震惊海外开发者!BOSS直聘3B小模型比肩80B,怎么做到的?
BOSS直聘楠北阁大模型团队,发布了3B轻量端侧小模型Nanbeige4.1-3B。

性能表现震惊了不少海外开发者,引得社区疯狂部署尝试。
模型一度登上了Hugging Face文本类模型趋势榜首。
Nanbeige4.1-3B仅仅使用30亿个参数的轻量级大脑,惊人地完成了高达600轮的超长周期网络搜索与复杂工具调用。
研究团队改进了推理和偏好对齐,结合逐点和成对的奖励建模,确保了高质量的、与人类一致的响应。
对于代码生成,在强化学习中设计了复杂性感知奖励,优化了正确性和效率。
在深度搜索中,执行复杂的数据合成,并在训练过程中纳入回合级别的监督。
Nanbeie4-1-3B明显优于类似规模的先前模型,甚至比肩更大的模型(如Qwen3-Next -80B-A3B)。
小型模型也可以同时实现广泛的能力和强大的专业化,Nanbeie4-1-3B重新定义了3B参数模型的潜力。
30亿参数挑战通用全能
研发团队以先前的基础版本Nanbeige4-3B-Thinking为起点,全面重构了监督微调 (SFT) 的数据分布。
大量的代码素材被补充进资料库,数学和通用领域的难题比例也得到了大幅度扩充。
研究人员将模型的上下文处理窗口从64000个Token一口气拉升到了256000个Token。
在最核心的超长文本训练阶段,精妙的数据配方起到了决定性作用。这其中包括27%的代码、26%的深度搜索、23%的理工科知识、13%的工具使用以及10%的通用领域内容。
团队针对思维链 (CoT) 进行了深度的重建优化。通过增加答案修正循环的迭代次数,模型学会了在自我批判中提炼最纯粹的解题思路。
表格1详细记录了基础微调带来的实力飞跃,模型在代码、数学和人类意图对齐测试中全线提升。

微调后的模型偶尔会犯啰嗦和重复陈述的老毛病。为此,团队引入了逐点强化学习 (Point-wise RL) 来规范模型的发言习惯。系统利用一套基于人类偏好训练的裁判机制来给回答打分。
组相对策略优化 (GRPO) 算法会从8个候选答案中挑选出最简洁易懂的那个作为标准示范。经过这番调教,模型在代码测试中因篇幅超长被截断的错误率从5.27%暴降至0.38%。
成对强化学习 (Pair-wise RL) 被用来进行更极致的打磨。系统把高分模型和普通模型的回答摆在一起,采用极其严苛的检查单策略来判定输赢。
为了防止裁判对先看到的答案产生偏见,系统加入了一种叫交换一致性正则化的巧妙设计。哪怕把两个答案的位置互换,打分结果也必须保持绝对公正。在多轮对话场景中,完整的聊天记录都会被交给裁判进行审视。
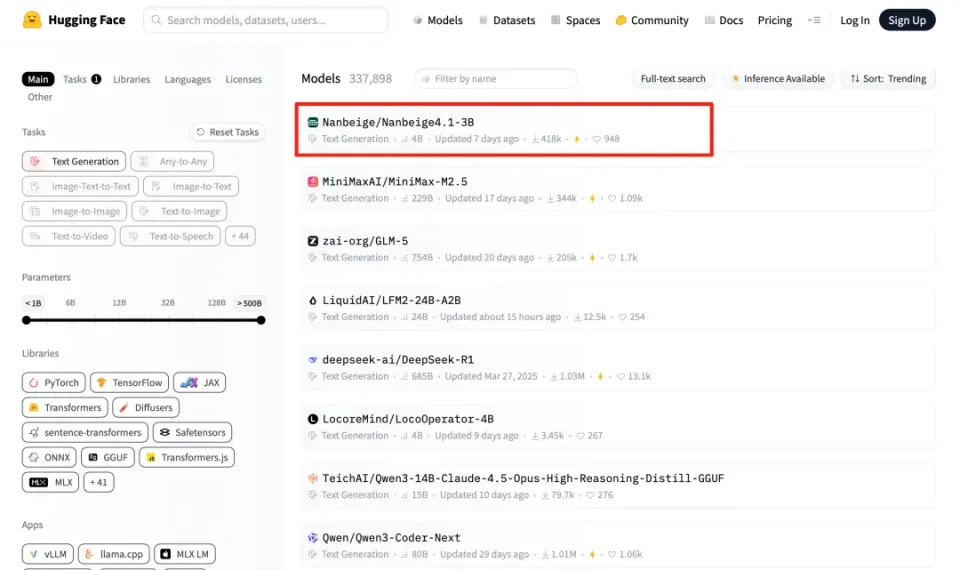
表格2展示了连环强化学习带来的丰厚回报。经历逐点与成对训练的洗礼后,模型在最难的对齐评测中斩获了73.8的高分。
数据迷宫里的深度搜索规划
查阅海量资料是一项极其考验耐心和规划能力的精细活。深度搜索要求模型在庞杂的环境中主动调用工具并进行多步骤的推理连结。
很多同行选手走错几步就会忘记最初的任务目标,该模型却能稳健地执行长达数百步的连贯操作。
这种定力的来源是一套精心搭建的大规模合成数据集。
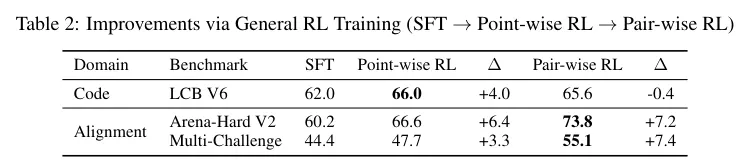
图2完整再现了这条如同工业流水线般的数据生产网络。研发人员利用维基百科编织出一张错综复杂的实体关联图谱。
为了保证考验的时代感,系统专门锁定最近半年内刚刚更新过的词条作为线索源头。
程序像探险家一样在图谱上进行随机游走,串联起极具深度的知识链条。高级大模型接过这些链条,将其转化成一个个足以令人绞尽脑汁的复杂提问。
光有问题还不够,系统需要教导模型如何去寻找答案。多个代理框架受命去互联网上搜寻线索,留下了各种各样的探寻轨迹。这些五花八门的轨迹最终被规范化为统一的工具调用指令序列。
在这个环节,一个极其冷酷的评论家模型充当了质检员的角色。这位考官会在互动的每一个细微回合进行灵魂三问,逻辑推导站得住脚吗,工具使用规范准确吗,获取的信息有实质性帮助吗。
只要任何一环掉链子,这段数据连同背后的努力就会被直接丢弃,或者贴上负面标签作为警示。经过筛选沉淀下来的,全是无与伦比的高保真训练信号。
表格3中印证了合成数据的神奇功效。

在基准测试中,引入合成数据的模型得分如同坐上了火箭。尤其在深层搜索深度05级别上,得分从可怜的33.0一路飙升至76.0。
不仅有模拟搜索引擎 (Serper) 提供广阔的资讯,还有专业的网页信息提取器 (Jina) 抽丝剥茧。安全沙盒环境 (E2B Sandbox) 为所有代码的运行提供了坚不可摧的防护罩。
在不同深度搜索基准上,模型性能实力展现得淋漓尽致。
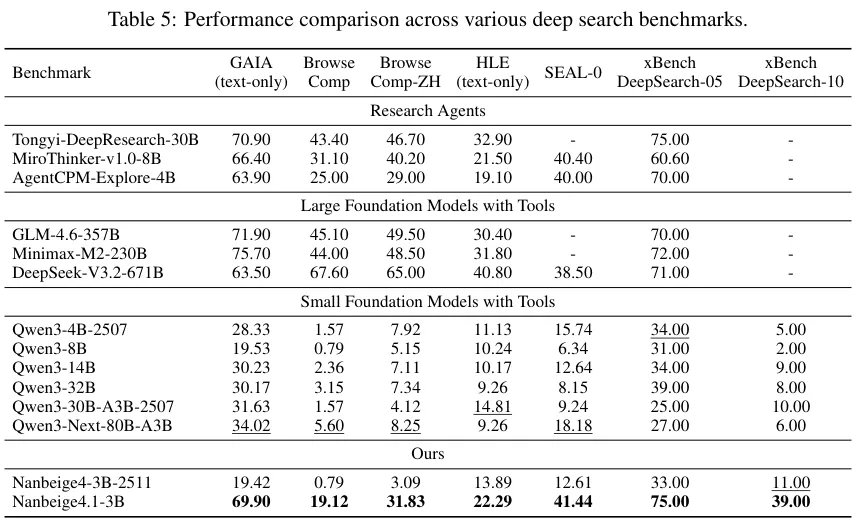
它把同样体型的竞争对手远远抛在脑后,甚至一些基准上,比那些吃下庞大算力资源的巨兽还要强。
代码裁判训练极速算法
研发团队为编程训练定制了一位极其铁面的统一裁判系统。这位裁判不仅会在多语言沙盒里检验代码的对错,还会拿着秒表精确计算算法执行的时间损耗。
为了培养模型对运行速度的执念,数据构建阶段就开启了严酷的末位淘汰。针对同一个编程问题,系统会采样出各种各样的解法,裁判系统登场对它们进行综合审视。唯有那些兼顾功能正确无误且时间复杂度极佳的黄金解法才能存活下来。
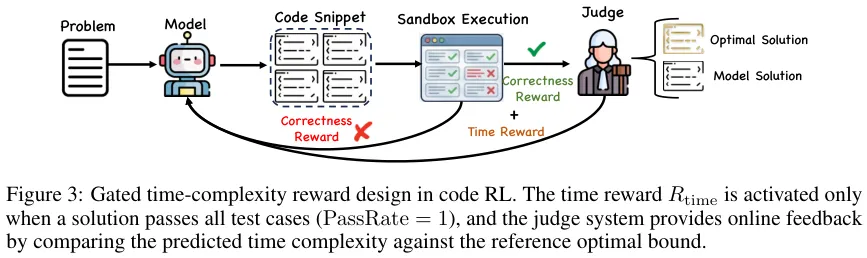
在强化学习数据的准备阶段,系统采用了一种策略上的动态过滤机制。对每一道题目,系统强迫模型生成8次不同的尝试。前期阶段的关注点在于能不能做出来,只要模型能在8次中成功解答1到5次,这道题就会被选为攻坚靶子保留下来。
进入后期阶段,考验的标准瞬间拉高到了算法效率。系统严格清点8次尝试中究竟有几次达到了极速运行的标准。唯有那些能被模型偶尔以最优复杂度解出的题目,才配成为后续拔高训练的精选教材。
在模型没能全部通过功能测试用例之前,裁判绝对不会赐予一星半点的速度奖励分。这就好像建筑工地上必须先确保大楼地基牢靠,之后才允许施工队追求建设速度。
初期的训练像是一场狂奔,模型贪婪地汲取着提高正确率的养分。进入后期的磨练,正确率的增长放缓,被隐藏的时间复杂度奖励大门轰然敞开。裁判系统会在云端实时比对模型解法与人类参考答案的效率差异。
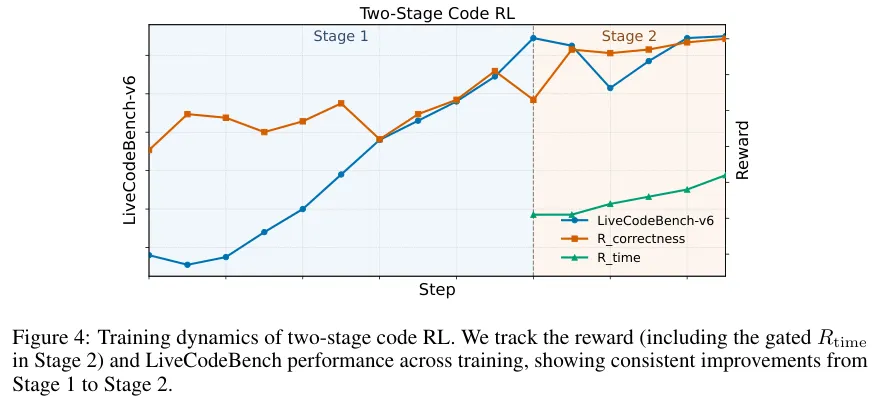
图4的上升曲线真实记录了这场认知升级的历程。模型在正确的框架内疯狂压榨每一毫秒的运算极限。为了检验这种极限打磨的最终成色,团队把模型拉到了真实世界的算法角斗场。
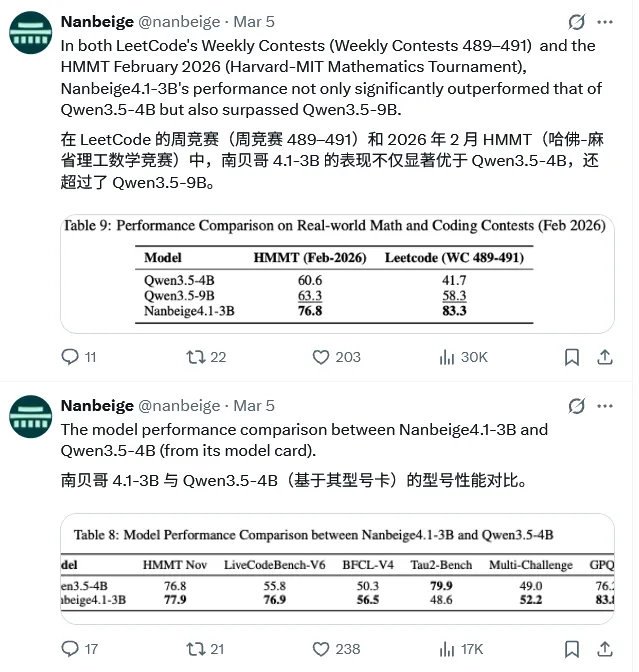
在极度内卷的力扣 (LeetCode) 每周算法挑战赛中,模型干净利落地解出了20道中的17道。

高达85.0%的恐怖通过率让它在虚拟参赛模式下,一举夺得了第487期比赛的榜首。
即便是面对参数量高达300亿的庞然大物,这位小个子依然展现出了碾压级的执行效率。
团队在最新的测试结果中显示,Nanbeige4.1-3B(纯文本)甚至超越了刚刚发布的Qwen3.5-4B(多模态)和Qwen3.5-9B(多模态)。
进入代码专项特训后,两阶段的严酷打磨让它掌握了兼顾准确与速度的编程奥义。最后阶段补充的轻量级代理强化训练,将它彻底升华为熟练驾驭各种工具的数字多面手。
在编程、理科推理和代理调度等各个维度上都有了很大提升。
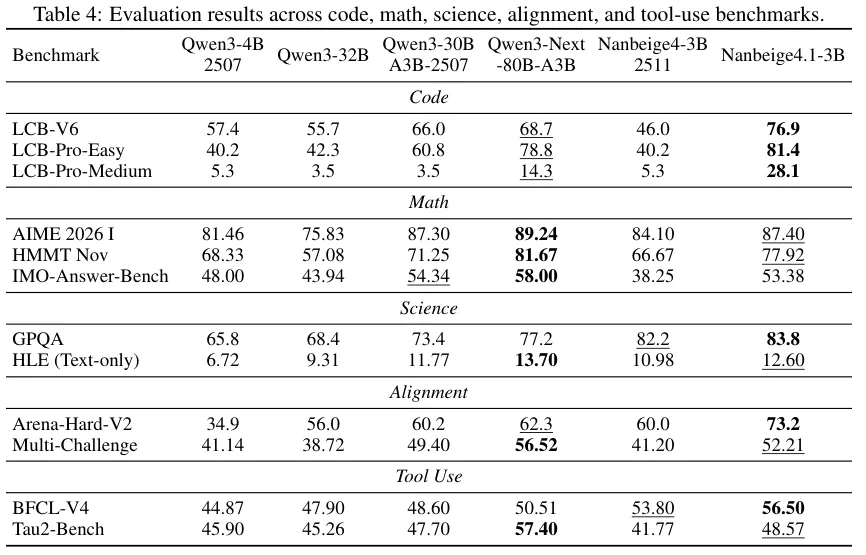
各项基准上,全面超越了Qwen3-32B,甚至已经与Qwen3-Next-80B-A3B对齐。
一个小巧玲珑却能自学自律的大脑,已经足以胜任我们生活里绝大多数的复杂委托。
这让终端设备的未来充满无限遐想。
参考资料:
https://arxiv.org/pdf/2602.13367
https://huggingface.co/Nanbeige/Nanbeige4.1-3B