CVPR'26 | 以机器人为中心的ToM推理框架,从心智推理到决策行动

新智元报道
新智元报道
【新智元导读】吉林大学&微软亚洲研究院等团队提出MindPower框架,让机器人像人一样理解他人想法并主动帮忙,构建了首个以机器人为中心的心智推理评测体系,通过六层推理链条,让AI不仅看懂场景,更能推断意图、做出决策、执行动作,显著提升助人能力。
近年来,随着视觉语言模型(Vision-Language Model, VLM)的快速发展,智能体在感知理解与任务执行方面取得了显著进展。
当前VLM在感知方面表现出色,但在行为层面仍然大多是被动反应式的。它们能够描述所见内容,却难以推理人类相信什么、想要什么或打算做什么。
与此同时,现有ToM基准虽然赋予了VLM一定的心智推理能力,但通常只局限于对视频中人类心智状态进行推理。它们并未从智能体自身视角构建ToM推理,使得VLM难以学习如何做出决策并生成动作。
为解决这些问题,吉林大学联合台湾大学、微软亚洲研究院提出了MindPower Benchmark,构建面向以机器人为中心的ToM推理框架,将环境感知、心智推理、决策生成与动作生成进行统一建模,并且构建了MindPower数据集,以及全面的评估指标。

主页链接:https://zhangdaxia22.github.io/MindPower/
论文链接:https://arxiv.org/abs/2511.23055
同时,研究人员提出了自己的方法,引入Mind-Reward强化一致性优化,显著提升ToM决策与动作生成性能。
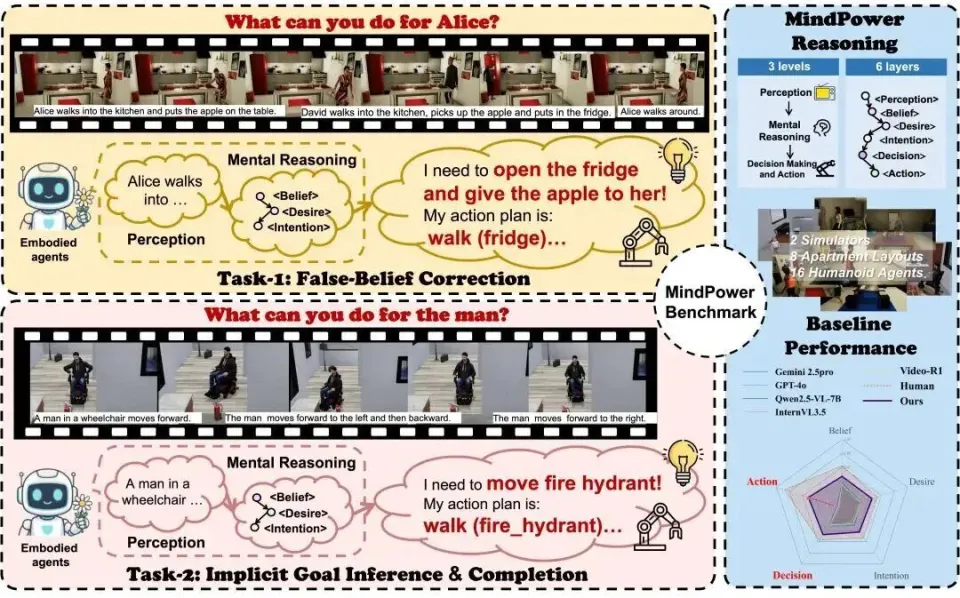
MindPower Benchmark概览图
研究人员构建了数据集:MindPower Dataset,围绕智能体在交互场景中的 ToM 推理与辅助决策能力进行构建,设计了两类核心任务:错误信念纠正(False-Belief Correction)、隐式目标推断与完成(Implicit Goal Inference & Completion)。
整体上,数据集共包含590个样本、8种公寓布局、16个类人智能体(humanoid agents)。
全部样本中390个用于错误信念纠正任务,200个用于隐式目标推断与完成任务,能够较系统地覆盖日常家庭环境中的典型交互与辅助行为场景。

公寓布局示意图

humanoid agents示意图
MindPower Dataset基于两个交互式家庭环境模拟器(VirtualHome 与 ThreeDWorld)构建,引入的humanoid agents涵盖不同年龄、性别与行动能力条件(如儿童、成年人及轮椅使用者)。
MindPower Benchmark希望系统评估智能体在真实交互场景中,能否基于 ToM 推理生成合理决策与动作。
为此,研究人员在数据层面重点围绕两类核心任务进行设计:错误信念纠正与隐式目标推断与完成。
错误信念纠正任务主要考察智能体是否能够识别「人物信念」与「真实环境状态」之间的不一致,并进一步采取合理的辅助行为来帮助人类。
隐式目标推断与完成任务强调从不完整线索中进行意图推理。该类任务中,人物的目标往往不会被直接明确表达,而是隐含在行为序列、物体功能属性、场景上下文以及交互线索之中。模型需要综合这些信息推断人物的真实需求,并给出符合场景约束的协助策略与动作规划。
研究人员在任务设计中引入了统一的MindPower推理层级 (Reasoning Hierarchy),将智能体决策过程扩展为分布在三个层级上的六个层次,反映了智能体如何在环境中进行感知、推理和行动。
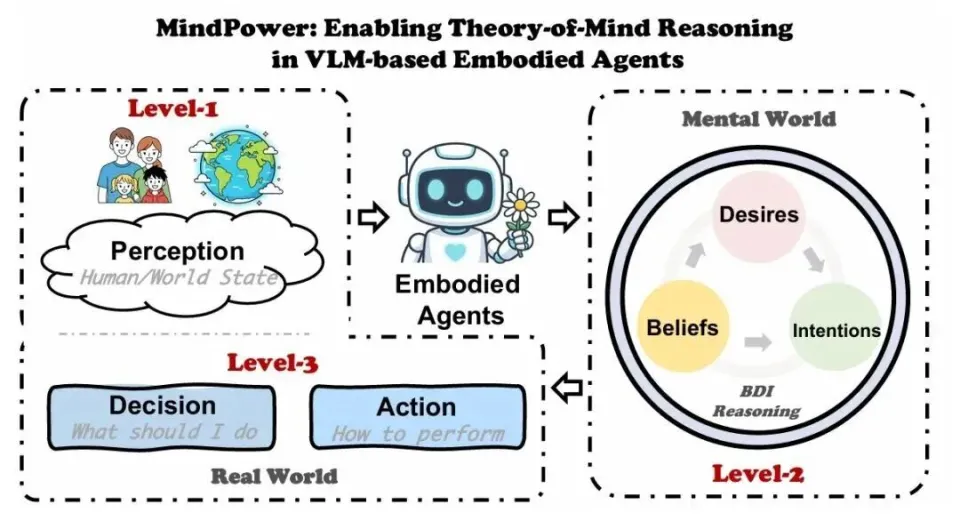
MindPower推理层级示意图
Level-1:感知(Perception)
智能体通过视觉或其他传感输入观察环境。该步骤回答的问题是:「现在发生了什么?」
Level-2:心智推理(Mental Reasoning)
<Belief> (信念) —— 基于感知,对人类状态与环境状态进行推理。不同于仅反映智能体自身理解的一阶信念(first-order belief),该框架建模的是二阶信念(second-order belief):智能体不仅推断自己的信念,还会推断它所预测的场景中人类的信念。
<Desire> (欲望) —— 从智能体的信念中推理出的偏好状态或目标。对于智能体而言,欲望由「帮助人类」的目标所塑造,并进一步决定需要提供什么帮助。
<Intention> (意图) —— 基于智能体的信念与欲望形成的,表示机器人想要做什么。
Level-3:决策与行动(Decision Making and Action)
<Decision> (决策) —— 智能体为实现意图所做出的选择或计划。
<Action> (动作) —— 动作执行序列,智能体通过高层原子操作来落实其决策,动作形式为 action (object),例如 open (fridge) 或 pick_up (milk)。
整体而言,MindPower 强调「机器人中心(Robot-Centric)」视角:模型不仅需要理解人的心智状态,还需要基于这种理解完成自身决策与动作生成。这使得 benchmark 的评测目标从传统的心智状态识别,进一步扩展到心智推理驱动的决策与行为能力评估。
在数据集的构建上,遵守这三个要点:真实性(Realism)、BDI一致性(BDI Consistency)、在模拟器约束下的多样性(Diversity under simulator constraints)
具体而言,数据集中每个样本不仅要求场景事件在现实中「说得通」,还要求从<Perception>到<Action>的层级推理链条保持逻辑一致,并尽可能在可模拟、可标注的前提下覆盖不同角色、目标与场景组合。
在数据构建流程上,研究人员采用了一个完整的三阶段流水线:
故事脚本构建:基于房间类型、角色设定、目标与相关物体,由 GPT-4o 生成初始故事脚本,并由 5 名标注者进行人工筛选,剔除不合理或不真实的情境;
多模态数据采集:在模拟器中严格复现场景脚本并采集视频数据,单个样本在 VirtualHome 中约需 25–35 分钟,在 ThreeDWorld 中约需 50–70 分钟;
MindPower 推理层级标注:由 5 名受训标注者为每个样本标注完整的六层推理结构(从感知到动作),形成可用于训练与评测的结构化监督信号。
由此,每个样本均可获得模拟器录制视频与对应的 MindPower 推理层级标注。
MindPower Benchmark 指标覆盖了从感知、心智推理到决策与动作的完整链路,并结合各类指标与 LLM 评分进行多层次评价。
在层级化评估方面,分别对Perception(感知)、Mental Reasoning(心智推理) 与Decision(决策) 的文本输出进行语义一致性评估。
具体来说,研究人员采用BERTScore与Sentence Transformer score两类指标,用于衡量模型输出与参考答案在语义层面的匹配程度。
其中,感知层主要评估场景描述与人物状态识别的准确性;心智推理层评估 <Belief> / <Desire> / <Intention> 的语义一致性;决策层则评估模型生成的决策是否与参考决策语义一致。
对于Action(动作生成),进一步引入了面向动作序列的专门指标,以评估模型是否真正生成了可执行、有效的协助动作。
研究人员使用了Success Rate(SR)与Action Correctness(AC)两项指标
SR综合ROUGE-1 / ROUGE-2 / ROUGE-L等分量,用于衡量动作序列整体与参考动作序列的一致性;
AC则更关注原子动作层面的正确率,用于衡量模型生成的动作步骤是否准确命中关键动作目标。
除了上述指标,研究人员还强调对BDI一致性(BDI Consistency) 与机器人中心视角(Robot-Centric Perspective) 的评估。为此,研究人员使用GPT-4o对从<Perception> 到<Action>的完整输出进行评分,得到BPC(BDI and Perspective Consistency) 分数,重点考察三个方面:
各推理层之间是否逻辑连贯、无明显矛盾;
整体推理是否完整、具体;
推理是否真正从机器人协助者视角出发,能够基于人物状态生成合理帮助。
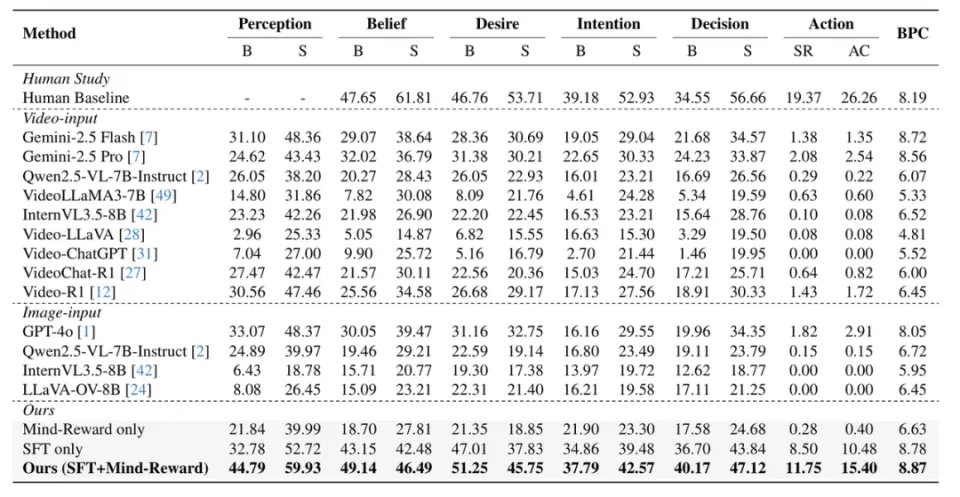
在完成MindPower Benchmark的数据、任务与评估设计后,研究人员在该基准上对人类参与者、闭源VLM以及开源VLM进行了系统评测。实验采用训练集/测试集8:2划分,并从感知、心智推理、决策与动作生成等多个层级进行评估。
整体结果表明,人类基线在各项能力上仍显著优于现有VLM,说明MindPower Benchmark 具有较强的区分度与挑战性,并非仅依赖浅层视觉描述即可取得高分。
闭源模型整体表现优于大多数开源模型,在感知、心智推理以及决策与动作生成层面均表现出更强能力;
其中,具有更强推理能力的模型通常在 benchmark 上表现更好,这也从侧面说明该基准确实能够衡量模型的以机器人为中心的 ToM 推理能力,而不仅仅是通用视频理解能力。
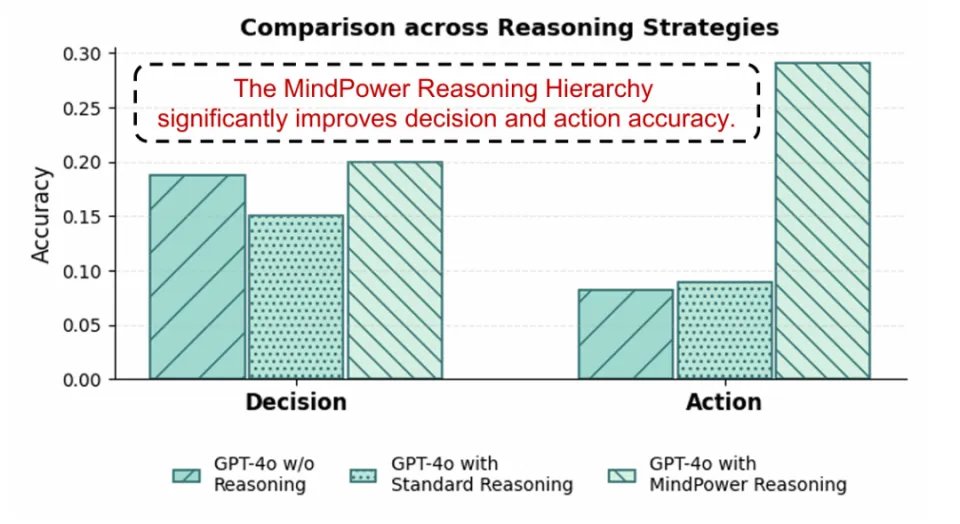
GPT-4o不同推理方式的结果对比图
同时,研究人员通过实验进一步验证了MindPower推理层级的必要性,对GPT-4o进行了对比实验:当移除分层推理结构、直接要求模型输出决策与动作时,模型在决策与动作生成上的表现明显下降;
即使采用通用的step-by-step(如 <think>...</think>)推理方式,也难以达到MindPower分层推理结构的效果。
这一结果说明,在以机器人为中心的心智推理场景中,简单的「逐步思考」并不能替代面向任务结构设计的推理层级,后者对于提升决策与动作生成的准确性与一致性具有关键作用。
为了让模型不仅能够「按要求输出」分层推理结果,还能够真正生成与证据一致、与决策和动作一致的ToM推理过程,研究人员采用了一个两阶段优化思路:先通过SFT(Supervised Fine-Tuning) 建立模型的基础分层推理能力,再通过GRPO(Group Relative Policy Optimization)进行强化优化,其中重点设计了面向ToM推理的奖励函数Mind-Reward。
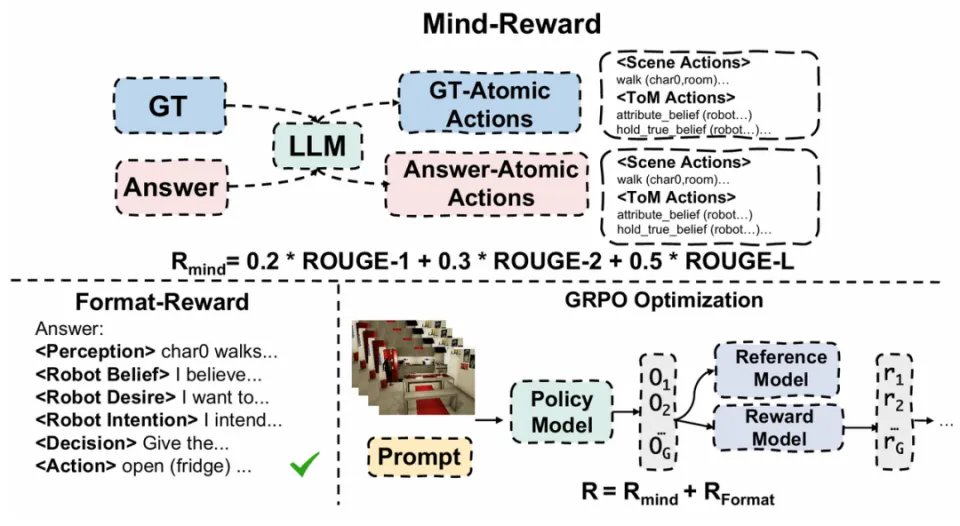
Mind-Reward示意图
在第一阶段的SFT中,对模型Qwen2.5-VL-7B-Instruct使用带有MindPower推理层级标注的数据进行监督学习,先学会按照统一的层级结构输出从感知、心智推理到决策与动作的完整结果。让模型先具备基本的任务能力,并稳定生成可解析、可评估的结构化输出。
在GRPO阶段,设计了由Mind-Reward与Format-Reward组成的奖励函数:其中Format-Reward用于约束模型输出是否满足预定义的分层结构与标签格式,确保生成结果在形式上稳定、完整;而真正的核心创新是 Mind-Reward,它用于从内容层面对模型生成的推理过程进行评估。
Mind-Reward设计由两个核心原则指导:
BDI一致性(BDI Consistency):从 <Perception> 到 <Belief>、<Desire>、<Intention>、<Decision>、<Action> 的推理层级,应当在所有层之间保持逻辑一致。
机器人中心优化(Robot-Centric Optimality):智能体必须从自身视角进行推理和行动。在心智推理(Mental Reasoning)阶段,它需要同时推断自己的信念,并对人类的信念进行二阶推理,同时保持正确的视角分离。
研究人员将每一层推理(从 <Perception> 到 <Action>)表示为一系列原子动作,记作 action (agent, object) :其中agent指状态拥有者(可以是智能体或人类),object 表示被作用的目标实体或心智状态内容。
由于心智推理层中的各层涉及不同的认知与物理推理模式,构建了一个统一的原子动作表,同时覆盖这两类动作。
随后在GRPO训练过程中,真实答案(ground-truth)和模型生成输出都会先由LLM(Qwen3-Max)转换为结构化的原子动作序列,再使用这些抽取出的原子动作进行奖励计算。
在实验部分,研究人员进一步验证了该训练策略的有效性,该方法不仅提升了分层推理质量,也显著改善了决策与动作生成等关键指标,在各项指标中均达到SOTA水平。
吉林大学计算机学院情感视觉与计算实验室(Affective Vision Computing Lab, AVC Lab)成立于2024年,由谢洪霞老师担任负责人。实验室主要研究方向包括计算机视觉与情感计算,近期的研究兴趣聚焦于生成式AI的情感理解及情感陪伴机器人等应用。
