老黄的老谋,DeepSeek的深算
英伟达会建立一个开源模型的新秩序吗?
它发布了一个几乎完全透明的开源模型,公布了权重、数据集和配方。中国以DeepSeek为代表的开源模型,仅开放了权重。
GTC 2026即将于下周一举办,继去年12月发布开源模型Nemotron 3 Nano(Nano)之后,英伟达发布开源模型Nemotron 3 Super (Super),在开放性上,压倒了DeepSeek。
黄仁勋豁出去了。本周还非常罕见地发了一篇内部博文《AI是个五层蛋糕》,即能源、芯片、基础设施、模型、应用。
他特意用一段话谈到了开源模型的重要性:“世界上大多数模型都是免费的。研究人员、初创公司、企业乃至整个国家都依赖开源模型来参与先进的人工智能项目。当开源模型达到技术前沿时,它们不仅仅会改变软件,还会激活整个技术栈的需求。”
他还以DeepSeek-R1为例:“它通过广泛应用强大的推理模型,加速了应用层的普及,并增加了底层训练、基础设施、芯片和能源的需求。” DeepSeek,目前在中国扮演着“激活整个技术栈”的角色。任重道远。
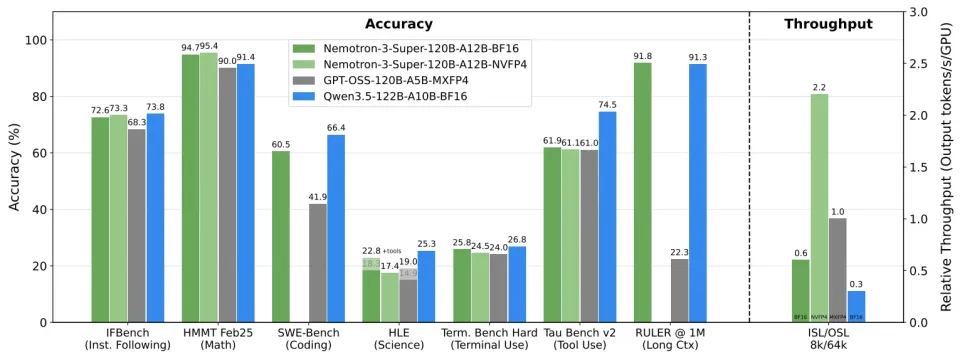
Nemotron 3系列的Super,还有接下来的Ultra,就寄托着老黄的期待。Super的总参数量是1200亿,在MOE架构下有120亿活跃参数。英伟达称它可以在软件开发、安全故障排查等多智能体应用领域,实现最大效率和准确性。
Super可以提供百万token上下文,支持智能体的长期记忆,实现对齐和高精度的推理。英伟达称,Super不仅仅是Nano的放大版,它引入了架构创新,能平衡好高参数推理模型中典型的效率-准确性问题。
架构上,混合Mamba-Transformer主干网将Mamba层与Transformer层相结合,以提高序列效率并实现精确推理,从而提供更高的吞吐量,内存和计算效率提高 4 倍。
Super在预训练期间的大部分浮点乘加运算都使用英伟达的4位浮点格式NVFP4进行。NVFP4针对Blackwell架构进行了优化,与FP8相比,它显著降低了内存需求并加快了推理速度,同时保持了精度。
Super在多项智能体基准测试中实现了领先的准确率,在吞吐量上实现了碾压。
英伟达公布了它训练数据集。预训练包括10万亿个经过整理的token,额外加入了100亿推理token,以及1500万道编程题。后训练数据集包括4000万条新的监督和对齐样本,覆盖推理、指令遵循、编程、安全以及多步骤智能体任务。这些数据用于监督微调、偏好数据以及强化学习轨迹,其中大约700万条直接用于 SFT(监督微调)。
英伟达还公布了强化学习任务与环境:在21种环境配置和37个数据集上进行交互式强化学习训练(其中大约10个数据集将会发布),包括类似软件工程师的智能体训练任务,以及带工具增强的搜索和规划任务。这使训练从静态文本扩展到动态、可验证的执行工作流,在训练过程中共生成了大约120万条环境 rollout。
英伟达发布了Super的完整训练和评估方案,涵盖从预训练到对齐的整个流程。这使得开发者能够复现Super的训练过程,针对特定领域调整方案,或将其作为自身混合架构研究的起点。
开源模型分为权重开放、数据透明、训练流程开放。一般来说,如果模型公布了训练数据,在研究可复现性上,它的确代表更高水平的开源。
开放权重模型是指直接发布权重、任何人都可以下载运行的模型,但训练数据和训练流程通常都不公开。中国的开源模型公司采用的策略是生态扩张优先,开放权重可以让企业部署、开发者微调,本地推理,快速形成应用生态。在与闭源API竞争时,开放权重还可以让企业客户实现成本优势、自主可控。
提高数据透明度,涉及版权、网络抓取、合作数据,公开这些数据,必须要避免法律上和商业上的麻烦。
对比一下Nemotron与中国的DeepSeek们:

Nemotron是真正的开源模型,而且它不仅是一个模型,而且是一整套“开源模型开发平台”。
从这个角度看,英伟达推出Nemotron并不只是做一个模型,而更像是在推动一种围绕GPU计算体系的AI生态。
首先要理解一点:英伟达的核心商业模式并不是卖模型,而是卖算力平台。它的收入主要来自GPU、CUDA软件栈、网络互连和数据中心系统。只要全球AI的训练和推理规模持续扩大,就会带来更多GPU需求。因此,对英伟达来说,最重要的不是某个模型是否领先,而是整个AI生态是否继续依赖GPU计算体系。
在黄仁勋的五层蛋糕里,发布像Nemotron这样的开源模型有几个战略作用:
首先,把开源作为GPU销售的最强杠杆。这是最核心的一点。英伟达卖的不是模型,卖的是芯片和计算基础设施。
Super通过NVIDIA NIM打包,可以从工作站到云端随处运行,并且支持vLLM、Google Cloud Vertex AI、Oracle Cloud、CoreWeave等众多平台。 模型越开放、部署越广泛,跑模型所需的H100/H200/Blackwell GPU就卖得越多。
其次,用架构创新绑定自家硬件。Super是Nemotron 3系列中首个结合了LatentMoE、多token预测(MTP)层和NVFP4预训练的模型。 其中NVFP4是英伟达Blackwell架构独有的数值格式——原生NVFP4预训练专门为NVIDIA Blackwell优化,大幅降低了内存需求。
换句话说,模型虽然开源,但在英伟达GPU(尤其是最新Blackwell)上的性能远超其他平台。开源配方实际上在全球范围内"传授"了一套天然向英伟达硬件倾斜的技术路线。
最后,以比DeepSeek更开放的模型抢占技术话语权。英伟达此时以极度透明的姿态入场,是在向全球开发者社区发送信号:最领先的模型技术来自美国、来自英伟达生态。
Super包含针对现实世界智能体任务的多环境强化学习,相关RL环境和数据集对开发者开放,用于领域定制和可复现性研究。这种透明度会快速聚拢全球研究者和企业开发者,围绕英伟达生态构建论文、工具链、社区,形成对竞争对手的软性护城河。
开源加快了模型的商品化,真正有价值的就变成了底层计算平台和系统架构,而这正是英伟达最擅长、也最希望掌控的领域。
这也说明AI产业正在从模型竞赛逐渐转向平台竞赛。未来的竞争很可能不是谁拥有一个最强模型,而是谁能够构建一个完整、高效、可扩展的 AI 计算与应用生态系统。
这样看来,只想做模型而不做应用的DeepSeek,最重要的可能还真不是就简单发布DeepSeek-4。单个模型而言,在中国也无摆脱商品化,关键是它在中国的AI计算与应用生态中发挥的作用。
DeepSeek主动适配国产芯片,就等于在给整条国产算力供应链做背书和激活。每一个基于DeepSeek开源版本做应用的中国开发者,都会把算力需求导向国产硬件。这对华为昇腾、海光、寒武纪、摩尔线程、燧原等公司的价值不可估量。
DeepSeek-4,的确要花点时间。
--
参考:
https://developer.nvidia.com/blog/introducing-nemotron-3-super-an-open-hybrid-mamba-transformer-moe-for-agentic-reasoning/
https://blogs.nvidia.com/blog/ai-5-layer-cake/