中国AI创业者重登GTC舞台:杨植麟用技术语言讲了一个智能上限突破的浪漫故事|甲子光年

杨植麟首次完整披露Kimi技术路线图。
作者|王艺
编辑|王博
发自美国圣何塞
美国当地时间3月17日下午,月之暗面(Kimi)创始人杨植麟轻快地走上圣何塞市民大礼堂的舞台,这是英伟达GTC最重要的演讲场馆之一。虽然不少观众慕名而来,但很多人不知道的是,杨植麟是近两年来第一位在GTC官方线下活动中举行演讲的中国大陆AI创业者。
前一天,英伟达创始人兼CEO黄仁勋在GTC主题演讲中曾多次提及Kimi K2.5模型,不过这次,杨植麟很低调,他没有展示任何花哨的产品Demo,没有播放任何激动人心的宣传视频——除了一段展示模型能力的简短录屏外,他几乎全程在讲技术。
优化器的数学原理、注意力机制的并行分块公式、强化学习的奖励函数设计……在AI公司纷纷用炫酷的视频和亮眼的榜单“秀肌肉”的时候,杨植麟反其道而行之,用密集的技术细节告诉在场的每一位听众:开源模型不仅要开放,还必须出色。
模型开源并不难。但是在数据变贵、训练变难、推理变长、任务变复杂的今天,如何把开源模型的“智能密度”继续往上推?
杨植麟的答案,是三个概念:Token Efficiency(Token效率)、Long Context(长上下文)、Agent Swarms(智能体集群)。
1.Token效率:突破智能的天花板

演讲一开始,杨植麟就放出了一张机器学习历史上“最经典的图”——来自DeepMind Chinchilla论文的Scaling Law曲线。横轴是训练所用的token数量,纵轴是模型损失,一条平滑下降的曲线揭示了“投入更多的数据、更大的模型、更多的计算,就能获得更低的损失、更好的智能”的道理。
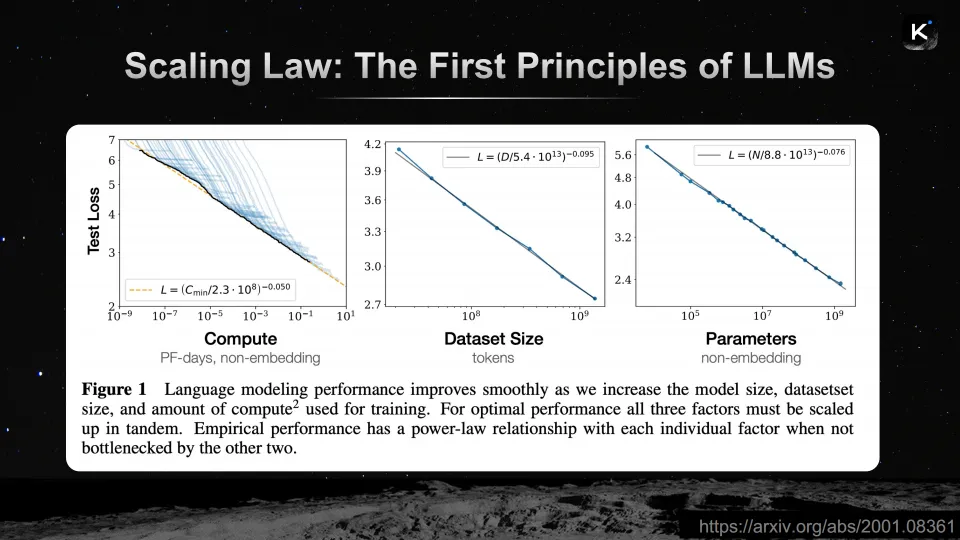
过去几年间,整个行业正是沿着这条曲线一路狂奔,才有了GPT-4、Claude、Gemini等一系列令人惊叹的大模型。
但杨植麟提出了一个不同的视角。
“我们追求的是更好的Token效率,”他说,“Token效率不仅关乎效率,它实际上关乎提高智能的上限。”
在大多数人的理解中,Token效率是一个关于“省钱”和“降成本”的概念,但杨植麟的思路完全不同。他认为,假设全世界可用的高质量训练数据总量是一个常数(比如50万亿token),如果模型优化器能将Token效率提升2倍,那么这50万亿Token就等价于100万亿Token的训练效果——换言之,在数据总量有限的约束下,Token效率的每一次提升,都在直接拓展智能所能达到的极限。
由此,Kimi引入了Muon优化器。Muon是一个二阶优化器,其核心思想是将每个梯度更新进行正交变换,使得更新方向上的各个条目彼此正交。在工程实现层面,Kimi团队开发了分布式Muon优化方案,在数据并行组之间分区优化器状态,使得Muon可以在NVIDIA GPU集群上高效运行,不因内存开销而拖慢训练进度。

在相同参数量和训练Token数量的条件下,仅仅将优化器从Adam替换为Muon,就能在多项基准测试上获得全面提升。杨植麟将这一收益概括为“约2倍的Token效率提升”,也就是说,使用Muon训练的模型,只需一半的数据就能达到Adam训练模型的同等水平。
然而,当Kimi团队将Muon进一步扩展到万亿参数规模时,新的挑战出现了。
“在中等规模的Muon训练中,最大logits迅速爆炸,超过了1000,而典型值应该小于100。同时,训练损失发散,无法收敛。”杨植麟在演讲中描述了这一令人头疼的训练不稳定性问题。
在大模型训练中,logit爆炸是一个经典的工程难题。当模型内部某些数值失控增长时,注意力机制中的softmax运算会变得极端——几乎所有的注意力权重都集中到一个位置上,导致信息流被“堵塞”,进而引发梯度异常和损失发散。
Kimi团队给出的解决方案是QK-Clipping(QK裁剪)技术。其原理并不复杂:对于每个注意力头,在前向传播中实时监控最大logit值,然后计算一个除法因子,应用于键(Key)和查询(Query)投影,将最大值限制在特定范围内,防止数值爆炸。

这个裁剪操作几乎不影响正常训练。杨植麟展示了一组对比实验:有QK-Clip和无QK-Clip的训练损失曲线几乎完全重叠,说明裁剪并未引入额外的信息损失。而在启用MuonClip(Muon + QK-Clip的组合)之后,K2模型的最大logits被稳定控制在100以下,并最终自然衰减。
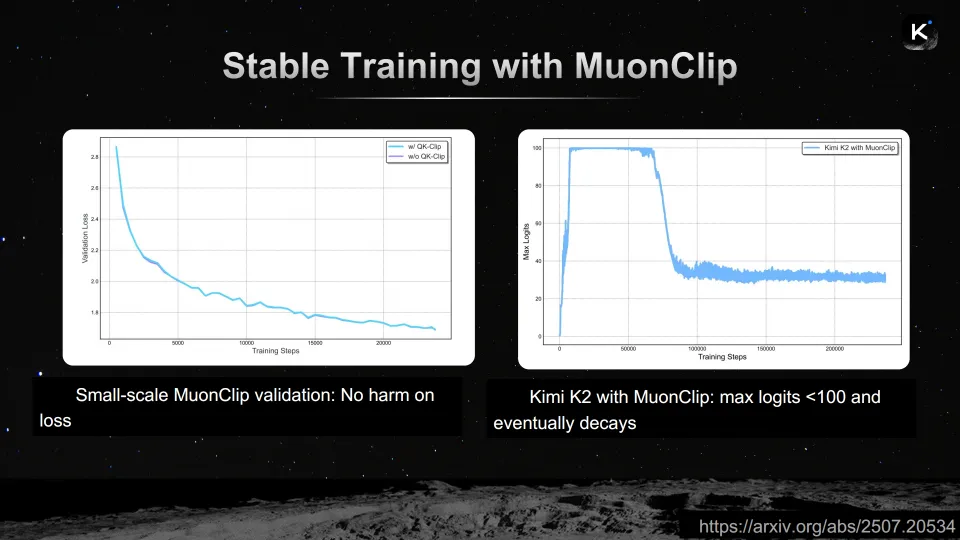
"这是我见过的最美丽的训练曲线之一。"杨植麟流露出感性的一面。
2.长上下文:
从100个Token到一百万个Token

如果说Token效率解决的是“用有限数据达到更高智能”的问题,那么长上下文解决的则是“让智能在更复杂的任务中发挥作用”的问题。
“回到10年前,人们用RNN做机器翻译,但无法理解整个代码库或运行超长智能体轨迹——比如从零编写一个Linux内核,”杨植麟说,“这是智能体时代必需的能力,因为任务越来越难,需要越来越长的上下文。”
但Transformer原生的全注意力机制存在一个根本性限制:其计算复杂度和内存消耗随上下文长度的平方增长。当上下文从4K扩展到128K,计算量增长了1000倍以上;如果进一步扩展到1M(一百万token),全注意力几乎不可能在当前硬件条件下高效运行。
Kimi给出的方案是Kimi Linear架构,其核心组件是Kimi Delta Attention(KDA),一种改进的线性注意力机制。原始线性注意力机制使用单一的全局衰减因子,就像一个简陋的“遗忘开关”——要么忘记一切,要么保留一切。而KDA引入的alpha项是一个对角矩阵,控制每个通道的衰减率。这意味着模型可以同时拥有“慢衰减”通道(保留长程信息,如文档的整体主题或代码的架构设计)和“快衰减”通道(快速刷新信息,如最近几行代码的局部变量),从而大幅增强了线性注意力的表达能力。
这个设计思路类似于人脑的记忆机制:我们的长期记忆和短期记忆并不共享同一套“遗忘速率”——童年的深刻经历可以保留一辈子,而今天早餐吃了什么可能下午就忘了。
KDA用数学的方式实现了这种多层次的记忆结构。在实际部署中,Kimi采用了3:1的混合比例,即75%的层使用KDA线性注意力,25%的层使用标准全局注意力。在短上下文任务MMLU-Pro(4K上下文)上,Kimi Linear达到了84.3分,与全注意力模型持平甚至略优。在长上下文任务RULER(128K上下文)上达到51.0分。而在解码长度达到100万token时,Kimi Linear的输出token时间(TPOT)比当前主流的MLA(Multi-head Latent Attention)架构快6.3倍。
“这是首个在各方面(短上下文、长输入、长输出)都超越全注意力的架构。”杨植麟在演讲现场表示。
3.智能体集群:让AI学会像公司一样协作

如果Token效率和长上下文主要是在“单个模型”层面的优化,那么“智能体群”则将视角抬升到了系统层面。
智能体集群(Agent Swarm)的核心架构并不复杂:有一个编排器(Orchestrator)或主智能体负责接收任务、理解任务结构、分解子任务。编排器可以生成多个子智能体——比如AI研究员、物理研究员、事实核查员、Web开发者等——每个子智能体负责一个特定的子任务。子智能体们并行执行各自的任务,将结果返回给编排器,编排器汇总、评估、必要时发起新一轮分配,如此迭代直到最终任务完成。
杨植麟做了一个类比:“这类似于人类社会——建立一个公司需要不同的角色,需要一个CEO来分解任务并分配给不同的角色,然后整个组织协同工作。”
从概念上,这并不是AI领域第一次提出“多智能体协作”的想法。早在2023年,学术界就出现了AutoGen、CrewAI等多智能体框架。但杨植麟指出了一个关键的区别:之前的多智能体系统大多是基于人工设计的工作流(workflow),依赖人类预先定义好每个智能体的角色和交互规则。而Kimi的智能体群是通过强化学习训练出来的——模型自己学会了如何分解任务、何时生成子智能体、如何聚合结果。
这一范式转换最大的意义在于泛化性:人工设计的工作流只能覆盖预见到的场景,而学习出来的编排能力可以泛化到全新的任务类型。
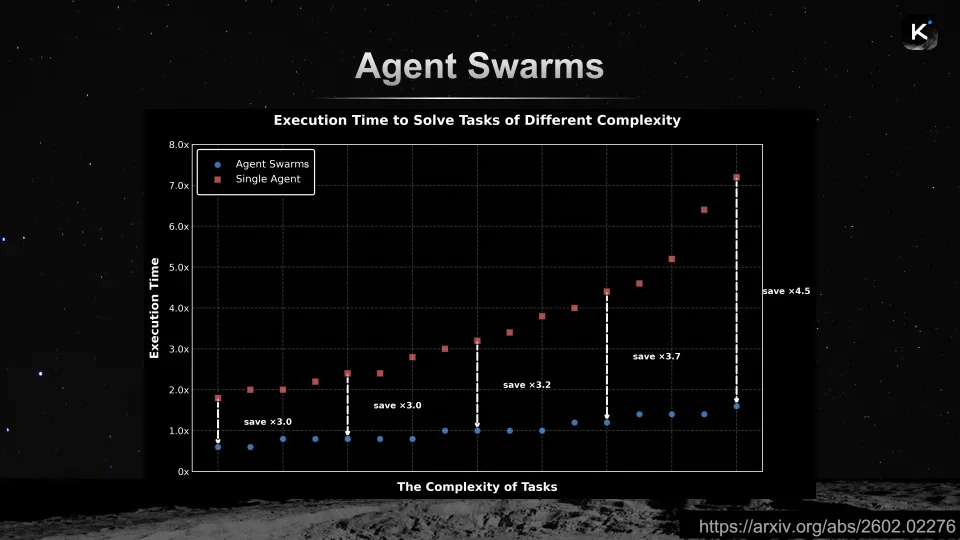
杨植麟展示了一张图表:横轴是任务复杂性(由模型组在该任务上的准确率衡量),纵轴是执行时间。图中清晰地显示,智能体群相比单智能体在执行时间上有大幅缩减,在复杂任务上可以节省4.5倍的时间。杨植麟表示:“如果我们扩展到100甚至1000个智能体,就可以在可容忍的时间内完成极其复杂的任务,产生真正的经济价值。”
从扩展维度来看,智能体集群可以在输入规模、输出规模、行动规模、编排规模四个方向上“拉伸”能力边界;而在训练方法上,杨植麟则介绍了三种精心设计的奖励信号。
第一是实例化奖励。这个奖励信号的存在是为了解决“串行坍缩”的问题——在没有适当激励的情况下,模型可能会学到一个“懒惰策略”:不生成任何子智能体,自己单独完成所有任务。这在简单任务上可能勉强可行,但在复杂任务上会导致性能严重下降。实例化奖励通过正向激励子智能体的生成,防止模型退化为单智能体模式。
第二是完成奖励。这是为了解决另一个对称的问题——“虚假并行”。模型可能学会生成大量子智能体,但这些子智能体并不真正完成有意义的任务,只是做做样子。完成奖励确保每个被生成的子智能体都切实完成了分配给它的子任务。
第三是结果奖励。这是最终的、面向任务目标的奖励信号,衡量智能体集群作为一个整体是否成功完成了最终目标。

三种奖励信号的层次设计体现了Kimi团队对多智能体学习的深入理解。如果只有结果奖励,模型很难学到有效的并行策略——因为在复杂任务中,从随机策略到成功完成目标的信号极其稀疏。实例化奖励和完成奖励提供了中间层次的学习信号,帮助模型逐步学会有效的并行化策略。
将三个维度的创新整合在一起,杨植麟用一段精彩的总结将技术叙事拉回到统一的框架:“这三种维度可以转化为智能体的语言——Token效率关乎更强的先验知识,让智能体能更高效地搜索解决方案;长上下文让智能体能运行数天甚至数周来完成复杂任务;智能体集群则提供了另一个准确性维度。最终,我们将拥有一群智能体,每个都拥有超长上下文和强先验知识,在整个智能体系统中进行搜索。”
4.下一代架构:当Attention旋转90度

如果说前三个部分是Kimi已经兑现的技术成果,那么演讲的最后一个部分则是对未来的一次大胆探索。
2024年的NeurIPS大会上,OpenAI的联合创始人、深度学习领域最具影响力的研究者之一Ilya Sutskever提出了一个引人深思的观察:“LSTM是旋转90度的ResNet。”
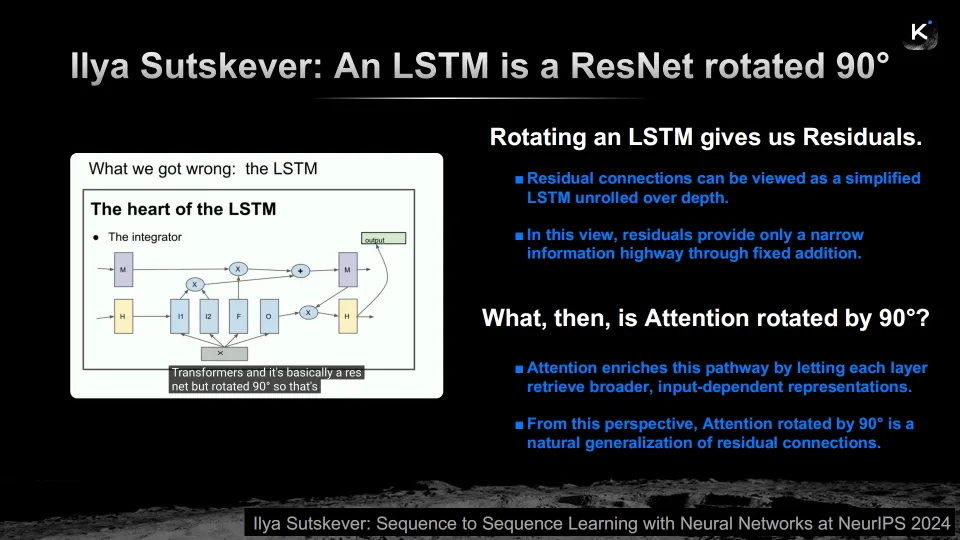
这句话的含义是:残差连接(Residual Connection)可以被视为LSTM在深度方向上的展开。LSTM通过门控机制在时间维度上传递和更新信息,而残差连接通过简单的加法在深度维度上传递信息。两者在本质上解决的是同一个问题——如何在信息的长距离传递中防止衰减和丢失。
但Sutskever的类比也暗示了残差连接的一个局限性:它只是一个“固定加法”操作。每一层的输出被简单地累加到残差流中,没有任何选择性——无论信息是否有用,都被一视同仁地保留下来。这就像一条只能“往前走”的单行道,信息可以不断被添加进来,但无法被有选择性地过滤或重组。
杨植麟由此提出了一个自然而深刻的问题:“那么,Attention旋转90度是什么?”
如果Attention在序列维度上的作用是:让模型根据当前输入,有选择性地检索和聚合之前的信息——那么将这个机制“旋转90度”应用到深度维度上,就意味着:让每一层根据当前的计算需求,有选择性地检索和聚合之前各层的输出。
这就是Attention Residuals(注意力残差)。
在标准的Transformer中,第L层的输入是前面所有层输出的简单累加。而在Attention Residuals中,第L层通过一个softmax注意力机制,对之前所有层的输出进行加权聚合——权重是学习得到的、依赖于输入的。这意味着模型可以根据当前token的具体需求,选择性地“回溯”到最相关的层去提取信息,而不是机械地累加所有层的输出。
这个设计在概念上极其优雅,但在工程上面临一个显而易见的挑战:内存。
在标准Transformer中,残差连接几乎不消耗额外内存——只需保存当前的累加向量即可。而Attention Residuals需要保存所有之前层的输出,以便进行注意力运算,这将每token的内存访问从一个常数级别提升到与层数成正比。
Kimi团队的解决方案是Block Attention Residuals,也就是将模型的层分成若干块(Block),注意力在块内的层之间和跨块之间进行。这将每token的内存访问从O(Ld)(L为总层数,d为隐藏维度)降低到O(Nd)(N为块的大小),在实践中是一个可接受的开销。

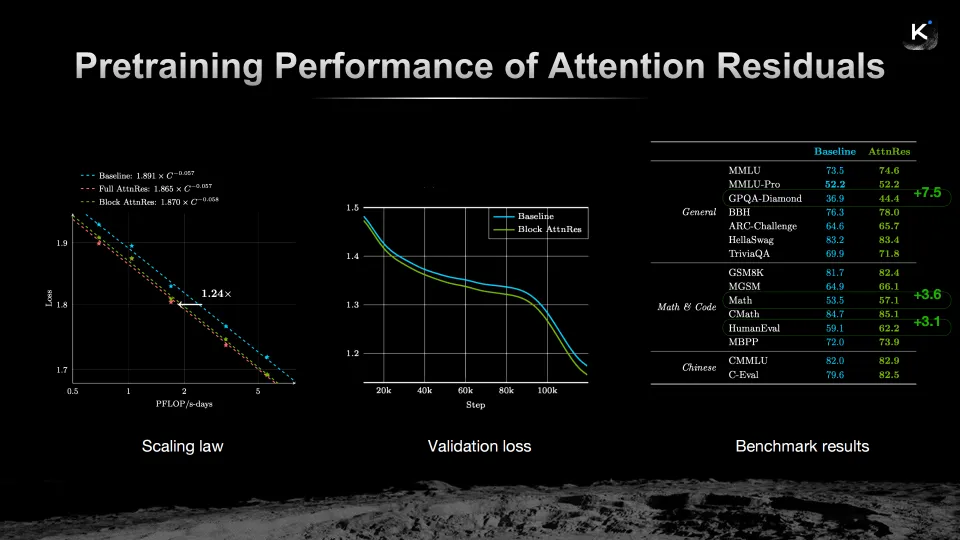
在Scaling Law实验中,Block Attention Residuals架构实现了1.24倍的计算效率提升;在验证损失曲线上,Block Attention Residuals的表现持续优于基线;在MMLU-Pro、GPQA-Diamond、BBH等多项基准测试中,Block Attention Residuals也均有显著提升。
此外,在跨模态研究方面,杨植麟分享了一个重要的观察:原生的视觉-文本联合预训练中,视觉强化学习(Vision RL)能够显著反哺文本性能。消融实验数据显示,经过视觉 RL 训练后,模型在 MMLU-Pro 和 GPQA-Diamond 等纯文本基准测试上的表现提升了约2.1%。这意味着空间推理与视觉逻辑的增强,可以有效转化为更深层的通用认知能力。
5.构建“基础设施”级的开源模型

“Adam优化器发明于11年前,我们扩展并开源了MuonClip。Transformer架构发明于8年前,我们扩展并开源了Kimi Linear。残差连接发明于10年前,我们扩展并开源了Attention Residuals。”
演讲最后,杨植麟给出了三句话总结。而这张PPT,也吸引了大量现场观众拍照。

图片来源:「甲子光年」拍摄

三项技术,分别对应深度学习大厦的三根支柱:优化算法、序列建模架构、深度信息传递机制。它们各自诞生于2015年前后的深度学习的“黄金时代”,至今仍然是几乎所有大模型的核心组件。
而杨植麟在GTC 2026的舞台上宣告,Kimi已经在这三个方向上完成了实质性的创新,并且将这些创新全部开源。
为什么杨植麟要这么做?
AI竞争进入2026年,开源与闭源的博弈已经进入了新阶段。一方面,以OpenAI、Anthropic、Google为代表的闭源阵营继续在模型能力上保持领先,其最新的推理模型在复杂任务上展现出令人瞩目的表现;另一方面,开源社区的追赶速度令人惊叹。
「甲子光年」认为,在这个背景下,Kimi的定位其实非常清晰:做开源阵营的技术先锋。与Meta开源Llama系列模型、阿里开源Qwen系列模型等主要是开源模型权重不同,Kimi开源的是构建更好模型的方法论:更好的优化器、更好的架构、更好的训练技术。这是一种“基础设施级”的开源策略。
从技术影响的角度看,Kimi的三项创新各自面向不同的问题域,但共同指向一个统一的目标:提升开源模型的能力上限。MuonClip通过提升Token效率,让有限的数据产生更多的智能;Kimi Linear通过高效的长上下文处理,让模型能够胜任更复杂的任务;Attention Residuals通过改进深层信息传递,让每一层计算都更有效率。每一项创新,都在为其他创新创造更好的发挥空间。
当然,挑战仍存。Kimi的三项技术创新目前主要通过内部实验和基准测试得到验证,它们在更广泛的社区实践中的表现还有待观察——Muon优化器在不同硬件环境和不同模型规模上的适用性、Kimi Linear在更多样化的任务上的表现、Attention Residuals能否真正走向生产场景……这些都需要时间来回答。
但无论如何,杨植麟在GTC 2026上的这场演讲,传递了一个明确而有力的信号:中国的AI创业公司不仅能够跟随,还能够引领。在深度学习最核心的技术领域——优化算法、模型架构、训练方法——Kimi正在进行实质性的原创探索,并以开源的方式将成果回馈给全球社区。
在演讲的最后一张PPT上,杨植麟再次展示了三条扩展曲线:Token效率维度上不断左移的损失曲线,长上下文维度上不断降低的位置损失,智能体群维度上不断攀升的任务复杂性。三条曲线同时向着“更好”的方向延伸,没有停下来的迹象。
这或许是整场演讲最深刻的隐喻——在AI领域,真正的竞争力不在于此刻你站在哪里,而在于你沿着哪些维度在扩展,以及你扩展的速度有多快。
杨植麟和Kimi选择三个维度同时发力。结果如何,时间会给出答案。
(封面图来源:「甲子光年」拍摄,文中PPT图片来源:月之暗面)
