GPT-5.4:OpenAI做了个Kimi K2.5+MiniMax M2.5?

编辑:王兆洋
为了更好的追赶Claude,OpenAI带来了能力“N合1”的统一模型GPT-5.4,而看完这个模型的各种介绍和能力展示,你会发现它满满都是Kimi K2.5 和MiniMax M2.5这两个在agent上卷到疯的开源模型的影子。
1
融合了多种agent能力的all in one模型
3 月 5 日,OpenAI 正式发布 GPT-5.4。和过去那种“模型更强一点”的更新不同,这次发布的重点非常明确:把 AI 从聊天助手,进一步推向真正能交付专业工作的系统。 官方同步把 GPT-5.4 上线到了 ChatGPT、API 和 Codex,还推出了 GPT-5.4 Pro,以及面向金融和表格工作流的 ChatGPT for Excel 和多家金融数据集成。

这次发布的几个核心信息:
GPT-5.4 官方定位是“面向专业工作的最强、最高效 frontier model”。它整合了 reasoning、coding 和 agentic workflow 的能力,重点强化了表格、文档、演示文稿这类专业任务。
GPT-5.4 Pro也同步推出。这是更高性能版本,面向最复杂、最长链路的任务,在 ChatGPT 和 API 中都可用。
此外,ChatGPT 里还上线了 GPT-5.4 Thinking。它支持在思考开始前给出简短计划,用户还能在它思考过程中继续补充指令,实时修正方向。
在API 和 Codex 侧,补齐了 agent 能力。GPT-5.4 是 OpenAI 首个具备原生、SOTA 级 computer use 能力的通用模型,同时支持最高 1,050,000 token 上下文窗口。
而且OpenAI 同时发布了 ChatGPT for Excel 和金融数据集成。前者能直接在 Excel 工作簿里调用 ChatGPT 做建模、更新模型、跑情景分析;后者把 FactSet、Dow Jones Factiva、LSEG、Daloopa、S&P Global 等数据接入 ChatGPT。
这里面呈现出OpenAI在模型研发思路上的明显变化:
定位彻底变了,不再主打“聊天”,而是主打“专业工作”
OpenAI 在官方博客里写得很直接:GPT-5.4 是“for professional work”。它的优化方向,不是泛泛地变聪明,而是围绕真实职业场景里的复杂产出:表格、文档、PPT、跨工具任务、长流程执行。
这意味着 GPT-5.4 的目标用户已经很明确了:不是单纯问答的普通用户,而是分析师、研究员、法务、开发者、金融从业者,以及需要复杂知识工作的团队。这个定位变化,其实比性能数字更重要。
知识工作能力明显增强,尤其是表格、文档、PPT
官方把这块作为重点展示。
在 GDPval 这个测试 44 种职业真实工作产出的 benchmark 上,GPT-5.4 的成绩是 83.0% wins or ties,相比 GPT-5.2 的 70.9% 提升明显。这个 benchmark 测的不是考试题,而是销售演示、会计表格、排班表、制造流程图、短视频等“能不能交付工作成果”。
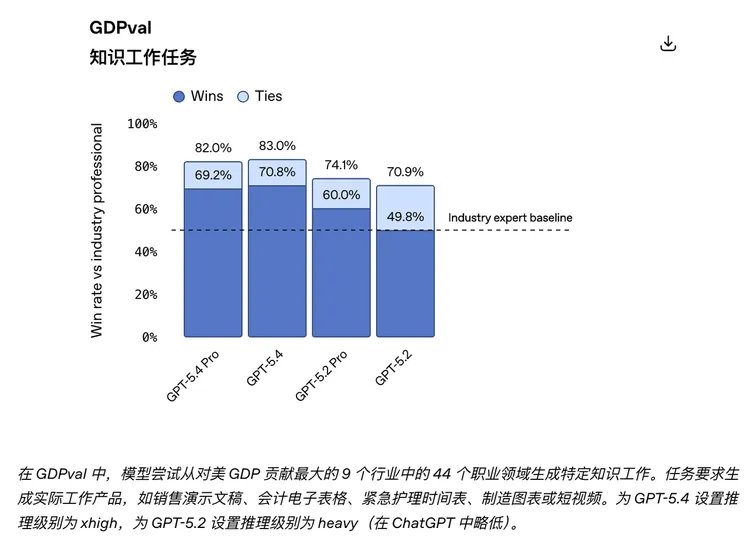
OpenAI 还单独强调了表格建模和演示文稿能力。在一组接近投行初级分析师日常工作的 spreadsheet modeling 任务里,GPT-5.4 平均分是 87.3%,而 GPT-5.2 是 68.4%;在 presentation 评测中,人类评审有 68.0% 的情况下更偏好 GPT-5.4 的输出。
这说明它不是“更会写一段总结”,而是更接近真正能产出可用工作成品的模型。
强调它的幻觉更少,事实性更强
这是很实用、也最容易被忽视的一项升级。
OpenAI 表示,在一组用户曾标记“存在事实错误”的匿名提示集合上,GPT-5.4 的单条 claim 出错概率比 GPT-5.2 低 33%,整段回答含错误的概率低 18%。官方直接称 GPT-5.4 是他们“most factual model yet”。
这件事的重要性其实不比 benchmark 低。因为进入研究、法律、财务、企业报告这些场景之后,用户最在乎的不是模型多会炫技,而是它少说错话、少编事实。GPT-5.4 这次明显是在往“可用”和“可信”上走。
原生 computer use,GPT-5.4 开始更像真正的 agent
这次发布会,最值得行业关注的其实是这部分。
OpenAI 明确表示,GPT-5.4 是他们首个具备原生 computer-use 能力的通用模型。它不仅能理解截图,还能执行鼠标和键盘操作,在网页和软件环境中完成复杂流程。
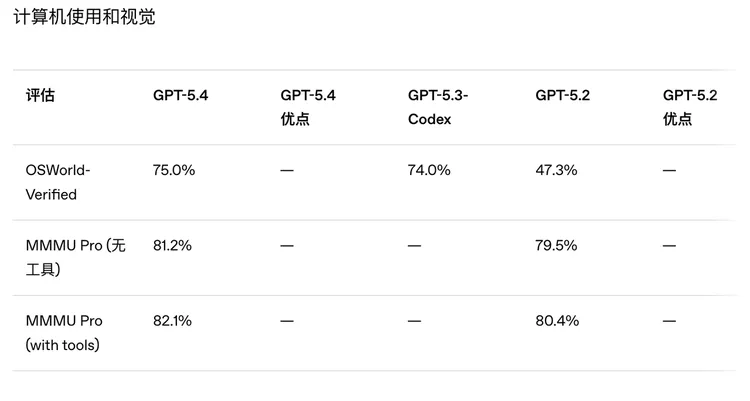
在 OSWorld-Verified 上,GPT-5.4 成绩达到 75.0%,远高于 GPT-5.2 的 47.3%,甚至超过官方列出的人类水平 72.4%。在 WebArena-Verified 和 Online-Mind2Web 这类浏览器任务上,它的表现也继续领先。
这意味着 GPT-5.4 不只是“知道怎么做”,而是已经越来越接近“可以自己去做”。对开发者来说,这比单纯更强的文本生成重要得多。
工具调用上下功夫,用tool search 来降本很关键
如果说 computer use 决定了 agent 能不能“动起来”,那 tool search 决定了它在复杂工具生态里会不会“越用越笨”。
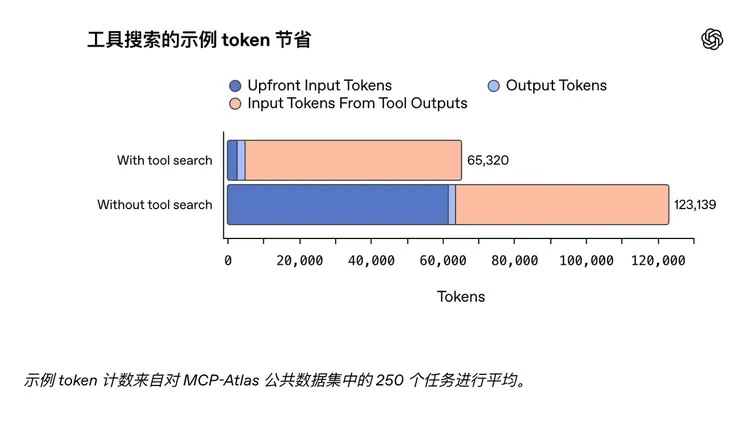
GPT-5.4 引入了 tool search。简单说,就是模型不需要一开始就把几十个工具说明都塞进上下文里,而是先看到轻量级工具列表,必要时再查具体定义。官方实验显示,在 Scale 的 MCP Atlas benchmark 上,把 36 个 MCP servers 放进 tool search 后,总 token 使用量下降 47%,同时精度不变。
这看起来很技术,但对 agent 落地非常关键。因为真实企业场景里的问题,从来不是“有没有一个工具”,而是“工具一多之后,模型还好不好用”。GPT-5.4 这次是在补基础设施。
改进ChatGPT 体验,更像“协作推理”,而不是黑箱等待
在 ChatGPT 里,GPT-5.4 Thinking 的体验也有明显变化。
官方帮助文档显示,当用户选择 GPT-5.4 Thinking 或 GPT-5.4 Pro 时,模型可能会先给出一个简短 preamble,说明它打算怎么做;用户还可以在它思考过程中继续加要求,修正方向。与此同时,ChatGPT 里还新增了 thinking-time toggle,Plus 和 Business 用户可选 Standard、Extended,Pro 用户可再选 Light、Heavy。
这看起来像小功能,但其实很重要。过去很多 thinking 模型虽然强,但体验像一个黑箱:你丢进去一个问题,等它想完再看结果。GPT-5.4 想解决的是“用户能不能在中途介入、协作、修正”。这对复杂研究、写作和规划类任务非常有价值。
1
“致敬”Kimi和MiniMax
看完这些能力介绍,对近期各家模型厂的模型使用和跟踪紧密的人会立刻意识到,这些点像极了Kimi和MiniMax一直在卷的重点。
这是OpenAI自己首个Computer Use模型,它的技术思路更像是用多模态和视觉的能力来完成操控任务。这很容易让人想到已经在Kimi系列模型里存在许久的内置在模型里的Computer use能力,而且在Kimi K2.5里,一个重点正是基于视觉,包括图片和视频,进行理解和推理,并且也是主打一个all in one架构,多模态和文本、思考和快速回答、代码和agent能力都统一于一个模型一身。
GPT-5.4强调的Office套件能力,也是K 2.5当时重点展示的融入模型本身的能力。展示的案例也都差不多。
而此次在Agent的调用上做的设计,比如对Tool Use引入搜索的思路,和MiniMax M2.5在训练时提出的诸如Forge等方法有相同的思路,就是探索对Agent部分和模型本身基础能力做解耦。
把Agent和它需要的环境抽象出来,与模型本身区分开,GPT-5.4给模型本身就原生配上了对各种tool的理解能力,而不是混在一起只是按指令调用。
而M 2.5也是直接把agent需要的对tool和对不同框架的理解训练进模型层面。都相当于在模型内部去增加中间层,进而给Scale的方向提供新可能。
“把编程、Computer use、工具调用等各种agent的能力原生揉进一个统一的底座模型里,并且按这个方向不停往模型里增加新的像是文档和office这种非常具体的agent能力”,这一直是Kimi和MiniMax的模型方向,这样的路线和能力在过去似乎并不被OpenAI重视,GPT模型和agent分的比较开,但现在它也算致敬这两个开源模型,改了思路。
这背后很重要的一个变量自然就是OpenClaw:这个已经疯狂破圈吸引各种用户用它“燃烧”token的产品,需要的正是Kimi和MiniMax这种模型。在从一众对手手上抢夺“招安”了OpenClaw后,此次的GPT 5.4也有明显要抢更多OpenClaw用户的模型生意的意味。
1
更多具体案例
1)金融分析:直接进 Excel,开始接手表格工作流
OpenAI 这次专门同步发布了 ChatGPT for Excel。官方定义很明确:这是一个还在 beta 阶段的 Excel 插件,可以把 ChatGPT 直接带进工作簿里,帮助用户构建和更新模型、运行情景分析、根据单元格和公式生成输出。它由 GPT-5.4 驱动。
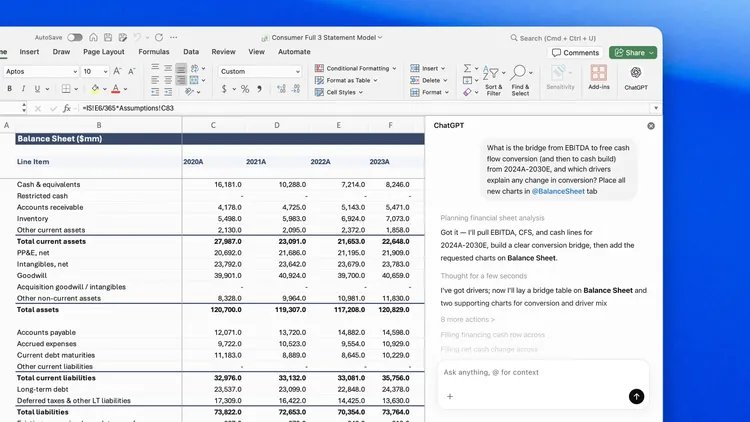
这意味着 GPT-5.4 不再只是“给你讲怎么做 Excel”,而是开始直接进入 Excel 工作流本身。对于金融分析、投研、企业 FP&A、咨询等岗位,这个方向非常清晰:OpenAI 不只是想做聊天机器人,而是要切进日常生产工具。
同时,OpenAI 还把 FactSet、Dow Jones Factiva、LSEG、Daloopa、S&P Global 等金融数据源接入了 ChatGPT,让用户在一个工作流里完成数据获取、分析和输出。
2)法律工作:长合同、复杂交易分析更稳
OpenAI 在官方博客里引用了 Harvey 的反馈。Harvey 表示,GPT-5.4 在其 BigLaw Bench 上拿到 91%,并且在复杂交易分析、长合同中的准确性保持、以及法律从业者要求的细节密度上,表现优于其他模型。
这说明 GPT-5.4 的提升,不只是写作更顺,而是开始进入对“结构、严谨性、细节一致性”要求更高的文档密集型工作。
3)网页和软件操作:可以自己点、自己做、自己验证
在 computer use 场景里,OpenAI 展示了 GPT-5.4 根据浏览器截图进行界面理解,并通过坐标点击来发送邮件和安排日历事件的能力。
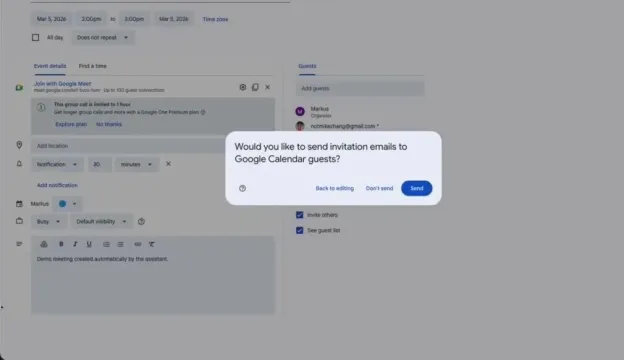
官方还引用了 Mainstay 的测试结果:在大约 3 万个 HOA 和 property tax portals 的 computer-use 评测中,GPT-5.4 首次尝试成功率达到 95%,三次尝试内达到 100%,同时速度约快 3 倍,token 使用量减少约 70%。
这个案例很能说明 GPT-5.4 的方向:不是回答“怎么填表”,而是直接去填表。
4)编码和前端:不只是会写代码,还更会完成完整产品
在 coding 部分,OpenAI 说 GPT-5.4 继承了 GPT-5.3-Codex 的强编码能力,同时在长时程任务里更好,因为它可以调用工具、迭代执行、自己把工作往前推。它在 SWE-Bench Pro(Public)上达到 57.7%,略高于 GPT-5.3-Codex 的 56.8%。
更有意思的是,OpenAI 强调 GPT-5.4 在复杂前端任务上表现明显更好,产出的结果既更美观,也更可用。官方还演示了它结合 Playwright Interactive 一边构建网页/应用,一边自己进行可视化调试和测试。
这意味着 GPT-5.4 的“编码能力”已经不只是代码补全,而更接近完整的软件生产链路。

官方案例:使用 GPT-5.4 根据一个略微指定的提示制作的主题公园模拟游戏,通过 Playwright Interactive 进行浏览器测试和图像生成来构建等距资产集。该模拟游戏包括基于瓦片的路径放置、游乐设施和景观建设、游客路径规划、排队和游乐设施循环,而公园指标如金钱、游客数量、幸福度、清洁度和评分会根据布局表现和游客的反应而上升或下降。Playwright 被用于自动化浏览器测试,通过建设和扩展公园、放置和移除路径和游乐设施、检查摄像机导航,并验证在多轮测试中游客、排队、游乐设施状态和 UI 指标是否正确更新。
1
价格和使用方式
API 文档显示,GPT-5.4 支持文本和图像输入、文本输出,拥有 1,050,000 token context window 和 128,000 max output tokens。价格为每百万输入 token 2.50 美元、输出 15.00 美元。

而 GPT-5.4 Pro 在 ChatGPT 侧只向 Pro、Business、Enterprise 和 Edu 计划开放。帮助文档也写得很明白,Pro 是“the highest-capability GPT-5.4 option in ChatGPT for the hardest tasks and long-running workflows”。
这些价格还是挺贵的。
在模型上,OpenAI开始借鉴开源模型们的方法,而在价格上,OpenAI还是OpenAI。