让大模型上车:理想汽车硬件协同设计算出最佳边缘模型
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
把大模型装进汽车与机器人,面对低延迟与高精度不可兼得的大难题。
长三角洲AI实验室、中科院、理想汽车等找到了大语言模型硬件协同设计的寻优之路。

在与主流硬件完全相同的延迟条件下,让端侧模型的困惑度一口气降低了19.42%,同时把原本需要几个月的模型架构挑选时间压缩到了短短几天。
研究揭示了一项专为边缘设备打造的大型语言模型硬件协同设计缩放定律。
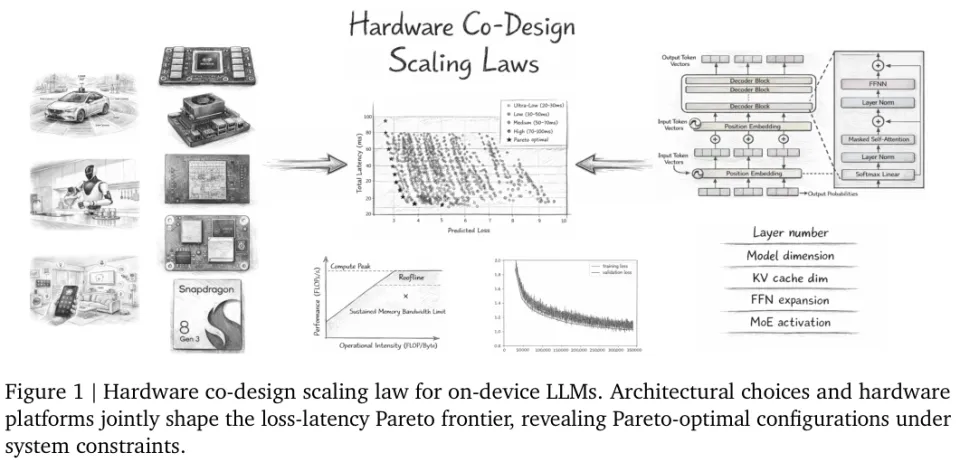
通过将训练损失预测与硬件基准延迟模型相结合,科研人员找到了一条能够完美平衡模型智能水平与设备运行速度的科学路径。
边缘计算需要量身定制的语言模型架构
如今的大型语言模型逐渐成为自动驾驶汽车和移动机器人等具身智能系统的核心大脑。
它们在视觉语言动作模型(VLA)框架中担任着高级规划师的角色。
端侧设备往往面临着极其严苛的内存、带宽、功耗和延迟限制。
这些物理层面的硬性约束彻底重塑了人工智能模型的搭建规则。
习惯了在云端算力中心呼风唤雨的模型架构,一旦下放到边缘设备上就会水土不服。
拥有极高准确率的庞然大物往往会严重超时,而为了速度牺牲参数的迷你模型又会变得过于愚笨。
人们迫切需要一种硬件与软件协同设计的方案,让模型的每一个神经元都能完美契合底层芯片的脾气。
大型语言模型推理效率低下的核心矛盾,源于计算器与内存之间不协调的供需关系。
注意力机制极度依赖数据搬运,前馈神经网络(FFN)则拼命消耗计算力,而键值缓存(KV-cache)又在无情挤占极其有限的片上内存。
由于算术强度、数据局部性和工作负载模式的复杂交织,人工智能芯片的理论最高算力在实际运行中极少能被完全跑满。
为了理解这种性能瓶颈,研究人员常常引入硬件屋顶线模型(Roofline Model)进行分析。
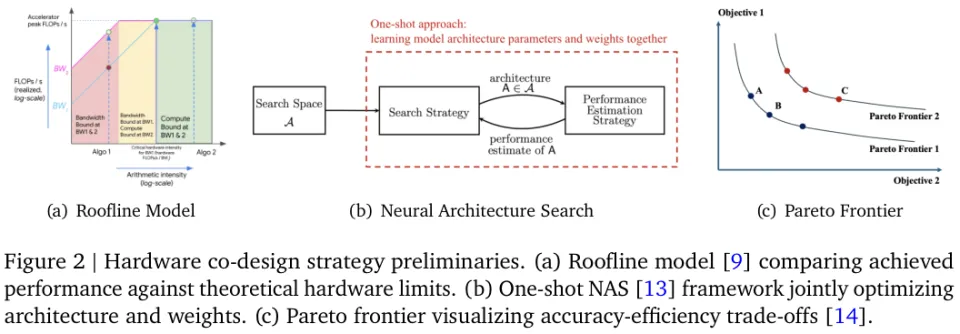
正如图(a) Roofline Model 所示,模型的运行状态被无形中划分为计算受限区和带宽受限区。
增加模型深度会带来计算量和内存读取的线性同步增长。无脑增加模型宽度却会引发参数体积和内存读写量的指数级飙升。
在边缘设备经常面对的单样本(Batch-1)推理场景下,参数在不同Token之间几乎没有重复利用的空间。
由于片上缓存根本装不下海量参数,芯片绝大部分时间都在干等着外部内存慢吞吞地输送数据。
这种糟糕的算力利用率,迫使设计者必须放弃传统的参数盲目扩张,转而寻求一种深度硬件感知的架构设计方法。
传统的神经架构搜索(NAS)过去只盯着验证损失或准确率等单一指标发力。
这种单线程思维在资源无限的云端或许行得通,但在资源捉襟见肘的端侧平台绝对是一场灾难。
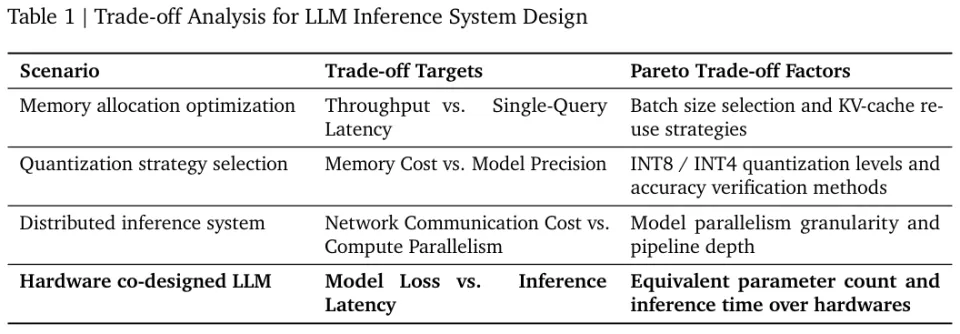
正如表1所展示的,推理系统设计处处充满了必须做出取舍的十字路口。
面对模型精度与推理延迟之间不可调和的矛盾,帕累托优化(Pareto Optimization)成为了一把破局的利器。
不再去寻找一个虚无缥缈的绝对最优解,而是去寻找一条由许多不被相互彻底碾压的优秀架构组成的性能边界线。
系统设计师拿着具体的硬件预算指标,就能在这条边界线上直接挑选出最合适的那个完美架构。
精确计算精度与延迟的最优解
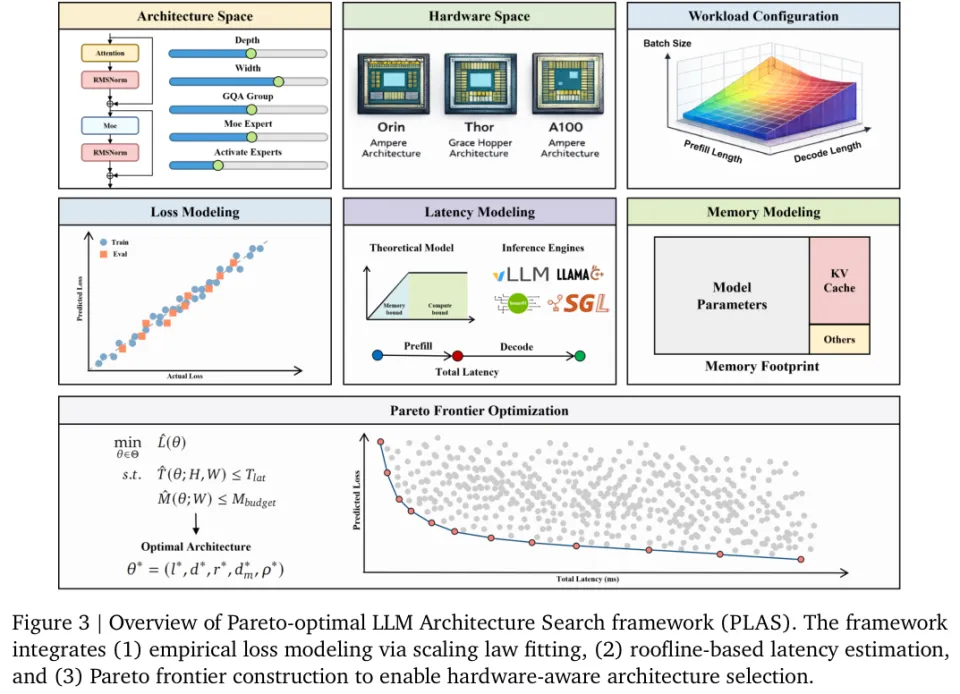
这套专为端侧大型语言模型打造的硬件感知建模框架,同时捕捉了模型的聪明程度与运行速度。
用一组数学公式将训练损失与架构参数紧紧绑定在一起,同时利用屋顶线分析来精准预判推理延迟。框架在英伟达Jetson Orin平台上经历了数千种候选架构的残酷摸底测试。
为了避免面对犹如天文数字般的超参数组合进行穷举搜索,科研人员利用多项式近似拟合出了一条经验缩放定律。
通过观察大量实际训练过程中的数据表现,验证损失被成功量化为一个清晰的数学方程式。
层数、宽度、键值缓存维度以及专家激活率等参数,都在公式中找到了属于自己的准确位置。
具体而言,精心挑选170种覆盖了密集模型和混合专家系统(MoE)的架构。所有模型都按照每天喂入100亿个Token的数据量进行了极其严格的基础训练。
训练数据包含了通用语料、数学推理和代码片段,使用标准一致的优化器与学习率衰减策略以保证绝对公平。
随后的拟合结果令人十分振奋。
图4清晰地记录了这条缩放定律极高的预测水准。
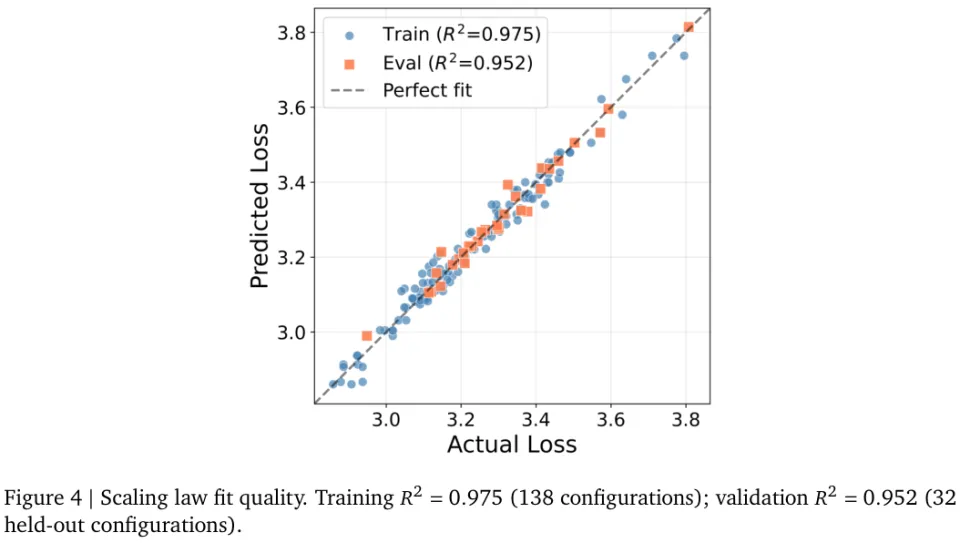
训练集拟合优度达到了0.975,而在未参与训练的验证集上也跑出了0.952的优异成绩。高度非凸且充满参数耦合干扰的损失预测难题,被这套结构化的探索方案成功拆解。
处理完模型精度,下一步就是精准掌控推理延迟。
框架依据硬件的算力峰值和内存带宽上限,将模型里的每一个数学运算都精准归类为算力瓶颈或是带宽瓶颈。
依靠这种纯解析层面的计算,系统能在20分钟内一口气评估五万多种不同的模型配置。
端侧模型的运行通常分为两个截然不同的阶段。
预填充(Prefill)阶段负责阅读输入的长串指令,此时注意力机制的计算量急剧增加,芯片大多处于算力满载的火热状态。
解码(Decode)阶段负责一个词一个词地往外蹦答案,此时每次生成都需要将庞大的模型权重从内存里搬运一遍,芯片往往在焦急等待数据传输。
不同应用场景对这两个阶段的延迟容忍度完全不同。
这种复杂多变的现实需求,进一步催生了这套整合了经验损失与屋顶线延迟的帕累托架构搜索框架(PLAS)。
图3完整展示了这套将学术理论直接转化为生产力工具的宏大系统全貌。
宽浅网络与稀疏架构主导最佳性能边界
将数以万计的模型预测数据投射到一张二维图表上。位于图表最左下角的那道完美弧线,就是兼顾了极低误差与极快速度的帕累托前沿。
系统采用拉丁超立方抽样技术铺开初始搜索网,接着在稀疏区域和边界附近反复钻探,直到这道性能边界线再也无法向左下方推进一步。
图5直观对比了半精度浮点(FP16)与八位整数(INT8)两种精度在不同优化目标下的性能边界线。

INT8量化技术毫无悬念地将整条边界线推向了耗时更短的优秀区域。受制于层归一化和激活函数等非线性计算带来的转换损耗,量化带来的速度提升并没有达到理论上的两倍之多。
这些计算出来的边界线就是一本详尽的端侧大模型选购指南。
工程师只需对比表2列出的典型应用延迟需求,就能按图索骥找到最佳选择。
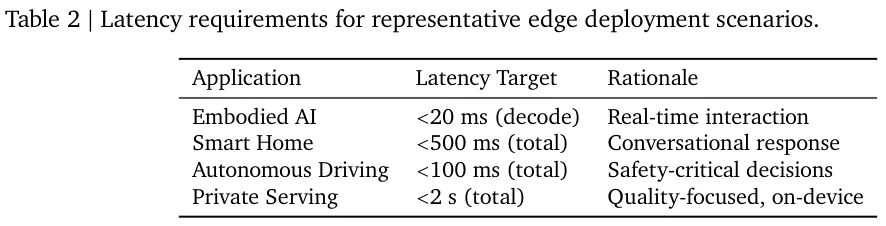
需要实时互动的具身智能必须死守20毫秒的解码底线,而看重对话质量的智能家居则可以放宽到500毫秒的整体响应区间。
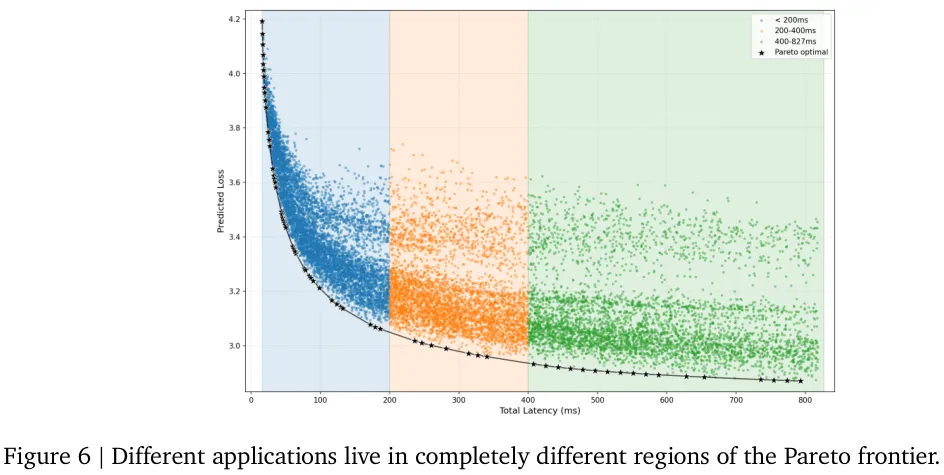
图6极为生动地揭示了真实工业界的多样化诉求。不同的实际应用场景在这条帕累托边界上瓜分了完全不同的驻留地盘。
沿着这条帕累托前沿线慢慢行走,最佳模型架构的参数发生着极其规律的演变。
图7详细记录了随延迟预算逐渐充裕时,层数、宽度、专家数量以及前馈网络扩张率的动态变化过程。混合专家系统(MoE)以碾压的姿态霸占了所有榜单,证明了稀疏架构在端侧单样本推理场景下的绝对统治力。
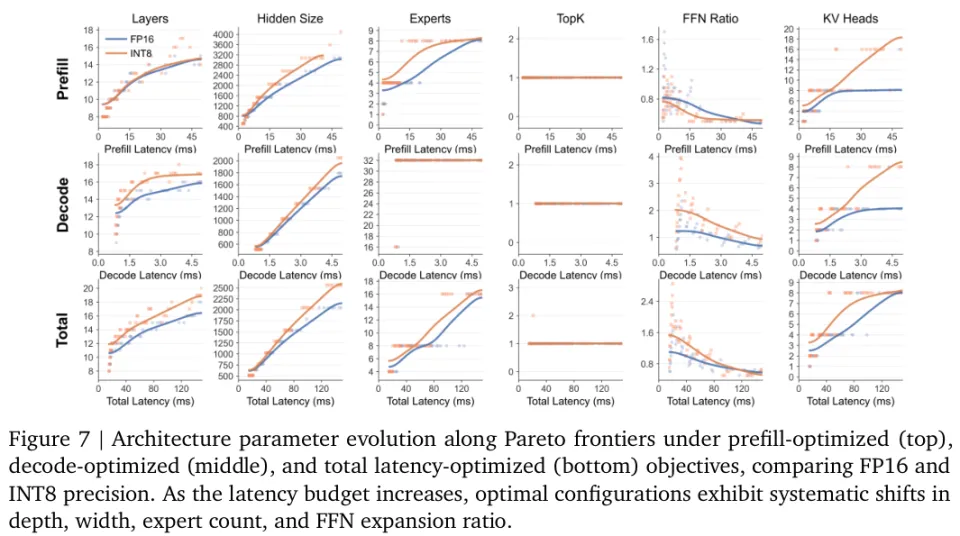
与云端大模型偏爱深不可测的狭长网络不同,端侧的最优解呈现出极为显著的宽浅特征。
在严苛的延迟红线前,横向增加模型宽度的投资回报率远远跑赢了纵向叠加层数。
只有当宽度触及设计空间的极限天花板后,多余的算力预算才会被拿去增加网络深度。
专家模型的参数分配在预填充与解码两个阶段呈现出巨大的割裂。预填充阶段算力吃紧,激活太多专家会疯狂占用内存带宽,因此最优解倾向于维持较少的专家总数。
解码阶段被内存搬运死死卡住,多准备几个不激活的专家当作知识库几乎不增加任何计算负担,因此最优解会疯狂拉满专家总数。
两者在选拔策略上殊途同归,全部毫不犹豫地选择了只激活一个专家的最高效路由机制。
这些在极端环境下脱颖而出的精英架构,彻底颠覆了教科书里的经验法则。
经典的Transformer模型总是死板地使用4倍的前馈网络(FFN)扩张率。
端侧环境下的帕累托最优架构经常采用低于1倍的超小扩张率,把抠出来的参数全部补贴给了模型宽度或是专家总数。
图8记录了一次震撼人心的降维打击。
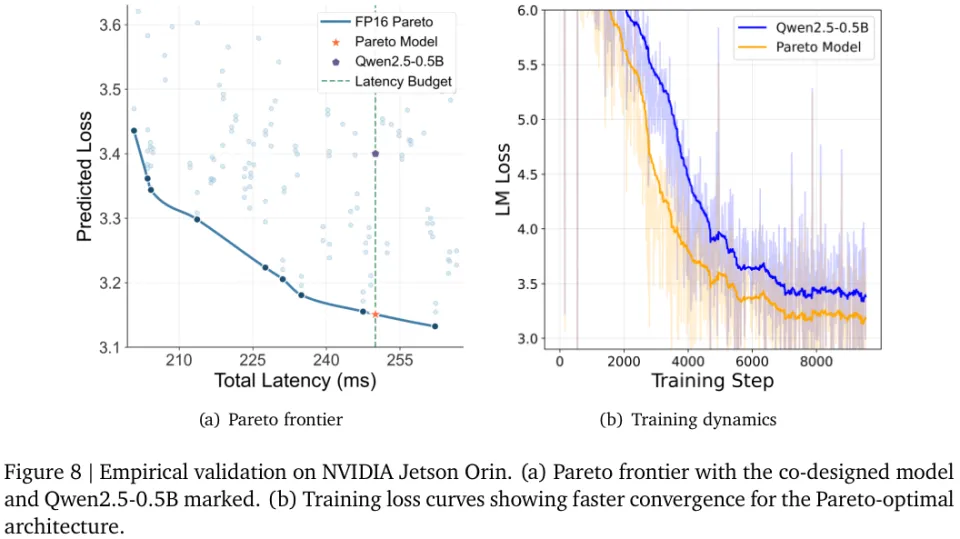
找到一个与著名开源模型Qwen2.5-0.5B运行延迟完全一致的协同设计架构。
在相同数据和优化策略的洗礼下,新架构不仅在训练全程将对手死死压制,更在维基百科测试集上砍下了低至50.88的困惑度。这比开源标杆足足优秀了19.42%。
约束条件决定模型架构的物理法则
通过一千多个模型的暴力搜索的确管用,但掌握事物背后的底层数学规律才能真正举一反三。
硬件系统对模型的约束犹如无形的物理法则,分为算力受限的预填充限制、带宽受限的解码限制,以及存储器容量受限的内存限制。
其中激活率(激活专家的比例)极其特殊,它只影响硬盘占用的死空间,丝毫不增加单次Token运算的活负担。
在纯粹的延迟受限场景下,既然稀疏架构能在不增加算力负担的前提下变相增加知识储备,最优策略就是疯狂压低激活率,挑战极限的稀疏度。这也解释了自动驾驶类模型为何总是青睐顶配总数外加单点路由的极端专家配置。
当系统受限于内存容量时,模型的宽度和专家稀疏度存在着精妙的绑定关系,越宽的模型越需要更加稀疏的专家配置来平衡容量收益与存储成本。
在4至8GB的微型设备上,一个参数量20亿的宽模型应该只激活极小比例的专家,而一个5亿参数的小模型则有资本使用更密集的激活策略。
最为凶险的双重受限系统,根据预填充与解码谁占据主导地位,分别给出了包含特定硬件比例系数的精准代数解与二次方程解。

系统设计者只需要测算出设备的算力与内存比例,直接套用定理公式就能得到最完美的专家激活率配置。
网络深度的最优解总是被死死钉在硬件约束的极限数值上。
由于深度与宽度的平方成反比,预算固定时只能采取先保宽度再定深度的策略。如果算出的最佳深度超过了搜索空间的上限,只能委屈求全退而求其次,一点点削减模型宽度直到深度落入合法区间。

表4揭示了一个极其有趣的硬件物理特性。由于每一次乘加运算算作两次浮点计算,却只需要从内存搬运一次权重数据,预填充与解码场景在公式推导中产生了恰好两倍的系数差异。
这种底层算术特征导致长文本阅读模型理应选用更小的前馈比例与更多的分组查询注意力(GQA)磁头,而聊天机器狗则必须用更大的前馈比例来死守键值缓存的带宽底线。
有了这套严密的理论框架,未来任何全新的人工智能芯片面世,工程师都只需用探针测出算力、带宽和内存三个物理常量。
把这三个数字塞进本文推导的方程式中,就能立刻计算出专属于该芯片的完美模型三维尺寸。
只需再花几天时间用几十亿个Token进行微调验证,一款地表最强的端侧定制大语言模型便宣告诞生。
参考资料:
https://arxiv.org/pdf/2602.10377