首个时空时序推理框架:让大模型真正读懂时空数据 | ACL'26

新智元报道
新智元报道
【新智元导读】STReasoner是首个结合时间序列、空间结构和自然语言的推理模型,能识别异常源、追踪影响路径,理解节点间关系并预测未来发展。相比主流预测模型,STReasoner更注重因果与结构推理,且计算成本极低,展现出极强的泛化能力和推理能力。
时间序列广泛存在于现实系统中,例如交通网络、电力系统与疾病传播等。这些系统不仅具有时间动态,还存在复杂的空间依赖关系。传统方法关注的是一件事:把未来数值预测得更准。
但在真实场景中,更重要的问题往往是:哪个节点导致了当前异常? 影响是如何沿空间结构传播的? 不同时间步之间存在怎样的因果关系?
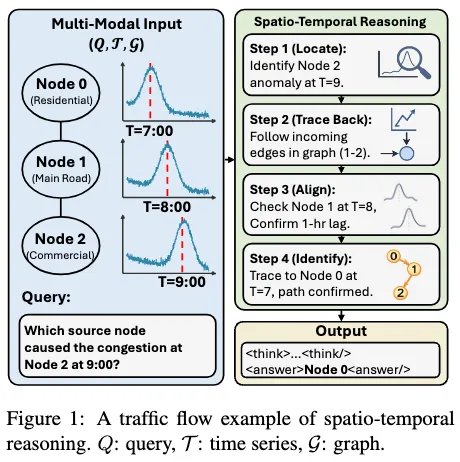
如图1所示,在交通网络中,如果某个区域在9点出现拥堵,我们真正关心的是:「它是从哪里传过来的?」
这类问题不能通过单点预测解决,而需要跨时间与空间进行多步推理:模型首先定位目标节点的异常时刻(时间维度),随后沿图结构回溯潜在影响路径(空间维度),并对齐不同节点之间的传播延迟(时空耦合),最终识别真实的因果源。该过程本质上要求同时整合时间动态、空间依赖与语义查询,进行跨节点、跨时间步的结构化推理。
然而,现有方法主要关注数值预测,难以支持此类复杂决策问题,从而凸显了发展时空时间序列推理能力的必要性。
时空推理发展受限于三个关键问题:
数据问题:缺乏高质量对齐数据,现有数据很少同时包含时间序列、空间结构以及对应的自然语言描述,模型缺乏可以学习「推理」的数据基础。
评估问题:缺乏系统化任务定义,过去没有一个统一框架去系统评估时空推理能力,大多数工作仍然停留在预测任务上。
建模问题:缺乏有效训练机制,如何融合时间序列 + 图 + 文本? 如何避免模型只利用时间模式而忽略空间信息?
来自Emory University、Microsoft、Griffith University等机构的研究团队提出STReasoner——首个面向复杂时空时间序列推理(Spatio-Temporal Reasoning in Time Series)的Time Series LLM框架。实验表明,该模型在因果溯源、空间关系推理与时序预测等任务上实现了显著性能提升,并在真实数据上展现出强泛化能力,同时计算成本仅为闭源模型的0.004×。

论文链接:https://arxiv.org/abs/2601.03248
代码链接:https://github.com/LingFengGold/STReasoner
为系统性地支持时空推理模型的训练与评估,研究人员首先构建了一套可控的数据生成框架,并在此基础上提出统一评测基准 ST-Bench。
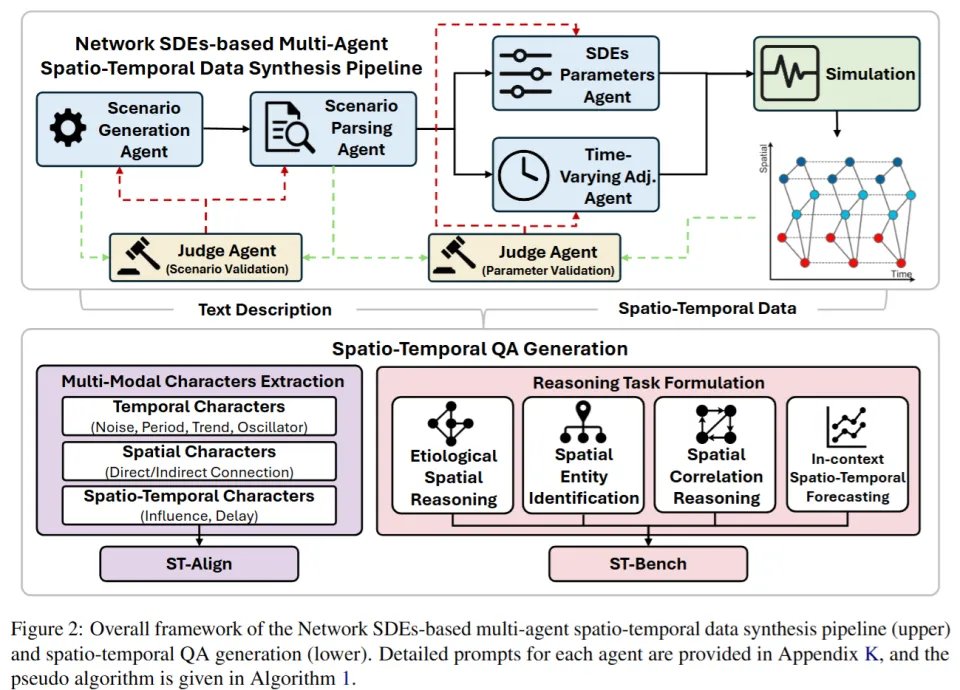
如图所示,研究人员设计了一套 Network SDE + Multi-Agent系统,专门用于生成三种严格对齐的数据:
时间序列(系统如何随时间变化)
图结构(节点之间如何相互影响)
自然语言描述(这些变化「意味着什么」)
整个流程可以理解为:先定义世界,再生成数据,再检查是否合理。
先定义一个完整场景,例如一个交通系统,明确节点、连接关系以及时间动态;
Scenario Generation Agent:生成一个完整场景(例如交通系统、传播过程)
Scenario Parsing Agent:把这个场景拆解成结构化信息(节点、连接关系、时间模式等)
再通过SDE建模每个节点的变化,同时引入空间依赖和传播延迟;
SDE Parameters Agent:为每个节点设定时间动态(趋势、噪声、周期等)
Time-Varying Adjacency Agent:为节点之间的连接设定影响强度,方向 ,传播延迟 。
最终,这些信息被写入Simulation模块中,用来生成真实的时空时间序列。为了避免「数据对了但语义不对」,作者引入了两个 Judge:
Scenario Judge:检查场景本身是否合理
Parameter Judge:检查生成的数据是否真的符合场景描述
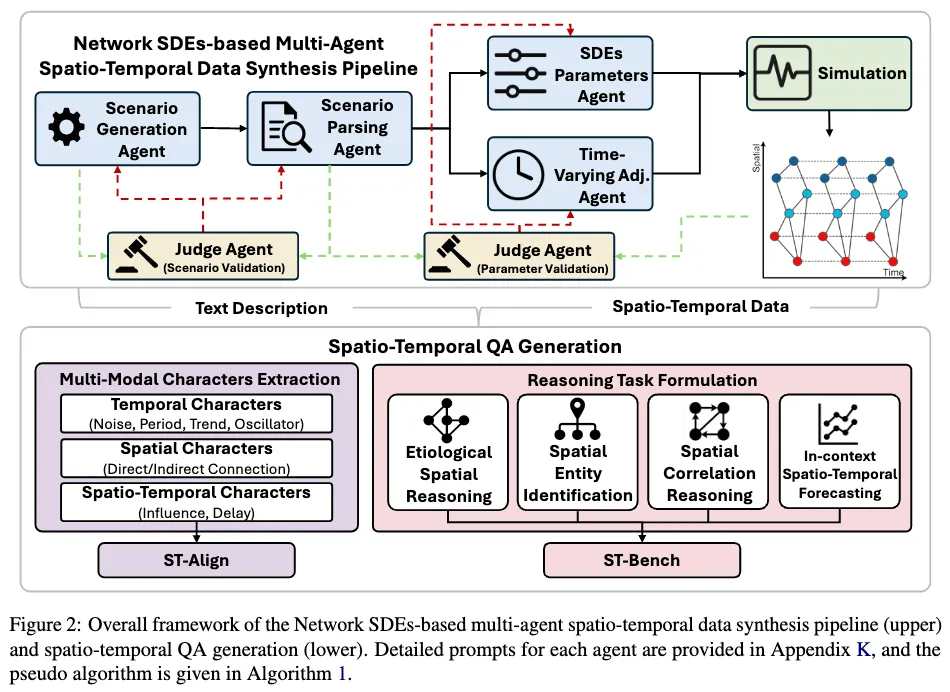
如图所示,在有了高质量数据之后,作者进一步构建了统一基准 ST-Bench,把时空推理拆成四类任务:
T1:因果溯源 → 谁导致了当前现象?
T2:实体识别 → 每个节点扮演什么角色?
T3:相关性推理 → 节点之间如何影响、如何传播?
T4:时空预测 → 在这些关系下未来会怎样?
这四类任务刚好覆盖了一条完整链路:理解结构 → 推断关系 → 解释原因 → 预测未来
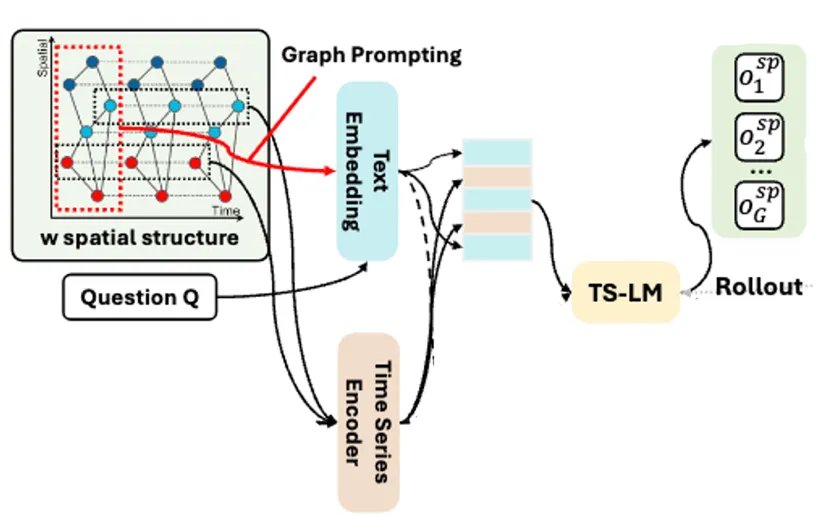
在时空推理任务中,模型需要同时处理三类信息:时间序列、空间结构以及自然语言问题。因此,一个核心问题是:如何让语言模型既「看懂时序数值」,又「理解图结构」,还能完成推理?
STReasoner的设计思路很直接:把时间序列编码成向量(Time Series Encoder),把图结构写成文本(Graph Prompting),连同问题一起交给语言模型处理。
STReasoner采用三阶段训练策略:
Stage 1:模态对齐(Align):这一阶段主要利用自动生成的基础问答数据(ST-Align),学习时间序列、图结构与文本之间的对应关系,例如趋势识别、节点关系理解等。
Stage 2:推理能力注入(SFT + CoT):在这一阶段,作者通过reject sampling筛选出Claude-4.5-Sonnat推理正确的样本,构建 CoT 数据,对模型进行监督微调。
Stage 3:强化学习(S-GRPO)
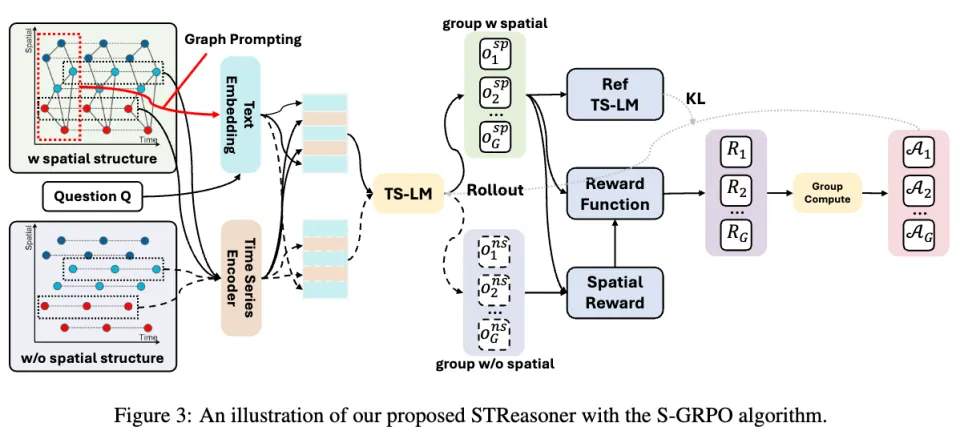
这一阶段通过强化学习进一步提成模型推理能力,强化学习采用空间感知奖励机制(S-GRPO),核心机制是:对同一个问题构造两种输入:
w/ spatial(带图结构)
w/o spatial(去掉图结构)
只有当模型在「有结构」的情况下表现更好时,才给予额外奖励:
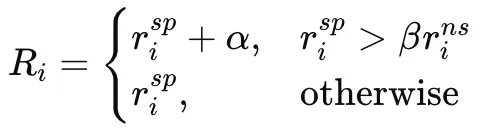
这一机制直接推动模型真正依赖空间结构,而不是只看时间模式。
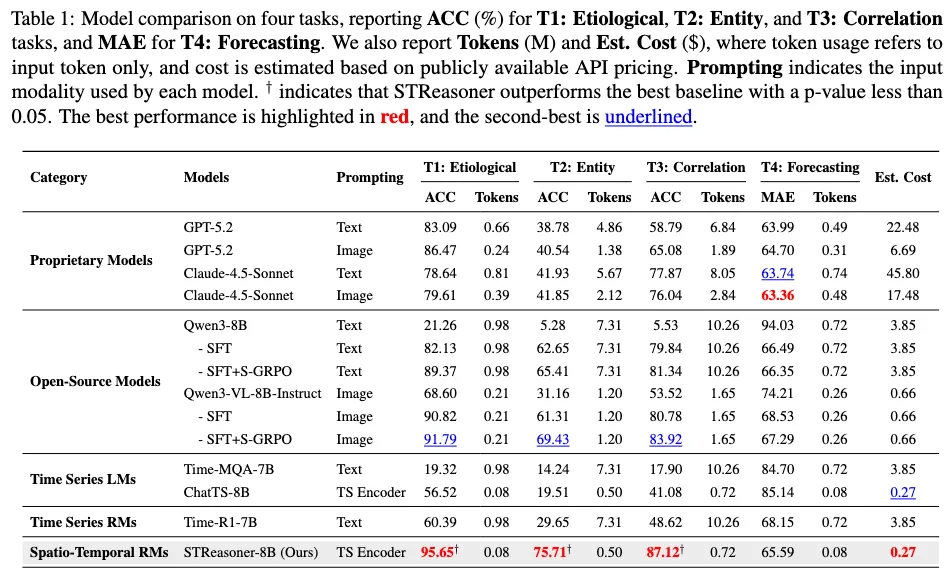
从整体结果来看,STReasoner在不同类型任务上的表现呈现出非常一致的优势。
在强调因果与结构推理的T1(因果溯源)、T2(实体识别)以及T3(空间相关性推理) 三类任务上,模型均显著优于现有开源方法,并在多项指标上超过对比的大模型,说明其确实学到了基于时空结构的推理能力,而不仅仅是模式拟合。
相比之下,在更偏数值预测的T4(时空预测) 任务上,STReasoner的表现与闭源大模型基本持平,仅存在较小差距,体现了其在保持推理能力的同时并未牺牲预测精度。
更重要的是,这些性能是在极低成本下实现的:整体推理开销仅约为闭源模型的0.004×,在成本与性能之间取得了非常有竞争力的平衡。
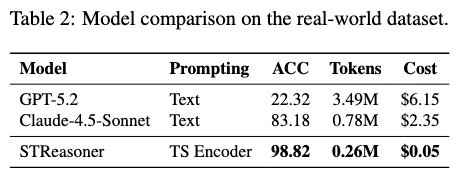
为了验证模型是否真的「学会了推理」,而不是仅仅适配合成数据,作者在真实世界数据上进行了严格的零样本测试(不进行任何微调)。 这一对比有两个值得注意的点:
首先,STReasoner在真实数据上的表现不仅没有下降,反而显著领先,这说明模型学到的不是数据分布本身,而是可迁移的时空推理能力。
其次,更关键的是训练数据来源,STReasoner完全基于合成数据训练,但在真实场景中依然能够准确识别因果关系,这表明前面设计的 「SDE + 多Agent」 数据生成机制确实成功构建了具有泛化价值的训练分布。
模型不是记住了数据,而是学会了如何在时空结构中进行推理。
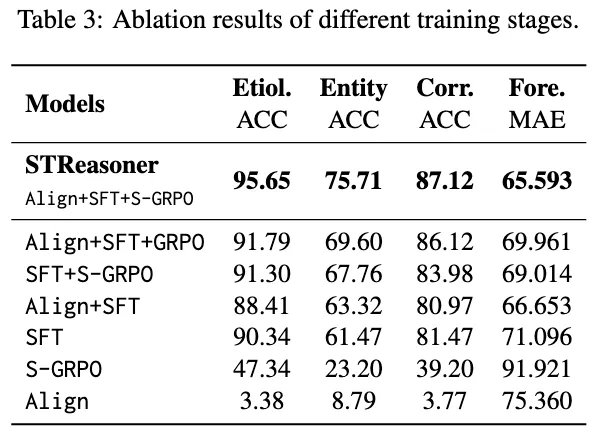
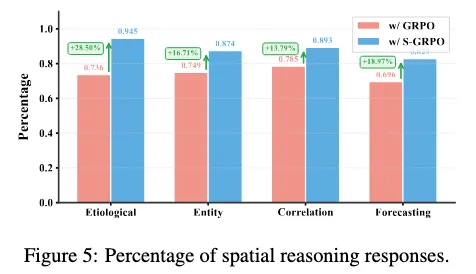
从Table 3和Figure 5可以看出,性能提升主要来自三个关键设计:
时间序列编码器:保证时序信息无损,相比纯文本或图像输入,显式编码器同时保留数值信息和整体形态,是后续推理的基础。
三阶段训练:能力是「逐步建立」的:Table 3显示,缺少任何一个阶段性能都会明显下降:
仅 Align 或仅 SFT → 推理能力不足
直接 RL → 效果不稳定
只有 Align + SFT + S-GRPO 组合,才能达到最优结果。
S-GRPO:让模型真正「用结构推理」
Figure 5显示,引入 S-GRPO 后,模型使用空间信息的比例显著提升。关键不只是更高准确率,而是:模型从「可能不用结构」 → 「主动依赖结构」
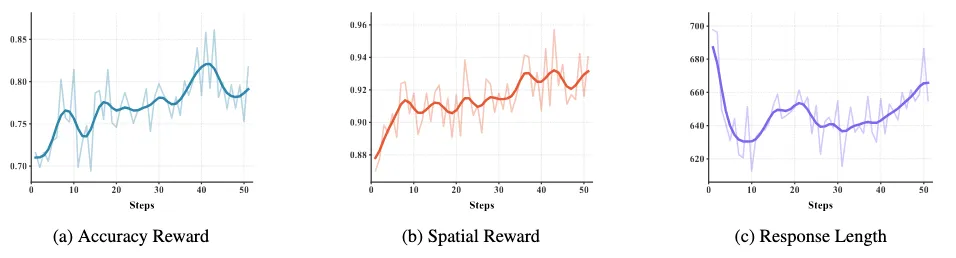
从上图可以看到,强化学习阶段呈现出比较典型的收敛过程:
准确率(Accuracy Reward)整体稳步上升,说明模型在不断修正推理路径,而不是依赖初始的SFT模式。
空间奖励(Spatial Reward)同步提升且趋势更稳定,表明模型逐渐学会在推理中显式利用图结构,而不是仅依赖时间模式。
推理长度(Response Length)呈现「先降后升」,初期长度下降,说明模型在摆脱冗余或无效的推理步骤;后期再次上升并趋于稳定,反映出模型形成了更有结构的推理过程,而不是简单缩短输出。
STReasoner可以看作是时空时间序列推理领域的一次关键起点:它首次将时间序列、空间结构与语言模型统一起来,系统性地建模「为什么发生」和「如何传播」的问题,而不仅是预测数值本身。
相比以往方法只关注曲线拟合,STReasoner把建模目标提升到了结构化推理与因果理解。这意味着时间序列建模正在从「预测未来的工具」,走向「理解复杂系统的模型」,也为后续工作提供了一条清晰的方向。