Agent全链路成功率0%?首个真实DevOps基准曝致命短板|ICLR'26

新智元报道
新智元报道
【新智元导读】AI能写代码,却修不好构建环境、看不懂系统监控、串不起全链路运维——新基准DevOps-Gym显示,顶级模型在真实软件工程任务中全链路成功率归零,暴露其缺乏长程推理与动态系统理解能力,AI辅助编程远未触及真实开发核心。
随着LLM的爆发,Coding Agent似乎已经无所不能:写函数、修Bug、甚至刷LeetCode,但任何一位在一线摸爬滚打过的软件工程师都知道,写代码(Coding)仅仅是软件工程(Software Engineering)的一小部分。
在软件工程领域,尽管AI Agent在代码生成方面表现出色,但在处理真实的DevOps全链路时能力依然未知。
在真实世界中,一个代码变更的生命周期是漫长而痛苦的: 你需要搞定复杂的构建环境(Build & Config); 你需要将代码部署上线,并盯着仪表盘监控它是否导致了内存泄漏(Monitoring); 当警报响起,你需要从日志中定位问题并修复(Issue Resolving); 最后,你还得补上回归测试,确保问题不再复发(Test Generation)。
实际开发不仅是写代码,更涉及复杂的环境构建、运行时监控、故障排查与测试验证,现有的评估基准大多局限于独立的编码任务或模拟环境,缺乏对真实运维场景的覆盖 。
目前的Benchmark(如SWE-bench或HumanEval)大多只关注「写代码」这一环。
为填补这一空白,UCSB、NUS与Berkeley等联合团队提出了首个针对DevOps核心工作流(构建配置、监控、问题修复、测试生成)的端到端评估框架DevOps-Gym,不仅要评估 AI 「写」代码的能力,更要评估其「运维」和「治理」代码的能力。

论文链接:https://arxiv.org/abs/2601.20882
主页链接:https://www.devops-gym.com/
DevOps-Gym包含来自30+个真实Java和Go项目的700+个任务,并提供全容器化的执行环境。
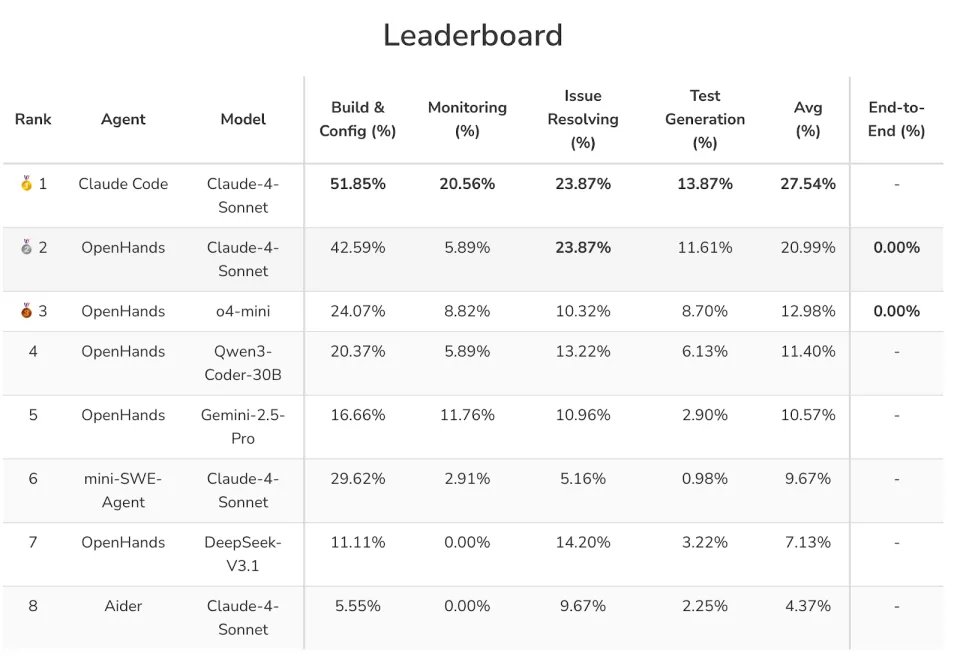
实验表明,即使是SOTA模型(如Claude-4-Sonnet),在构建与配置任务上的成功率仅为51.85%,监控任务仅为20.56%,而在全链路流水线任务中成功率更是为0%,揭示了当前AI在处理动态系统与长链路推理上的显著短板。
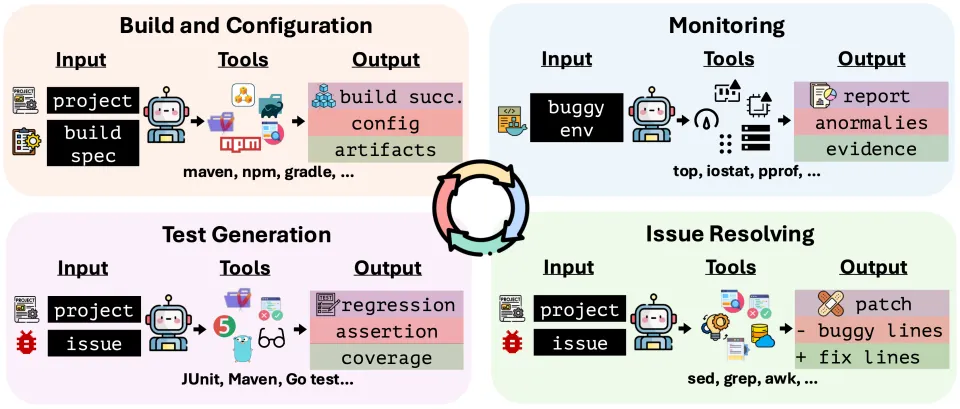
DevOps-Gym是首个针对软件DevOps全生命周期的端到端Benchmark,研究人员没有使用模拟环境,而是基于30+个真实的Java和Go开源项目,构建了700+个真实任务。
在这个Gym里,Agent需要像人类工程师一样,在隔离的容器环境中,通过命令行工具与系统交互,覆盖了DevOps的四大核心阶段:
构建与配置 (Build & Configuration):Agent 的「盲区」
这可能是目前 AI 最不擅长的领域,任务不仅仅是简单的编译,还包括:
环境修复:解决依赖版本冲突、构建配置错误、工具链不匹配等「环境地狱」问题。
系统迁移与升级:例如,将一个大型项目的构建系统从 Maven 迁移到 Gradle,或者升级关键依赖版本。
挑战:这要求 Agent 深入理解构建工具的内部机制(Internal Mechanics),而不仅仅是根据报错修代码。
监控与异常检测 (Monitoring):像侦探一样工作
这是现有Benchmark极少涉及的领域,模拟了应用上线后的运行时环境:
场景:系统正在运行,但存在隐患。Agent 无法直接查看源码,只能通过
top,iostat,netstat,ps等标准命令行工具来观察系统。任务:诊断性能异常(I/O 瓶颈、SQL 查询低效)或资源异常(内存泄漏、磁盘耗尽、CPU 尖峰)。
挑战:很多异常是渐进式的(如内存缓慢泄漏),Agent 往往难以在长周期的日志流中保持注意力,或者将正常的系统波动误判为异常。
问题修复 (Issue Resolving):跨越语言的鸿沟
基于真实的GitHub Issue和PR构建任务。与SWE-bench不同的是,该基准专注于Java和Go项目。
实验表明,从Python切换到这些编译型语言后,由于涉及复杂的编译过程和更严格的类型系统,Agent的表现出现了断崖式下跌。
测试生成 (Test Generation):闭环的关键
Agent必须在不看修复代码的情况下,仅根据Bug描述编写回归测试。
挑战在于,生成的测试必须满足「Fail-to-Pass」标准——在Bug版本上失败,在修复版本上通过,要求Agent对程序的运行时行为有极强的推理能力。
为了模拟最真实的生产环境,研究人员设计了18个全链路流水线任务 (End-to-End Pipelines)。
规则很残酷,Agent必须连续完成Build → Monitor → Fix → Test的全过程,这是一个串行任务,任何一个阶段失败(比如构建没修好,或者监控没发现问题),整个 Pipeline 直接终止。
研究人员评估了包括Claude-4-Sonnet、OpenAI o4-mini、DeepSeek-V3.1等在内的SOTA模型。结果如下:
全链路全军覆没:在End-to-End Pipeline任务中,目前所有Agent的成功率均为0%,这说明Agent极度缺乏在长链路任务中保持上下文和跨阶段推理的能力。
构建与监控是短板:即使是表现最好的Agent (Claude Code),在构建任务上的成功率也仅为51.85%,而在监控任务上仅为20.56%。
监控中的「注意力涣散」:研究人员发现Agent在监控任务中经常「走神」。面对不断刷新的系统状态,它们往往过度关注早期的观测结果,而忽略了后续出现的关键异常信号。
非Python语言的弱势:在Issue Resolving任务上,同样的模型在Python Benchmark上表现出色,但到了Java/Go环境中,能力大打折扣(例如Claude-4-Sonnet + OpenHands仅有23.87%的修复率)。这可能与预训练数据中Python的主导地位有关。
全容器化环境 (Dockerized Environments)
所有的任务都在隔离的、可复现的Docker容器中运行。
兼容TerminalBench格式
为了方便社区接入,完全复用了TerminalBench的标准格式。只需一行命令即可启动评估,获得Pass/Fail结果。
拒绝数据污染
为了确保评估的公正性,采用了严格的去污染流程,剔除了可能存在于训练数据中的代码库,同时移除了所有的Git Metadata,确保Agent无法通过 git log 或查看历史提交来「作弊」获取修复方案——这是此前一些Benchmark中存在的漏洞。
DevOps-Gym的发布揭示了一个事实:AI辅助编程正在走向成熟,但AI辅助软件工程(AI for SE)才刚刚起步。
如果不解决构建环境的复杂性、运行时监控的动态推理以及长链路的上下文保持问题,AI Agent就很难真正接管生产环境的DevOps工作,希望DevOps-Gym能成为衡量这一领域进展的标尺。