全球首个!中国团队发布“磁性材料基座模型”,背靠国产芯片

文丨苏扬
编辑丨徐青阳
2025年底上市的沐曦股份,试图通过AI4S这条路径,拓展国产GPU的新布局。
日前,沐曦股份宣布与清华大学等多家机构共同发布磁性材料AI原子基座模型,并强调该模型是全球首个覆盖宽温压域的磁性材料AI原子模型。
磁性材料广泛用于消费、工业等不同的领域,常见应用包括电机、变压器及存储等,不过行业共同面临着新材料可预测却做不出来的难题。
一位研究员在现场表示,“磁性数据算不准、原子-磁矩耦合导致纯原子模型无法计算、推理运算慢且易出现能量发散。”
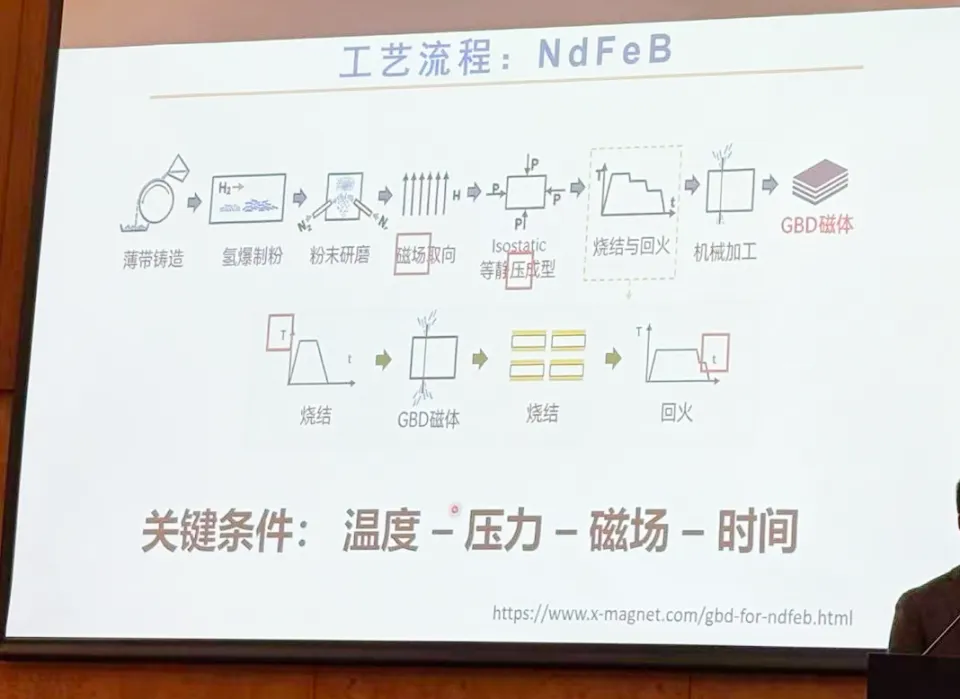
以钕铁硼(NdFeB)永磁材料的制备为例,其生产工艺包含了薄带铸造、磁场取向等环节,其中温度、压力、磁场和时间是影响最终磁体的微观结构和宏观性能的关键因素,且磁性能是从原子级到宏观级(1mm)的多层结构共同决定的,任何一个尺度上的结构缺陷,都会影响最终的性能表现。
在这个问题上,传统模拟技术难以适配实际应用中的复杂温压环境。
前述研究员强调,我们预测了“成分+理想晶体”,却没法预测“工艺→组织”。
此次发布的磁性材料AI原子基座模型,首次解释了不同原子和磁矩构型的演化机制,并以此为基础搭建起全球首个宽温压域磁性材料数据库。该数据库囊括47种合金元素、6000余种磁性合金体系、70余万组非平衡态与非共线磁性材料数据,模型可在微纳米尺度同时精准预测原子排布与磁矩转动,稳定覆盖0-1000K温度、10GPa压强的宽域温压工况。
研究团队强调,模型真正实现了磁性材料原子级的宽域、高精度、高可靠性模拟。
据介绍,基于研发团队自主开发的DeltaSPIN、DeepSPIN和TSPIN计算框架,同时融合国产软件DeepMD-kit和ABACUS:首次实现原子+磁矩+极化的一体化模拟计算,在磁性材料领域完成缺陷工程的计算模拟,让运算速度提升两个数量级、精度提升四个数量级。这一突破为磁性材料的预测和设计提供了高精度、可迁移的基座模型,也为下一代高性能磁性功能材料在新能源、电子信息等领域的研发提供底层技术支撑。
作为中国AI4S领域新进展,磁性材料AI原子基座模型的底层算力底座由沐曦提供。
“算力成本共同承担,我们参与扶持,”沐曦股份高级副总裁孙国梁表示,“毕竟是国家项目。”
此前,1月份沐曦股份刚刚发布了面向科学场景和高性能计算的曦索X系列,旗舰型号X206拥有全自研GPGPU架构、128GB超大显存、MetaXLink多卡互连技术等核心优势,可灵活适配材料模拟、气象海洋分析、生命科学探索等多种科研计算任务。
根据沐曦提供的信息,其GPU支持完整的材料科学模拟计算生态,包括:第一性原理材料计算、分子动力学模拟、通用势函数、高通量材料筛选、逆向材料生成模型等,兼容ABACUS、CP2K、Lammps、DeepMD-kit等国内外主流科学计算软件,其自研的MXMACA软件栈也实现了科学计算软件的平滑迁移,无需代码重构。
据介绍,在构建70万组宽温压域原子-磁矩双耦合结构数据集和模型训练过程中,基于其GPU高带宽、高稳定性特点,大幅度提升研发效率。
“原本需要一个月才能完成的计算量,如今仅需一天即可高效达成,”孙国梁表示,“现场的算力部署很快,模型的语料准备则相对耗时。”
相比通用大模型的训练和推理、算力竞争,海外巨头们在AI4S领域均已经加码布局。
2025年10月,英伟达宣布与甲骨文展开合作,为美国能源部旗下国家实验室打造百亿亿次规模的 AI 超算集群,其中阿贡国家实验室将落地Equinox和Solstice两套核心超算系统,分别搭载1万块、10万块Blackwell GPU,两套系统合计FP4精度总算力达 2200EFlops(22 万亿亿次浮点每秒),将主要服务于材料设计、清洁能源、量子计算融合等跨学科前沿研究。
同期,AMD也与美国能源部达成重磅合作,联合HPE、甲骨文等企业斥资超10亿美元,为橡树岭国家实验室打造Lux和Discovery两款新一代AI超级计算机,其中定位为美国首个 “科研AI工厂” 的Lux超算将于2026年初率先启用,搭载AMD Instinct MI355X GPU、EPYC CPU及 Pensando网络技术,主打大规模AI训练与分布式推理,为核聚变能源模拟、癌症分子层面治疗方案研究等前沿课题提供近端算力支撑。
尽管两家都提及了科学场景的应用,不过在官方新闻稿中都未提及FP64的算力,根据第三方的数据,英伟达B200的FP64算力为45TFLOPS,AMD MI355X约78.6TFLOPS。
“AI4S是个方向,有一定空间,目前还不是很大,”一位国产芯片从业者说,“小众的赛道或市场空间,还不会有大厂来卷,埋个种子进来。”
趋势很清晰,但对于仍然在追赶算力的国产芯片来说,押注相对冷门的AI4S市场,需要更长远的眼光和定力,一个核心点在于——AI4S领域的科学计算,依赖FP64高精度,大模型的训练则是在往FP8甚至更低精度进化。
如果要支持FP64这种高精度的科学计算,就需要兼顾设计、生态与制造上的成本,就会拖累业绩表现。
另外,由于英伟达面向大规模AI训练的B300系列,缩减FP64硬件计算单元,将资源向 FP8/FP4等AI低精度算力倾斜,这也会引发一个问题:国产芯片会不会为了增加FP64高精度计算,牺牲FP8算力的问题。
“我们的计算单元都是各分开的,”沐曦股份高级副总裁孙国梁强调,不会因为支持高精度,而牺牲大模型需要的低精度,“曦索X系列在做科学计算的同时,在性能不减的情况下,同时支持大模型的推理计算。”