Prompt、Skills、MCP:大模型上下文工程核心链路
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
Prompt:从静态指令到结构化思维
Prompt(提示词)是点燃大型语言模型(LLM)智能火花的“第一推动”。它是我们与模型最直接的沟通桥梁,也是整个上下文工程体系中最基础、最底层的入口。然而,随着我们对LLM的探索日益深入,对Prompt的理解也早已超越了“提问”这一简单概念,演化为一门引导模型进行结构化思考的精妙艺术。
1、Prompt的本质:一次性、静态的人机指令
从本质上讲,一个Prompt是用户或开发者为了让模型执行特定任务而提供的一段一次性的、静态的文本指令。它被输入到模型的上下文窗口中,作为模型生成后续文本的直接依据。在整个上下文技术栈中,Prompt扮演着“最底层入口”的角色——所有更高级的上下文信息(如RAG检索的内容、工具的输出、历史对话的摘要),最终都必须被“编译”成文本,并作为Prompt的一部分呈现给模型。
这个“静态”和“一次性”的特性,既是Prompt强大之所在,也是其局限之所在。它简单、直接,让任何人都能快速上手与AI互动。但它也像一张一次性的任务卡,一旦发出便无法更改,且缺乏对动态变化世界的感知能力。
2、高级Prompt技法:引导模型“思考”
为了在静态输入的限制下,最大化地激发模型的推理能力,社区发展出了一系列堪称“高级炼金术”的Prompt技法。这些技法不再是简单的命令,而是试图在Prompt中构建一个“思维脚手架”,引导模型一步步地走向正确答案。
2.1 思维链(Chain-of-Thought, CoT)
2022年,Google的研究者发现,在处理需要多步推理的复杂问题(如数学应用题)时,如果只是直接要求模型给出答案,模型很容易出错。但如果在Prompt的示例中,不仅给出答案,还给出一系列中间推理步骤,模型的表现就会大幅提升。这种方法被称为思维链(Chain-of-Thought, CoT)。
标准Prompt示例:

模型可能会直接给出一个错误的答案,比如 11。
CoT Prompt示例:

通过引导模型先思考推理过程,模型更有可能得出正确答案:“罗杰以5个球开始。2罐3个网球,每个是2*3=6个球。所以他有5+6=11个球。答案是11。”
CoT的魔力在于,它将一个复杂的推理任务,分解成了一系列更简单的、线性的步骤。这不仅提高了结果的准确性,也让模型的“思考过程”变得可见和可解释,极大地增强了我们对模型行为的信任。
2.2 ReAct:协同推理与行动
CoT解决了纯粹的“思考”问题,但如果任务需要与外部世界互动(例如,查询一个信息、调用一个工具)呢?2022年,同样来自Google的研究者提出了ReAct(Reason + Act)框架。
ReAct的核心思想是让模型在推理和行动之间交替进行。它在Prompt中为模型定义了一个清晰的循环结构:
1.Thought(思考):分析当前任务,决定下一步需要做什么。
2.Action(行动):选择一个工具并执行(例如,Search[keyword] 或 Lookup[term])。
3.Observation(观察):获取行动返回的结果。
这个“思考-行动-观察”的循环会一直持续,直到模型认为已经收集到足够的信息来回答最终问题。
ReAct Prompt示例(简化版):
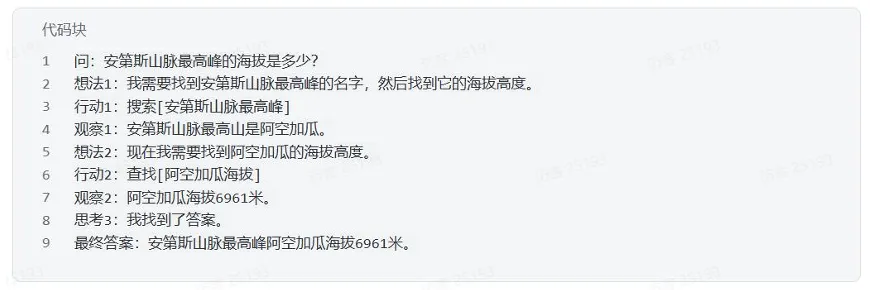
ReAct框架是构建现代AI智能体的基础。它通过一个结构化的Prompt,赋予了模型规划、执行和利用外部工具的能力,使其不再是一个封闭的“语言大脑”,而是一个能够与环境互动的“行动实体”。
3、Prompt的根本痛点:脆弱、难管、与世隔绝
尽管高级Prompt技法极大地扩展了LLM的能力边界,但它们并未能解决Prompt作为一种技术的根本痛点。这些痛点,在构建复杂、可靠的生产级应用时,会变得愈发突出:
脆弱性(Brittleness):Prompt的效果极其依赖经验和运气。一个词的改变,一个换行符的增删,都可能导致输出的巨大波动。这种不确定性使得Prompt的开发更像一门“玄学”而非“工程”。
难以管理(Poor Manageability):随着应用逻辑变复杂,Prompt会变得越来越长、越来越臃肿,形成所谓的“Prompt泥潭”(Prompt Swamp)。成百上千行的Prompt混杂着指令、示例、变量和逻辑,极难阅读、维护和迭代。
无法连接实时世界(Lack of World Connection):Prompt是静态的。它无法直接访问实时数据、调用外部API或感知系统状态的变化。所有动态信息都必须由外层代码预先处理好,再“注入”到Prompt中,这大大增加了应用开发的复杂性。
缺乏记忆与状态(Statelessness):Prompt本身是无状态的。要在多轮交互中维持记忆,开发者必须手动管理对话历史,并将其作为Prompt的一部分反复传递给模型,这不仅成本高昂,也极易超出上下文窗口的限制。
4、必然的演进:从Prompt Engineering到Context Engineering
正是这些深刻的痛点,驱动着我们必须超越Prompt本身,去思考一个更宏大的问题:我们如何才能系统性地、工程化地为模型提供它完成任务所需的一切信息?
这个问题的答案,就是上下文工程(Context Engineering)。

这个系统需要能够:
从各种来源(数据库、API、传感器)主动获取信息。
对信息进行处理、压缩和结构化。
根据任务的动态进展,对上下文进行编排和路由。
在整个过程中,确保安全、合规和可追溯。
Prompt并没有消亡,它依然是整个上下文信息流最终汇入模型的那个“入口”。但它不再是舞台的唯一主角。它成为了一个更宏大、更复杂的系统中的一个基础组件。我们的焦点,也从对这个“入口”的精雕细琢,转向了对整个信息供应“管道”的系统设计。这,便是从Prompt Engineering走向Context Engineering的必然。
Skills:可复用、可组合的能力单元
如果说Prompt是向模型下达“做什么”(What to do)的指令,那么Skills(技能)则是定义模型“能做什么”(What can be done)的能力清单。在上下文工程的体系中,Skills是连接LLM的推理能力与外部世界实际功能的桥梁。它们将抽象的任务分解为一系列可执行、可管理的具体操作,是构建任何非凡智能体(Agent)的“手和脚”。
1、Skill的定义:从临时工具到能力资产
一个Skill,本质上是一个标准化的、可被模型理解和调用的能力单元。它不仅仅是一段代码或一个API端点,而是一个包含了完整自我描述的“能力资产”。一个定义良好的Skill,通常由三部分组成:
1.功能逻辑(Functional Logic):这是Skill的核心,即实际执行操作的代码。它可以是一个简单的Python函数(如计算器),也可以是一个复杂的业务流程(如调用公司内部API创建一张销售订单)。
2.调用接口(Interface Schema):这是模型理解和使用Skill的“说明书”。它用一种结构化的格式(通常是JSON Schema)清晰地描述了该技能的用途、所需的输入参数(名称、类型、描述)以及返回值的格式。
3.元数据(Metadata):这包含了关于Skill的额外信息,如版本号、所有者、依赖关系、使用成本、执行历史、用户评价等。元数据对于技能的发现、治理和演进至关重要。
一个简单的Skill定义示例(以JSON Schema格式描述接口):

这种结构化的定义,使得Skill不再是应用代码中一个模糊的函数,而是一个独立的、可被发现、可被组合、可被管理的能力单元。
2、Skill在上下文中的角色:能力的显式化
在上下文工程的栈中,Skills扮演着至关重要的角色:它们是“能力上下文”(Capability Context)的基本单位。当我们将一个或多个Skill的接口定义注入到模型的上下文中时,我们就在明确地告诉模型:“你现在拥有了这些超能力”。
这带来了两大核心价值:
1.让模型成为规划者:当模型理解了自己能做什么之后,它就可以在ReAct等框架的指导下,自主地将复杂任务分解为一系列对Skills的调用。例如,面对“帮我预订一张明天从上海到北京的机票,并找出评分最高的三家机场酒店”这样的复杂指令,模型可以自主规划出行动步骤:

2.让能力可动态组合:由于Skills是标准化的单元,它们可以像乐高积木一样被灵活地组合。今天,你可以给模型装备“天气查询”和“新闻播报”两个技能;明天,你可以换成“代码生成”和“数据库查询”的技能组合。这种动态性使得构建能够适应不同场景的通用智能体成为可能。
3、Skill的生命周期:从定义到演进
将Skills视为一种“能力资产”,意味着我们需要对其进行全生命周期的管理。
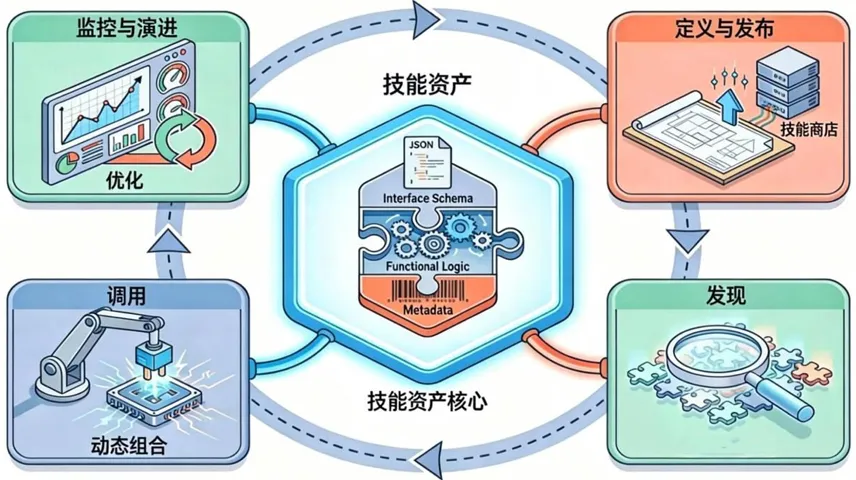
一个成熟的Skill生命周期管理流程通常包括以下五个阶段:
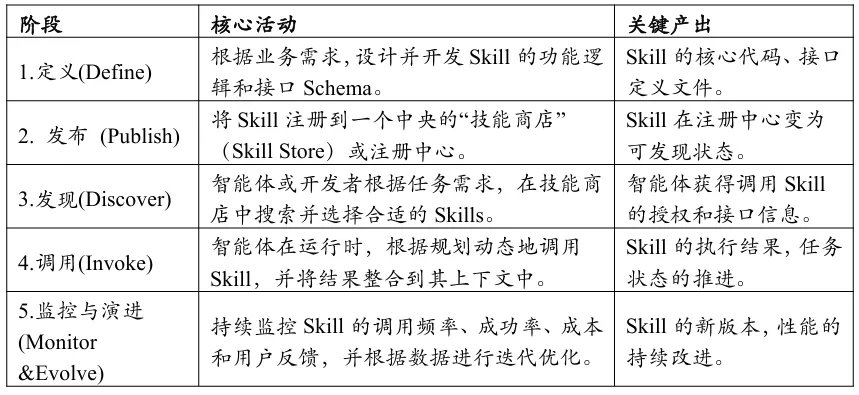
这个闭环流程确保了组织内的能力可以被系统性地沉淀、复用和优化,而不是随着单个项目的结束而流失。
4、演进之路:从自定义JSON到标准化协议
Skill的理念并非一蹴而就,它经历了从“临时方案”到“行业标准”的演进过程。
在早期,开发者需要自己定义一套JSON格式来描述工具,并编写大量的胶水代码来解析模型的输出,判断模型意图,然后执行相应的函数。这个过程繁琐且易错。
2023年,OpenAI的Function Calling功能 是一个重要的里程碑。它允许开发者在API请求中,直接传入一个遵循特定JSON Schema的函数列表。如果模型认为需要调用某个函数,它会在API的返回中,给出一个包含函数名和参数的、结构化的JSON对象。这极大地简化了工具使用流程,开发者不再需要用复杂的正则表达式去解析模型的文本输出来猜测其意图。
随后,各大模型提供商纷纷跟进,“Tool Use”或“Tool Calling”成为了旗舰模型的标配。然而,这仍然是一个“厂商锁定”的方案。每个模型API都有自己的一套工具调用规范,这给构建跨模型、跨平台的应用带来了障碍。
5、标准化Skill定义与实现
近期火热的Skills,是Anthropic首先推出的标准化上下文工具。在Claude的体系中,Skills是Markdown格式的文件,包含YAML frontmatter和正文内容,这与传统的JSON Schema定义有所不同。
一个标准的Skill由SKILL.md文件定义,采用Markdown格式:

关键要点:
name字段:使用动名词形式(如processing-pdfs),只能使用小写字母、数字和连字符,最大64字符
description字段:使用第三人称描述,包含触发条件,最大1024字符
正文内容:提供实际的操作指南和代码示例
一个完整的Skill目录结构如下:

这种结构实现了渐进式披露(Progressive Disclosure):Claude只在需要时才加载额外的参考文件,从而节省Token并保持上下文聚焦。
推荐使用检查清单来跟踪复杂工作流的进度:

通过定义更多的Skills,并设计更复杂的逻辑来管理它们,我们就可以构建出能够处理现实世界中各种复杂任务的强大智能体。
MCP:单智能体的上下文扩展坞
上文我们确立了Skills作为标准化“能力单元”的重要性。然而,仅仅将能力单元化是不够的。如果每个AI应用都用自己的一套方式来加载和调用这些能力,我们只不过是把混乱从代码层面转移到了集成层面。我们需要一个统一的“插座”标准,让任何Skill都能轻松地“接入”任何智能体。模型上下文协议(Model Context Protocol, MCP)正是为解决这一挑战而生的关键组件。
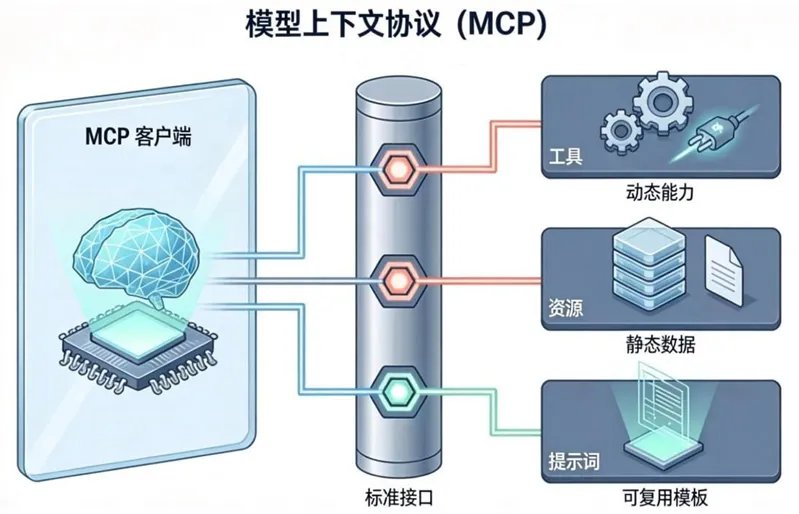
MCP可以被看作是单个智能体的“上下文扩展坞”。它是一个开放的、标准化的协议,旨在定义智能体(客户端)与外部能力(服务器)之间的通信方式,从而将动态的、结构化的外部上下文无缝集成到模型的工作流中。
1、MCP要解决的核心问题:能力集成的“巴别塔”
在MCP出现之前,AI应用与外部工具的集成处于一种“巴别塔”式的混乱状态:
紧耦合:工具的调用逻辑与应用代码紧密耦合。更换一个API,或者修改一个数据源,往往需要重写大量的应用层代码。
厂商锁定:每个大模型厂商都提供了自己的工具调用(Tool Calling)方案。为OpenAI写的工具调用代码,无法直接用于Claude或Gemini,反之亦然。这使得构建跨模型的、可移植的智能体变得异常困难。
静态与不透明:可用的工具列表通常在应用启动时就已确定,并硬编码在代码中。智能体无法在运行时动态发现和加载新能力,也无法理解工具的实时状态或使用成本。
MCP通过引入一个标准的客户端-服务器(Client-Server)架构,从根本上解决了这些问题。
2、MCP的核心架构:解耦智能体与能力
MCP的架构非常清晰:
MCP客户端(MCP Client):通常是AI智能体或其宿主应用。它负责与大模型交互,并根据模型的意图,向MCP服务器发起请求。
MCP服务器(MCP Server):一个独立的Web服务,它托管一个或多个Skills,并向外暴露一个遵循MCP规范的标准化接口。
在这种架构下,智能体(Client)和能力(Server)被彻底解耦。智能体不再需要知道一个Skill的具体实现细节,它只需要知道MCP服务器的地址,然后通过一个标准化的“对话”流程来发现和调用能力。
这个“对话”流程通常包含两个核心步骤:
获取能力清单(/mcp/v1/tools):客户端首先向服务器的这个标准端点发起请求,获取一份该服务器上所有可用Skills的结构化描述(即它们的接口Schema)。
调用指定能力(/mcp/v1/tools/{tool_name}):当模型决定要使用某个Skill时,客户端就向该Skill对应的端点发起一个POST请求,请求体中包含了模型生成的、符合Schema的参数。
3、MCP的三大原语:不止于工具
MCP的精妙之处在于,它将外部上下文抽象为三种核心的“原语”(Primitives),极大地扩展了其应用范围:
工具(Tools):这是最核心的原语,代表了可被调用的动态能力,即我们前一章讨论的Skills。例如,send_email或query_database。
资源(Resources):代表了可被引用的静态或半静态数据。这些数据通常比较庞大,不适合直接放入Prompt,但可以作为背景信息提供给模型。例如,一篇PDF格式的公司财报、一个CSV格式的用户列表、或者一段WAV格式的会议录音。客户端可以请求关于这个资源的元数据(/mcp/v1/resources/{resource_id}/metadata)或其内容的摘要。
提示词(Prompts):代表了可被复用的、结构化的Prompt模板。一个MCP服务器可以提供一系列针对特定任务优化过的、高质量的Prompt模板(例如,一个用于“分析用户反馈”的ReAct风格模板)。客户端可以直接获取并使用这些模板,而无需自己从头构建。
通过这三大原语,MCP为智能体提供了一个远比简单的Function Calling更丰富、更完整的上下文供给系统。它不仅告诉模型“你能做什么”(Tools),还告诉它“你能参考什么”(Resources)以及“你应该如何思考”(Prompts)。
4、MCP工作流实例:一次订票查询
让我们通过一个具体的例子,看看MCP如何在一次订票查询中工作:
1.启动与发现:一个旅行助手Agent(MCP Client)启动,它连接到“航空公司MCP服务器”。它首先请求/mcp/v1/tools,获得了该服务器提供的能力清单,其中包含一个名为search_flights的Tool。
2.用户输入:用户说:“帮我查下明天从SFO到JFK的航班。”
3.上下文构建与模型调用:Agent将search_flights的接口Schema和用户的请求一起放入Prompt,调用LLM。

模型生成调用意图:LLM理解了任务,并生成了一个结构化的JSON对象,表示它希望调用search_flights工具。

1.客户端执行调用:Agent(Client)解析这个JSON,并向“航空公司MCP服务器”的/mcp/v1/tools/search_flights端点发起一个POST请求,请求体就是上述JSON中的parameters部分。
2.服务器执行并返回:MCP服务器收到请求,执行其内部的航班查询逻辑,并将结果以JSON格式返回。
3.最终生成:Agent将服务器返回的航班信息,连同原始问题,再次提供给LLM,让其生成一段自然语言的回答给用户。
5、最佳实践:基于官方文档的MCP Server和Client实现
为了更具体地理解MCP,本节将基于MCP官方文档提供的代码示例,展示如何构建MCP Server和Client。
以下代码来自MCP官方文档
(https://modelcontextprotocol.io/docs/develop/build-server),展示了如何使用FastMCP框架构建一个提供天气查询能力的MCP Server:



关键要点:
使用@mcp.tool()装饰器定义工具
使用Python type hints和docstrings自动生成工具定义
对于STDIO-based servers:不要写入stdout,使用logging写入stderr
以下代码来自MCP官方文档
(https://modelcontextprotocol.io/docs/develop/build-client),展示了如何构建一个与MCP Server交互的Client:





官方示例解读:
这个官方示例展示了MCP的核心工作流程:
1.连接服务器:通过STDIO传输连接到MCP Server
2.发现工具:调用session.list_tools()获取可用工具列表
3.调用LLM:将工具定义传给Claude,让它决定是否使用工具
4.执行工具:通过session.call_tool()执行工具调用
5.返回结果:将工具结果返回给LLM生成最终答案
这种架构实现了智能体与能力的彻底解耦,客户端不需要知道工具的具体实现,只需要通过MCP协议与服务器通信即可。
6、MCP的历史定位与争议
尽管MCP的设计理念非常先进,但在2025年底到2026年初,社区中也出现了“MCP已死”(MCP is dead)的讨论。批评者认为,随着各大模型原生Tool Calling能力的增强和长上下文窗口的普及,一个独立的、额外的协议层显得过于复杂和笨重。开发者更倾向于直接使用模型厂商提供的、更简单直接的集成方案。
然而,这种看法可能忽略了MCP的真正价值。MCP的贡献不在于它是否会成为最终的、唯一的行业标准,而在于它首次将“上下文即服务”(Context-as-a-Service)的理念清晰地提了出来。
无论未来具体的协议名称是什么,MCP所倡导的核心思想——通过标准化的客户端-服务器架构解耦智能体与能力——都将是构建可扩展、可维护的复杂AI系统的必由之路。它将上下文管理从一个应用内部的“实现细节”,提升到了一个独立、可治理的“架构层”。
因此,在上下文工程的宏大叙事中,MCP扮演了一个承上启下的关键角色。它为单个智能体提供了一个标准化的“扩展坞”,让智能体能够安全、动态地接入外部世界的能力和知识。而当多个拥有扩展坞的智能体需要互相协作时,我们就需要一个更上层的协议。这,便是我们下一篇文章将要探讨的A2A协议。
以上内容为《大模型上下文工程(Context Engineering)指南》的部分内容节选,完整版指南请扫描下方二维码或点击【阅读原文】下载。
