实测Tabbit: OpenClaw很火,但你可能只需要AI浏览器
邮箱|huangxiaoyi@pingwest.com
OpenClaw最近彻底刷屏。不到100天GitHub Star数突破250,000,超越React 13年的积累,成为GitHub 历史上Star增速最快的开源项目。所有人都在讨论“AI 能自己操控电脑了”。
但冷静想一想——它的部署门槛,对普通人来说几乎不可逾越:Docker配置、SSH、API Key申请……加上安全隐患频发、调用成本高企,每一步都在劝退人。当下的热度,更多属于开发者圈子的焦虑外延。
但它的火,也恰恰说明了一件事:大家对AI介入工作流的渴望是真实的。 只是需要一个门槛更低、更贴近日常的方式来实现。
实际上,对大多数人来说,一个AI浏览器可能就够了。
1
实测:和Tabbit做写稿搭子
为了测试AI浏览器,我决定先从日常工作开始,整个写稿过程只用Tabbit这一个产品,看看AI浏览器能不能扛下来。毕竟,写作的逻辑不只对内容创作者成立——搜索信息、做研究、整理资料,是每个人日常都有的通用场景。
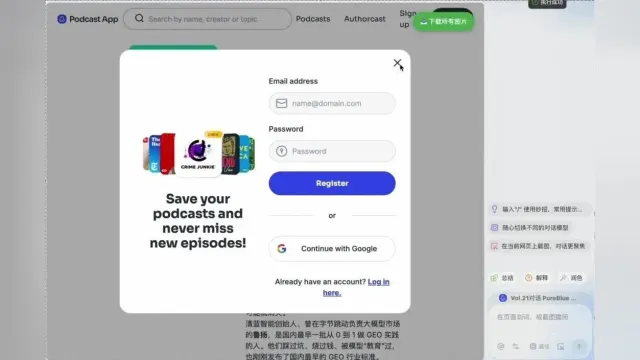
先介绍一下Tabbit的几个核心功能:浏览器本体、Chat、智能代理、妙招功能。利用这几个功能,我的创作过程,大致分为三步。
第一步,在正式开工之前,先用“妙招”创建写作模板。
妙招的功能类似Claude Code和龙虾里的Skill,用户可以自主创建妙招,保存和复用高频提示词,需要时在Chat对话框里,输入「/」就可以调用。
我在动笔之前创建了两个:实测类专家写作、资料搜集。
其中“资料搜集”包含了我平时调研时的思考框架——从市场格局到产品差异,从技术架构到用户反馈。这一步花了不到十分钟,但它决定了后续整个过程的质量。
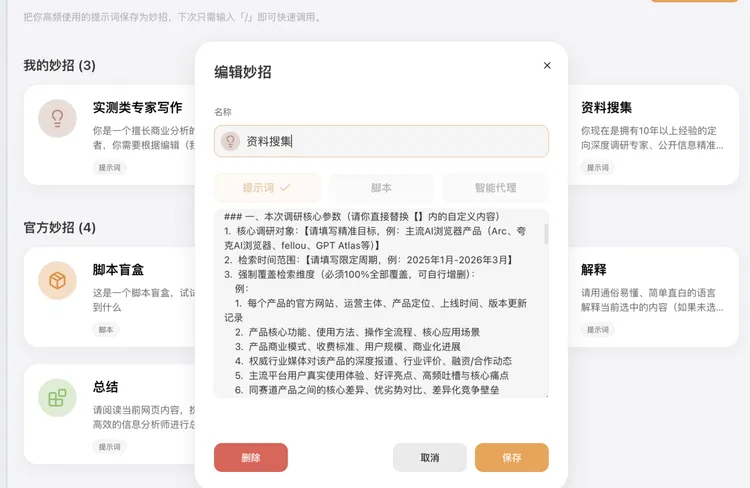
第二步,调用“资料搜集”妙招,进入调研环节。
AI按我预设的框架展开搜索,给出了一份覆盖面完整的调研报告,沉淀在当前对话里,以下是截取的产品对比:

这个过程中有三个体验让我印象很深。
第一是,我可以打开报告中的任意链接,针对网页截屏,或是划线选中某段文字,直接注入Chat对话中,让AI就这段具体内容展开分析,上下文始终连贯。

其次,是智能标签页——我同时打开了十几个页面,Tabbit自动将标签分类整理,行业报告归一类、产品官网归一类,导航栏一目了然,治愈了强迫症患者。
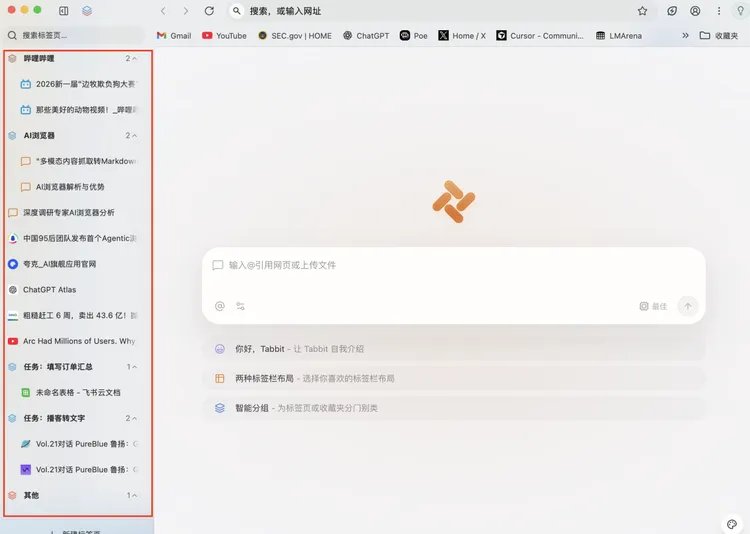
最后,最值得一提的是妙招中的脚本妙招。
不同于提示词妙招,在脚本妙招中,用户可以通过自然语言提出需求,Tabbit自动生成对应代码脚本,保存后,就变成了一个可以随时调用的小妙招了,效果类似浏览器插件。
我在调研过程中,临时创建了一个“一键抓取页面图片”的脚本妙招,可以边看资料边下载素材。
试运行了下,一次就成功了,说明Tabbit把AI的代码生成能力和浏览器的实际运行环境做了精准适配。
(团队说后面还会解锁更多玩法,比如播客音频这类多模态信息的抓取,如果你有什么脑洞大开的需求,咱们评论区见,说不定下个版本就适配上了。)
第三步,进入写作过程。
在和AI一起收集资料、测试、对话探讨的过程中,我基本形成了自己的思路,手动敲了一份思路文档,然后调用我的“实测类专家写作”妙招,让AI来补充,我甚至直接可以调用我的实测任务页面,让它自己整理测试情况。

因为我的妙招中,明确写出了:“在不明确如何执行的时候,向编辑提问,获得更清晰的选题角度,并确认各个部分的内容,不要一口气写作全文”,所以Tabbit向我提出了一系列的问题。
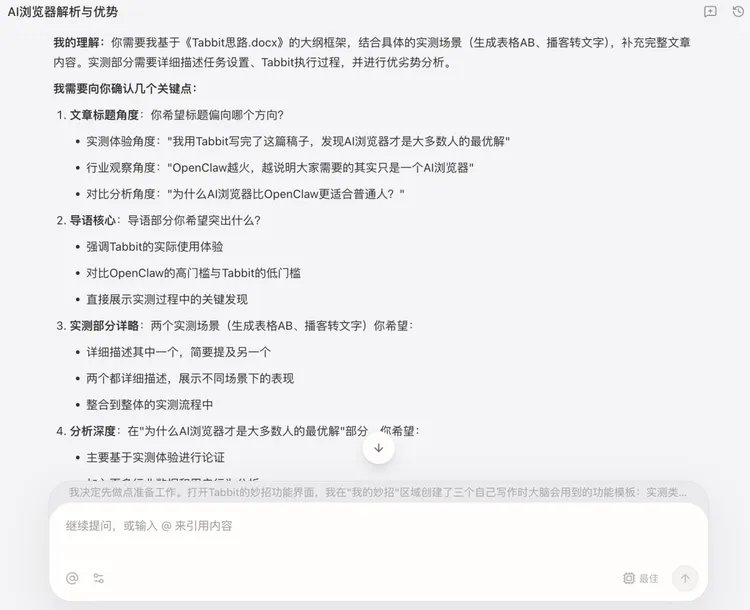
还好我有语音输入法,能够进行快速回复,在此,也希望Tabbit后续能增加一个语音输入的功能。
最终,AI基本完成了我的诉求。拿到初稿之后,我进行了一轮人工修改,然后就做完了。这也是AI浏览器区别于龙虾的关键, 它的核心逻辑是半自动。
我们既不能完全丢掉人,把所有判断都托付给AI、吃现成的输出;也不能拒绝效率进化,事事靠自己。
最好的状态,是人始终在回路里,而AI浏览器天然适合这个场景。
1
用妙招,把浏览器、上下文、AI和人串起来
在实测过程中,我最大的感触是,Tabbit替我解决了三层上下文断裂的问题。
最基础的一层,是AI 对话之间的断裂。
因为不同模型的技能点不同,很多人现在的 AI 工作流是多AI的组合:用Perplexity或DeepSeek做初步搜索,觉得某个方向值得深挖,就把结果粘到Claude里分析;想发散一下,再切到Gemini去问几个角度。
三个独立对话窗口,三段断掉的上下文。每一次复制粘贴,都在做同一件事:把当前对话里已经积累的上下文——你追问的方向、AI给出的补充、你划掉的那些不要的角度——整体丢弃,然后在新窗口里重新建立一个更薄的版本。
而在AI浏览器中,通过多模型接入,共享同一个上下文解决了这个问题——切换模型不需要新开窗口,你的对话历史和引用内容始终在线。
第二层断裂,是信息获取过程的碎片化。
在做调研的过程中,由于需要参考大量资料,以前要么纯人工,打开几十个网页,挨个阅读;要么纯AI,直接搜到回答给你。
我们越来越发现,纯粹地依赖后者,容易出现信息收集过于狭窄、缺乏细节的问题,人始终需要参与获取更多数据,来拓宽自己的知识库。
因此,在和AI共同搜索的过程中,DeepResearch类工具是必要的。但它们虽然能深度搜索,本质上仍是一个独立页面:搜完之后,如果你想对某段结论深入追问,要么重新开对话,要么在结果末尾继续问,很难选中报告里某句话针对性展开。
而在Tabbit的Chat里,你可以一边让AI总结,一边同时打开多个资料来源页面,截屏、划线选中某段文字,或者直接把几个标签页纳入对话,和 AI 一起做横向对比。这就是human in the loop(人机协同闭环) 的具体形态——随时接管,而不是只能接受 AI 整理好的结论。
从这个角度来说,DeepResearch应该是浏览器的原生能力,而不是一个单独的工具——信息就在眼前,追问也应该发生在同一个地方。
第三种断裂,发生在工具能力层。
多模态文本抓取、全文翻译、批量下载素材……这些需求以前靠安装插件解决,但插件要找、要装、要管理,本质上还是在工具之间跳来跳去。
妙招功能往前走了一步。普通妙招保存的是提示词,脚本妙招保存的是能力——用户可以根据自己的个性化需求,自定义“插件”,随时做、随时用。
比如我在调研过程中,临时创建的“一键抓取页面图片”的脚本妙招,你也可以借助脚本妙招,把网页切换为阅读模式、给页面换成夜间皮肤......
过去AI辅助工作流的一个隐形成本是,上下文是断的,工具是割裂的。妙招和Chat的组合,不只是“保存常用提示词”,而是把每个人流程中出现的痛点和经验,变成可复用的工具,配合始终在线的上下文,让工具边界消失了。
可以说,Tabbit提供了一个让思考能够完整展开的环境:信息在哪里,工具就在哪里,人和AI始终可以介入。
1
AI浏览器,才是大多数人的最优解
不过,目前的产品还有迭代的空间。比如,智能代理这个环节,我们专门做了一个测试:打开了飞书文档里的两个表格——“表格A原始数据”和“表格B订单汇总”,让Tabbit分析A中的数据结构,然后按照B的格式要求自动填写汇总信息,这也是比较典型的数据处理场景。
在执行过程中,Tabbit识别了两个表格的维度差异:产品类别、省份、订单状态、支付方式……约一分钟后开始作业,并理解了数据逻辑、处理了计算规则、匹配了格式要求。
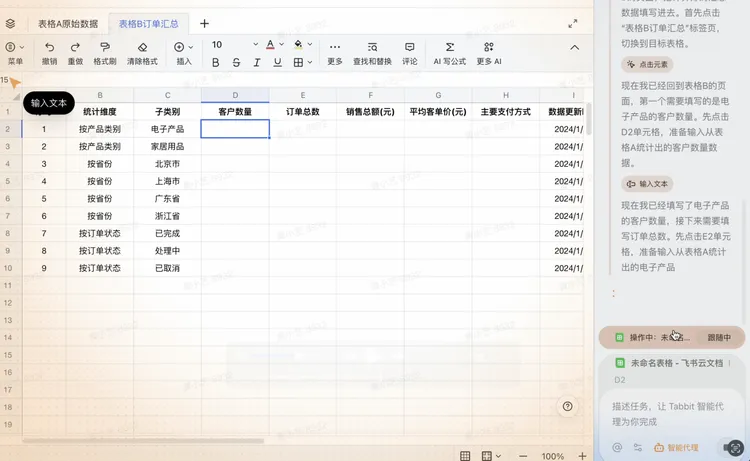
但很快,问题出现了:GUI代理对飞书表格的识别不够准确,反复填错单元格,任务没能跑通。我换了一种思路,放弃GUI操作,改用Chat直接处理文档内容,反而一次成功了。

这个弯路本身也说明了一件事:当前GUI智能代理的模型能力还有明显边界,更适合识别范围清晰的填写场景,比如问卷答题、在X和小红书发布内容这类操作。
这个问题并不是无解的。智能代理的边界,更多是模型能力的现阶段局限,随着 AI 能力的持续进化,模型越强,AI浏览器能覆盖的执行场景也就越多。
说回OpenClaw的走红,本质上是一种集体情绪的投射——大家看到 AI 能自己操控电脑,觉得自己也该拥有这个能力。但抛开安装门槛,它本身的风险也在持续发酵:安全漏洞、数据隐患、高额 API 成本等等,导致最近又开始流行起了“卸载OpenClaw教程”。
冷静下来想,真实的工作流里,有多少场景是非得让AI在本地文件系统里自主行动才能解决的,本地的文件可以上传到网页处理,大量的信息获取来自外部网络,需要传播内容的平台也基本都通过网页来完成——发帖、发文章、填表单,这些都是浏览器原生能做的事。
更重要的是,Human in the Loop的场景始终会存在——对C端用户来说,一个能涵盖全场景的工作台,永远比一个功能强大但难以驾驭的自动化工具更有价值,并且随着模型能力变强,AI浏览器的能力上限还在提升。
成为一个统一的工作台,同时也要求AI不只是简单地“存在于浏览器里”。
如果AI只是浏览器角落里的一个悬浮按钮,那和单独开一个ChatGPT窗口没有本质区别——你依然要在工具之间反复跳转,依然要重新组织上下文,承受那些隐性的时间损耗。
Tabbit的优点是,先用多模型接入,共享同一个上下文,再通过Chat打通多标签信息调用,这个过程中,用妙招消灭重复提示词、满足个性化需求,再配合智能代理,打开执行的想象空间。
这些功能单独拆开看,并不是革命性的创新,但组合在一起、长在浏览器里,就变成了一个一体化的工作场。
或许,普通人并不需要一台能自主操控电脑的 AI,而是需要一个真正把AI长在工作入口里的浏览器——在你本来就待着的地方,安静地、丝滑地陪你把事做完。而且它现在是免费的。
如果你也对OpenClaw感兴趣但无从下手,可以先从 AI 浏览器开始——前往官网,体验Tabbit:https://www.tabbit-ai.com/
也欢迎大家在评论区提出自己的妙招需求脑洞,或许下一个版本就上了呢。