流程可以概括如下:
SFT:最大长度从64K扩展到256K,结合数据配方的迭代以及回复质量的升级
General RL:先进行Point-wise RL,再进行Pair-wise RL
Code RL:两阶段训练(正确性阶段 → 复杂度阶段)
Agentic RL:最后进行工具调用和深度搜索能力强化这种分阶段、分领域的优化策略确保模型保持各领域的专长,以及领域间的能力平衡。
03
实验评测
3.1 通用任务评测
在代码、数学、科学、偏好对齐和工具调用五个大类上对Nanbeige4.1-3B进行全面评测:
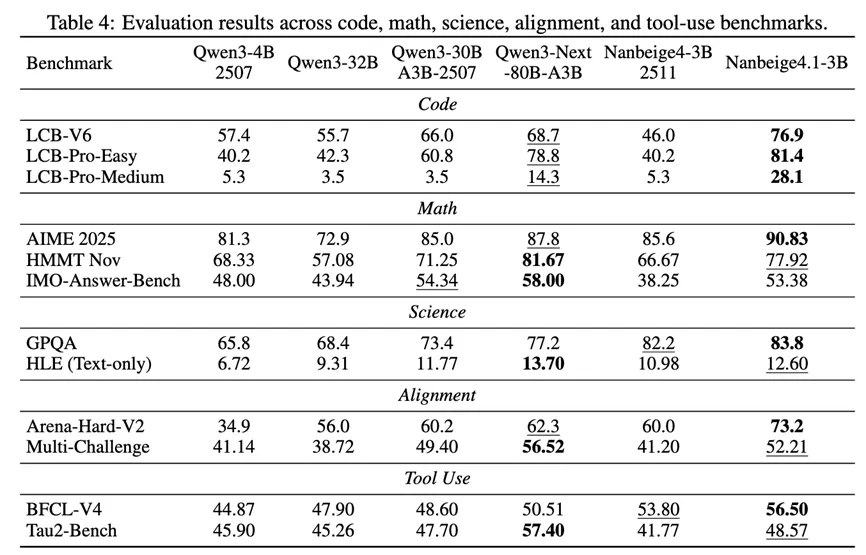
Nanbeige4.1-3B在各个评测维度上均显著优于 Qwen3-4B-2507 以及上一代模型 Nanbeige4-3B-2511。此外,尽管模型规模仅为 3B 参数,Nanbeige4.1-3B 在多数基准测试上持续超过10倍参数规模的Qwen3-30B-A3B-2507与 Qwen3-32B。更值得注意的是,在与更大规模的 Qwen3-Next-80B-A3B 模型对比中,Nanbeige4.1-3B 依然保持竞争力,在各个指标上互有胜负。
3.2 深度搜索任务评测

现有的通用小模型(如Qwen3、Nanbeige4-3B-2511)在深度搜索任务上均表现欠佳,而Nanbeige4.1-3B能够可靠地解决复杂搜索问题,例如在xBench-DeepSearch-2505上取得75分,在GAIA(text-only)上取得69.90分,这一成绩也能和专业的搜索Agent(如AgentCPM-Explore-4B)相当。这表明,当训练目标和信用分配机制设计得当时,通用小模型也能够具备长程搜索Agent能力。
3.3 真实竞赛挑战
除了学术基准测试,官方还在2026年1月以来举办的竞赛任务上对Nanbeige4.1-3B进行评估,从而更加客观真实地反映模型能力。
LeetCode编程周赛
收集2026.1-2026.2的四期LeetCode周赛题目进行评测,来验证模型编程能力。

Nanbeige4.1-3B成功解决了20道题中的17道,总体通过率达到85.0%。在模型虚拟参赛模式下,Nanbeige4.1-3B在第487场周赛中获得第1名,在第488场周赛中获得第3名。相比同规模或更大规模的Qwen3模型,Nanbeige4.1-3B在真实竞赛任务上展现出明显的性能优势。
AIME2026数学竞赛
我们收集2026.2举办的AIME2026数学竞赛题目进行评测,来验证模型推理能力。

Nanbeige4.1-3B在I卷和II卷中均显著超过同参数规模的Qwen3-4B-2507。整体效果介于Qwen3-30B-A3B-2507和Qwen3-Next-80B-A3B之间,充分证明了其强大的数学推理能力。
04
总结与展望
Nanbeige4.1-3B的发布证明了:通过精细的训练流程优化,3B参数的小模型已经具备在多个核心维度接近甚至超过部分大模型的能力。
核心贡献如下:
通用能力:通过SFT配方优化和Point-wise + Pair-wise RL的结合,实现了推理能力和人类偏好对齐的双重提升;
深度搜索:通过创新的数据构造流程和轮次级监督信号引入,让通用小模型也兼备了强大的长程搜索Agent能力;
代码能力:通过两阶段RL训练(先学正确性,再学复杂度),让模型写出既正确又高效的代码
在未来,Nanbeige团队将继续探索小模型在复杂代码场景、研究场景、其他真实工业场景的能力边界。同时,也将探索如何通过架构创新来更充分地释放小模型的潜力。
作者团队:Nanbeige LLM Lab, Boss直聘
联系方式:nanbeige@kanzhun.com
预训练与后训练各方向持续招募中,欢迎加入!