清华发布世界模型评测新标尺:直击机器人感知与行动鸿沟
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
高画质视频掩盖了机器人在真实物理世界中决策能力的严重不足。
当前,大家习惯用视频画面美感来衡量模型的优劣,却忽略了机器人在实际任务中是否真的能用这些模型来完成动作。
清华大学等机构联合推出了名为 WorldArena 的统一评测基准,专门用来测试 EWM (具身世界模型) 的真实能力。

这个体系不仅包含十六项细致的视频质量客观指标,还直接让模型在模拟环境中去当教练、当考官、当大脑,配合人类主观评价,生成一个综合评分 EWMScore。
对十四款主流模型的测试结果扯下了一块遮羞布,揭示出优秀的视觉感知完全不等于强大的具身任务执行力。
华丽视频背后的具身智能困境
很多人在闭上眼睛准备投篮时,脑海中会自然浮现出篮球划过半空的抛物线,预测球体入网的瞬间。
机器人的大脑也需要这种能力。科学家们将这种能力赋予了 WM (世界模型),让机器人通过观察当前的环境和自身即将采取的动作,在脑海中推演未来的状态。
拥有这种推演能力的 EWM 就成为了机器人行动的脑内模拟器。
它可以指导机器人规划动作,制定决策,甚至可以作为一个纯虚拟的环境代理,用来低成本、大规模地训练和评估其他机器人控制算法。这种模型不同于大家平时用来做影视特效的通用视频生成模型。
通用视频模型只需要负责画面好看,符合大众的视觉审美即可。
EWM 却必须死死咬住物理规律,保证生成的每一帧画面都符合真实的物理互动。水不能倒流,苹果掉在地上必须弹起,机械臂抓取物体必须有受力形变。
现有的评测规则完全跑偏了。当前的测试基准绝大多数还在盯着视频层面的质量打分,依然在用评判好莱坞大片的眼光去审视一个需要去工厂拧螺丝的机器人大脑。
只看画面清晰度和流畅度,完全体现不出模型在闭环决策任务中的真实价值。
目前也有少部分研究开始让模型去执行闭环动作,但依然忽略了它们作为合成数据引擎或策略评估工具的巨大潜力。
测试对象的覆盖面也十分狭窄。
主流测试台基本都在围着那些根据文字描述生成视频的通用大模型转。最近涌现出大批专门针对机器人操作设计的世界模型,它们被晾在了一边,缺乏系统性的关注和统一的衡量标准。
WorldArena 的诞生彻底填补了这一空白。
这是首个将感知评估与功能评估深度融合的具身世界模型测试基准。
它把客观的数字指标与人类的主观感受结合在一起,为全行业提供了一把精准的标尺。
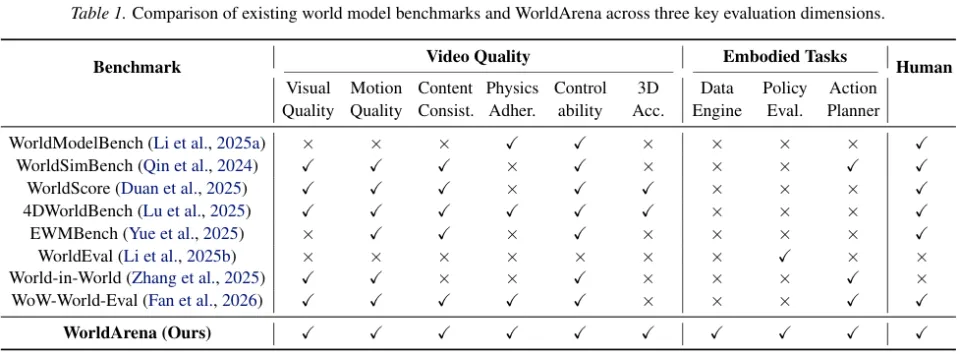
上面这张表格清晰对比了现有测试台的局限性。
我们可以看到,以往的平台要么只测画面不测闭环任务,要么只测单一任务。
WorldArena 像一张细密的大网,把视觉质量、运动规律、内容一致性、物理依从度、可控性、三维准确度以及三大具身任务全部网罗其中。
重构评测维度的全景试验场
为了保证测试的全面性,WorldArena 搭建了三大核心测试模块。
测试的不仅有开环状态下生成视频的能力,还有闭环状态下执行典型具身任务的表现。人类评委的加入填补了冰冷代码无法察觉的主观体验盲区。
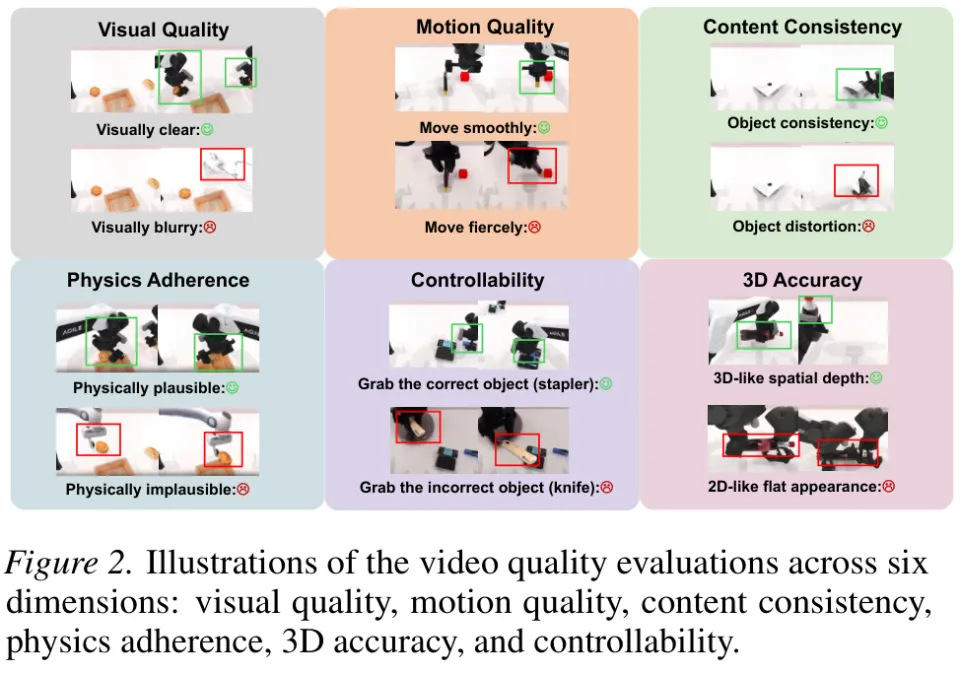
视频质量测试被拆解成了六个大方向,下面挂着十六个极其苛刻的量化指标。
视觉质量考察的是生成的画面是不是像现实世界一样清晰自然。
模型会利用 MUSIQ 这种专门寻找画面瑕疵的工具,揪出过度曝光、噪点和压缩痕迹。LAION 审美预测器则像一个挑剔的美术老师,给画面的光影和色彩构图打分。
运动质量用来检验画面里的物体动起来是不是符合物理学常识。
利用 RAFT 光流模型提取相邻帧之间的运动向量,考察机器人的手臂挥舞是否有力。模型还需要判断这些动作在时间轴上是不是连贯平滑,杜绝出现瞬移或者卡顿。
内容一致性是一个找茬游戏。测试系统利用 DINO 提取画面特征,死死盯住目标物体,确保它在视频的开头、中间和结尾没有发生外貌突变。
背景稳定性同样受到监控,防止机器人在运动时背景出现诡异的扭曲。
物理依从度直接决定了这算不算一个合格的机器人模拟器。
Qwen3-VL 被请来充当物理规律裁判,专门审视机器人和物体接触的那一瞬间。比如受力传递是否合理,有没有出现手穿透桌子这种荒谬的画面。
三维准确度主要防范模型生成那种看起来很美但实际上是平面纸片人的画面。
通过对比生成视频和真实视频的深度图,系统可以验证物体在三维空间中的几何结构是否得到了保留。
可控性测试的是模型听不听话。
通过比对文本指令和最终生成的视频内容,系统会打分判断机器人有没有认错目标物体,有没有执行错误的动作类型。这就像在考核一个员工是否精准理解了老板的任务分配。
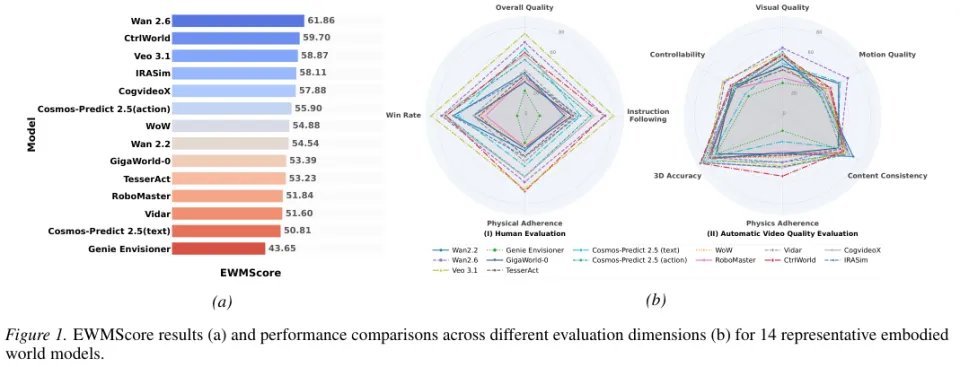
下图是14款代表性具身世界模型在不同评估维度上的表现对比。
除了给视频打分,让模型真刀真枪地下场干活才是 WorldArena 的重头戏。
测试组挑选了双臂机器人操作作为核心场景,使用了包含五十种复杂操作任务的 RoboTwin 2.0 数据集。
第一个任务是让模型当数据合成引擎。
现实中教机器人干活需要大量人类演示数据,这些数据极度匮乏且昂贵。
世界模型根据指令生成包含未来观察画面的视频,配合反向动力学模型提取动作,就可以合成出海量的免费教材。
拿这些合成教材去教一个新的机器人,新机器人的任务成功率提升了多少,就是世界模型当引擎的成绩单。
第二个任务是充当策略评估官。
通常我们需要把新研发的控制算法放进真实的物理模拟器里跑分。
现在把物理模拟器替换成世界模型,让它来和算法互动并生成动作结果。
如果世界模型给出的成功率和真实物理模拟器给出的成功率高度一致,说明它完美复刻了真实环境的动态规则。
第三个任务最考验综合能力,让世界模型直接充当行动规划器。
它需要像人类大脑一样,接收到指令后,预测出一条通往成功的视频画面路径,然后将这条路径转化为可以直接控制机器人关节的指令串。
这串指令会被输入到物理模拟器中执行,动作成功就是满分,失败就是零分。
人类评价环节由七十位专门招募的标注员组成,他们一共观看了三千五百段测试视频。
评委不仅要给每个视频在整体质量、指令遵循和物理依从度上打分,还要在面对同一个指令生成的两个不同视频时,强行选出一个优胜者,从而产生胜率指标。
最终系统会将所有维度的得分进行线性归一化处理,统一映射到零到一百的区间内,计算出算术平均值。
这个诞生出来的终极数字就是 EWMScore。这是一个客观、自动化且极具解释力的生成质量综合指数。
揭开感知与功能的真实差距
研究团队将十四款模型拉到了同一条起跑线上。
这里面既有 CogvideoX 这样的开源通用视频生成模型,也有 Wan 2.6 和 Veo 3.1 这类闭源商业大模型。
具身专用的模型队伍同样庞大,涵盖了依赖纯文本驱动的 Genie Envisioner 以及深度绑定动作条件的 CtrlWorld 和 IRASim 等实力派。
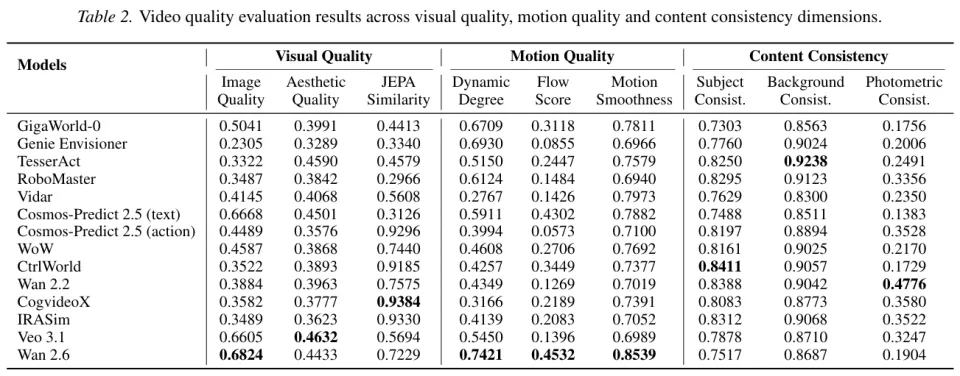
静态视频质量的较量结果如上表所示。总体来看,两大阵营的特长泾渭分明。具身专用模型在结构和物理互动相关的指标上优势显著,通用视频大模型则在画面美感上一骑绝尘。
CtrlWorld 和 TesserAct 在主体一致性和背景稳定性上拿到了高分,它们的轨迹准确度也很高。
这得益于它们专门针对机械臂动态特性的训练。Veo 3.1 和 Wan 2.6 这两位商业选手毫无悬念地摘取了视觉和美学分数的桂冠。
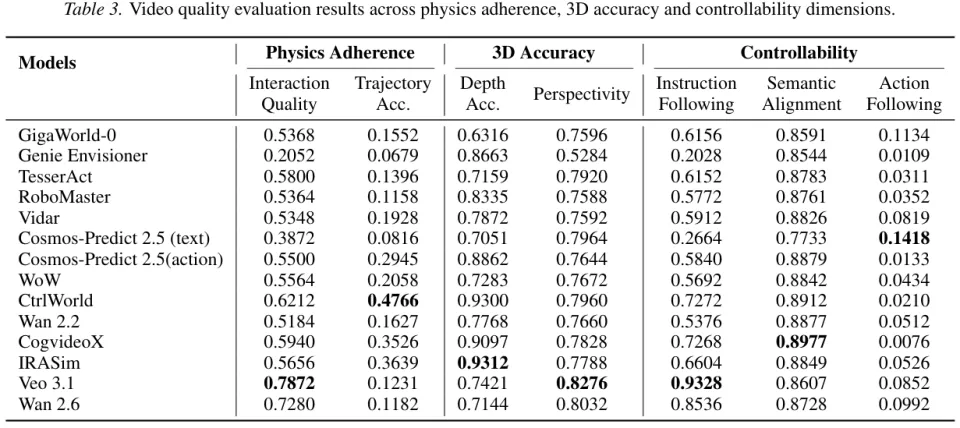
当我们翻开物理依从度和三维准确度这两张表时,华丽外表下的虚弱暴露无遗。
那些视觉能力极强的通用视频模型在长视频生成中频繁出现语义漂移。
机器人手臂会变成面条,或者凭空穿过桌面。反观具身世界模型,虽然画质略显粗糙,但产出的动作序列高度连贯,目标明确,像一个遵守纪律的好工匠。
进入残酷的闭环实机操作环节,真正的差距才彻底浮现。
在充当数据合成引擎的任务中,测试组选择了调整瓶子和按响铃铛这两个动作来考察。
每个动作各执行一百次求平均胜率。使用各种世界模型生成的这二十五条合成轨迹去训练全新的控制策略,成绩让人深思。
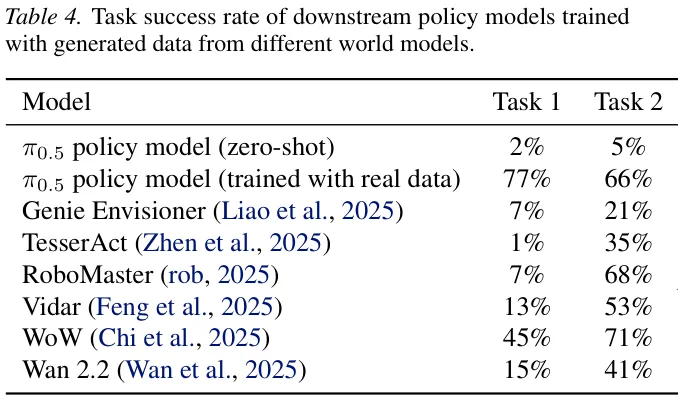
从上表可以看出,绝大多数模型合成的数据确实能带来一点成绩提升,但整体表现依然远远落后于使用真实物理数据训练的结果。
只有 RoboMaster 和 WoW 这两个模型在任务二上产生了超越真实数据的训练效果。
这无情地戳破了高画质等于高价值的错觉。合成画面的视觉保真度再高,如果底层逻辑跑偏了,对于下游的策略学习不仅没有帮助,甚至可能会成为干扰噪音。
充当策略评估官环节更是验证了谁才是真正的环境模拟大师。
在这个测试里,模型需要观察算法的控制指令,生成出相应的环境变化视频。评估结果画成了两张散点图。

CtrlWorld 生成的评估结果与物理模拟器给出的真实结果呈现出极高的相关性。这表明它完美地领悟了环境动态变化的精髓,是一个称职的考官。
Cosmos-Predict 2.5 则表现出微弱的相关性,彻底暴露了它在精准模拟复杂物理碰撞时的无力感。
有些模型甚至会对成功的运动轨迹产生过度拟合,无论你怎么瞎操作,它都倾向于生成成功的画面,丧失了客观评判的能力。
最后是被寄予厚望的终极任务:世界模型直接充当大脑指挥行动。在这个环节,模型被要求进行端到端的预测和输出。

表五的成绩惨不忍睹。虽然好几款模型勉强完成了任务,拿到了一点分数,但和专属的 VLA (视觉-语言-动作) 控制策略相比,它们的成功率依然低得可怜。
现阶段的具身世界模型虽然掌握了一些预测未来的皮毛,但在支持闭环的、长周期的真实动作执行时,依旧会手忙脚乱,极不稳定。
让它们完全接管自动驾驶或者复杂的机器人操作,还有极其漫长的一段路要走。
人类视角的审视则给出了更为立体的结论。
大家在感官上依然偏爱 Veo 3.1 这种商业视频模型生成的精美画面。
在具身模型的内战中,加入了具体动作指令作为条件约束的 CtrlWorld 明显比只给文本提示的 Genie Envisioner 拿到了更多的人类好评。
显式的动作建模像给无序的画面加上了一根清晰的骨骼,能大幅度提升互动的合理性和人类观感。
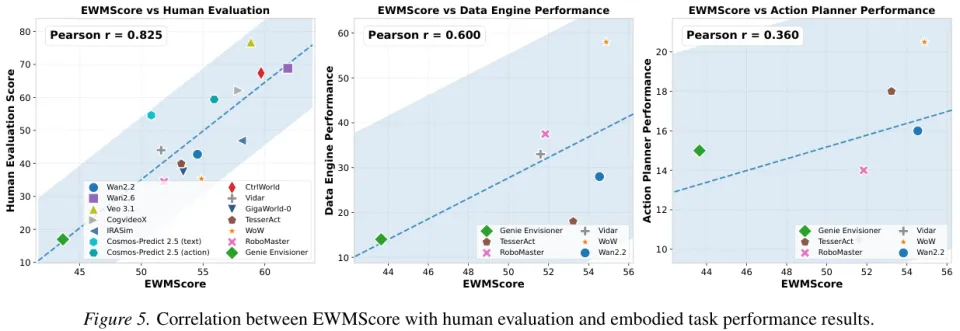
研究人员把辛苦算出来的 EWMScore 和其他几项成绩做了交叉分析,结果充满戏剧性。
EWMScore 和人类主观评价的相关系数高达 0.825,说明这个指标非常懂人类的审美和判断。
它和数据合成任务的相关系数只有 0.600,和终极的动作执行能力的相关系数更是暴跌到了 0.360。
画质好仅仅是拿高分的敲门砖,完全无法等比例转化为具身智能的真实战斗力。
我们目前的模型生成的数据,即使看起来和真拍出来的视频一样完美,它里面蕴含的能指导物理决策的关键信息依然严重不足。
让世界模型从好莱坞特效师彻底转型为硬核的车间工程师,将是整个行业下一步必须跨越的险峰。
参考资料:
https://arxiv.org/pdf/2602.08971
https://world-arena.ai/
https://github.com/tsinghua-fib-lab/WorldArena