第一次,多模态大模型学会边看边听,Meta新作性能暴涨113%

新智元报道
新智元报道
【新智元导读】Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。
现在最强的多模态大模型,虽然能接收声音和视频输入,但无法做到真正的「同时理解」。
在第一视角视频任务中,模型经常会出现各种问题,比如完全忽略音频信息、错误判断声源位置、用视觉线索「猜声音」,也就是说,现在的多模态大模型只会看,但不会听。
而这正是当前具身智能的一大瓶颈。
Meta研究团队发现:最大瓶颈在数据,而非模型。

论文链接:https://arxiv.org/abs/2602.06139
代码:https://github.com/facebookresearch/EgoAVU
数据:https://huggingface.co/datasets/facebook/EgoAVU_data
当前主流数据集存在三个致命问题:视觉中心化严重、缺乏真实音频语义、没有跨模态关联标注,结果就是导致模型从来没有真正学过如何理解声音与视觉之间的关系。
为解决这一难题,Meta提出了首个自动化音视频数据引擎EgoAVU,是一个全新思路,直接自动生成跨模态数据,论文已被CVPR2026接收

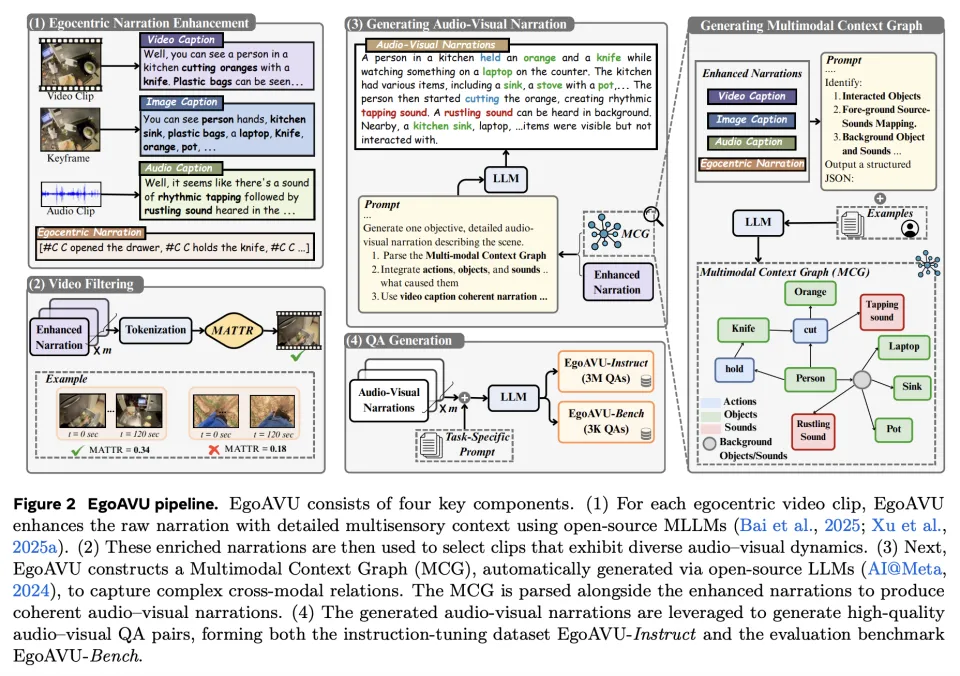
EgoAVU是一个完整的数据生产系统,可以自动理解视频中的声音-视觉关系、自动生成高质量问答与叙述数据、自动筛选最具跨模态信息的视频,最终形成可规模扩展的数据流水线。
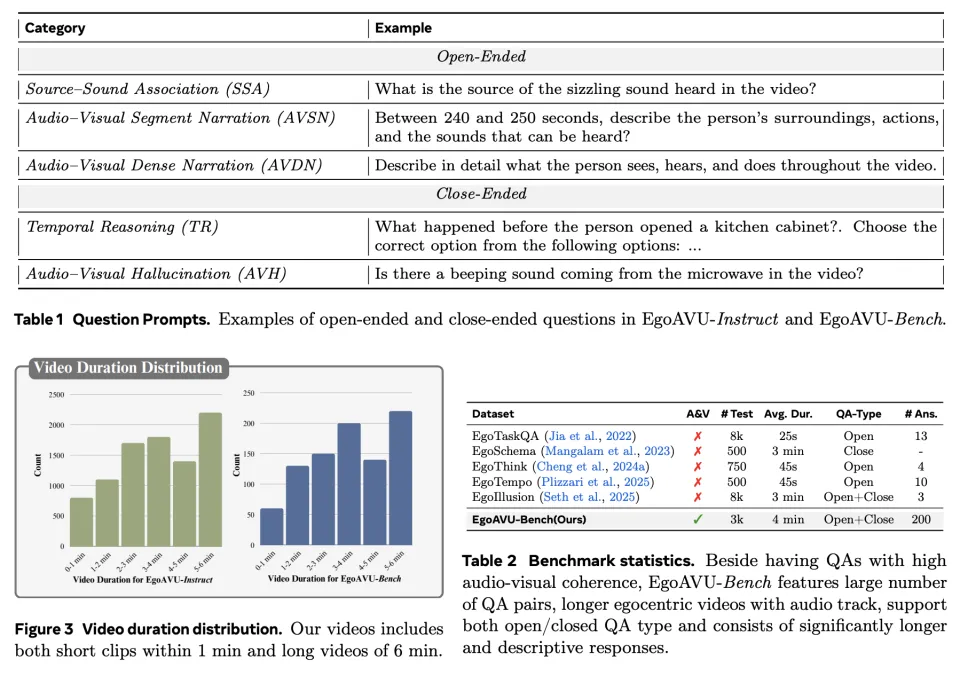
基于EgoAVU,团队构建了两个重要资源:
300万条训练样本,覆盖5大任务:
声源关联(Source–Sound Association, SSA)
问:视频里听到的某个声音(比如滋滋声)来自哪里/什么物体?
音视频片段叙述(Audio–Visual Segment Narration, AVSN)
问:在某个时间段(如 240–250 秒),描述周围环境、人物动作,以及能听到的声音。
音视频密集叙述(Audio–Visual Dense Narration, AVDN)
问:对整个视频进行更全面、更细节的「看到了什么/听到了什么/做了什么」的密集描述。
时序推理(Temporal Reasoning, TR)
问:某个动作之前/之后发生了什么,通常是多选或从候选项中选择。
音视频幻觉检测(Audio–Visual Hallucination, AVH)
问:视频里是否真的存在某个声音/事件(例如「微波炉有没有哔哔声」),用于检测模型是否「编造」。
首个专门评测音视频理解能力的基准,包含3000条人工验证问题。
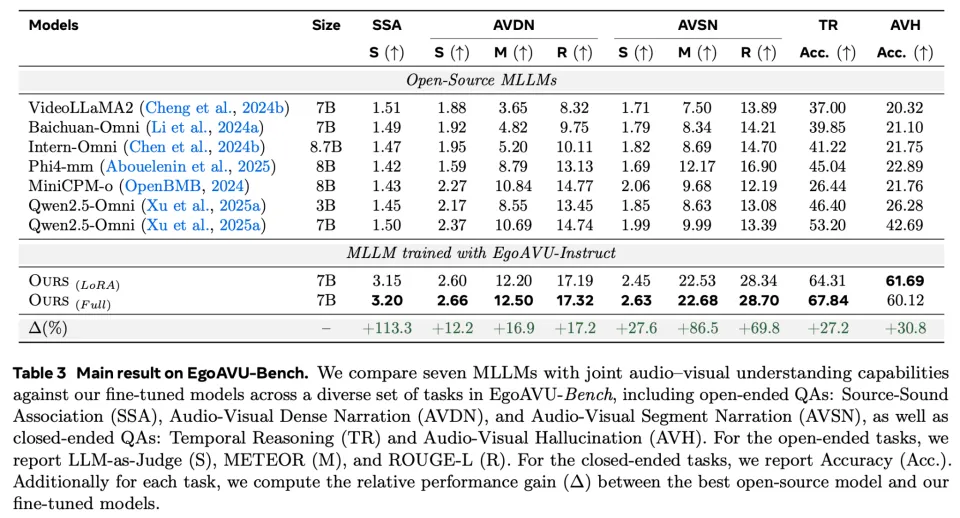
实验结果显示,在新数据上微调后,Benchmark性能最高提升113%、其他任务最高提升28%
研究进一步揭示:当前多模态模型普遍存在严重视觉偏置。
EgoAVU带来的最大启示是:未来AI竞争的关键,可能不是「模型结构」,而是「数据引擎能力」。
这标志着多模态AI正在从「模型驱动」迈向新的技术范式「数据驱动」。
第一视角音视频理解是机器人感知、自动驾驶、AR/VR、可穿戴AI的核心基础能力。
EgoAVU为这些领域提供了关键突破,让多模态大模型第一次真正学会「听懂第一视角世界」。

论文一作Meta的实习研究员来自马里兰大学的博士生Ashish Seth,指导老师蔡志鹏是Meta的高级研究员,主要研究方向是优化、感知和多模态生成等通用计算机视觉/机器学习问题,论文曾评为ECCV18年12篇最佳论文之一,获得英特尔实验室2024年最佳学者奖。
