全网热议的GPT image 2平替?不止是信息图,它让连续的图文创作一步到位

邮箱|dongdaoli@pingwest.com
不知道最近你们的朋友圈里,有没有突然出现很多好看的信息图,排版干净,文字清晰,图标对齐,放进 PPT 直接能用。
不是你们的朋友艺术细胞爆炸了,而是 OpenAI 新模型的功劳。有设计师在 X 上问:“我还有存在的必要吗?”,评论区不语一味地发图。
引起如此高的热度,是因为 AI 生图终于过了一道门槛。
过去几年,生图模型最大的硬伤不是画不好,是写不好。图里但凡出现文字,不是缺笔少画就是乱码,信息图这种文字密度高的内容根本没法用。更麻烦的是角色一致性,同一张信息图里反复出现的图标、人物、配色,生成一次一个样,根本无法量产。
这两个问题,随着GPT Images 2.0出生,基本都解决了。文字渲染准了,风格能保持住,复杂排版也能跟着指令走。
但它的API 按量计费,用量一大账单很吓人。国内访问也有门槛,团队要想把它接进工作流,几乎是不可能的。
解决方案有吗?有的。商汤带来了 SenseNova U1 系列。
像是抛下重磅炸弹,U1一发布就全网讨论度飙升,它不但像GPT Image 2.0一样能做信息图,而且还免费、还开源。

1
SenseNova U1 连图带字的思考
SenseNova U1 系列,是商汤发布的采用全新架构的多模态模型。它不是单纯的图像生成模型,而是把图文理解、图文推理和图文生成放进同一套架构里处理。
这也是它发布时反复强调的关键词:原生统一。
过去很多多模态模型,大致是几块东西拼起来的:语言模型负责理解和推理,视觉编码器负责把图片转成模型能读懂的表示,图像生成部分再把结果转回像素。
这样当然能用,而且现在不少主流产品都是这么做的。但问题也很明显:理解是理解,生成是生成,中间需要不断做模态转换。
U1 的思路更激进一点,基于商汤的 NEO-Unify,去掉传统的视觉编码器 VE 和图像生成里常见的 VAE,让模型直接从原始像素和文字里学习。文字和图像不再被看作两套东西,而是在同一个模型逻辑里被处理。
这次开源的是 SenseNova U1 Lite 系列,包含8B-MoT和A3B-MoT两个版本。
从定位上看,U1 Lite 并不是要和最大规模的闭源模型硬拼参数,而是想做一个“够强、够轻、能开源、能接进工作流”的多模态模型。
跑分上,SenseNova U1 Lite 均达到同量级开源模型 SOTA 水平。
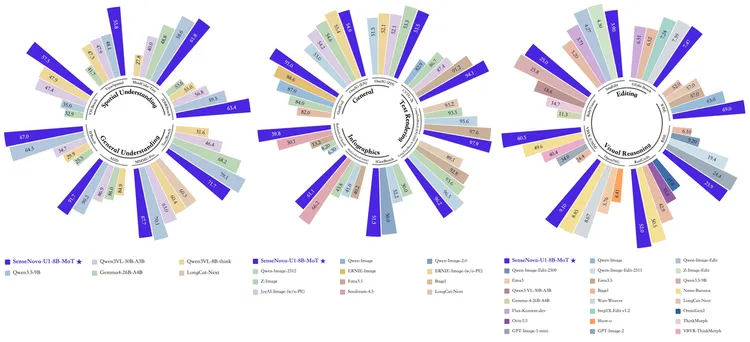
图像理解、图像生成、视觉推理基准测试结果
抛开跑分,它有两个最值得关注的能力。
一个是连续图文创作输出。
这也是最能体现U1这个模型的原生统一架构特征的。不是简单“先写一段话,再配一张图”。传统图文内容生成,很多时候是文本模型先完成文案,再把其中某些段落交给图像模型生成插图。U1 是在一个模型内部完成文字和图像的连续生成,这属于是行业首创。
另一个是高密度信息的处理,常见的就是信息图。
这也是GPT Images 2.0 最为人称赞的。信息图不是简单生一张好看的图,它要求模型同时处理文字结构、视觉层级、版式布局、图标关系和信息密度。以前 AI 画图最容易翻车的地方,恰好就是文字渲染和排版。
1
一手实测 SenseNova U1
就在刚刚,SenseNova U1 已经上线到办公小浣熊,通过点击首页上的【一图读懂】功能,就可以免费体验SenseNova U1的最新能力。
高密度的信息图
我们也在U1接入办公小浣熊的第一时间,进行了实测。
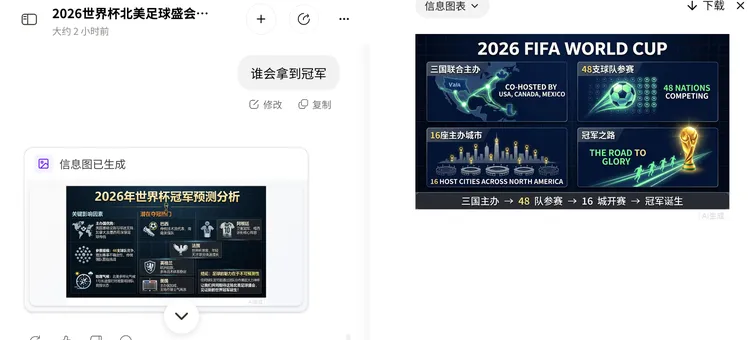
当你需要生成一张2026 年世界杯的信息图海报,用作公众号文章配图。

Prompt:
生成一张中文信息图海报,主题为:“2026 年世界杯:北美足球盛会”整体风格:深蓝色科技感体育海报,搭配荧光绿、金色和白色高光。画面要有足球、球场灯光、北美地图、城市节点、航线、赛程表和观众灯海。整体清晰、有冲击力,适合公众号文章配图。顶部大标题:“2026 年世界杯:北美足球盛会”副标题:“48 支球队,3 个主办国,16 座城市”画面分成四个主要模块,不要太复杂,信息清楚即可。模块一:三国联合主办 位置:左上 视觉元素:北美地图,美国、加拿大、墨西哥三个国家用发光线条连接。 文字: “2026 年世界杯将由美国、加拿大、墨西哥联合举办,这是世界杯首次由三个国家共同承办。”模块二:48 支球队参赛 位置:右上 视觉元素:一个足球放在中心,周围环绕 48 个小圆点或球衣图标,表现参赛队伍扩容。 文字: “本届世界杯参赛球队扩展到 48 支,更多国家将登上世界足球最高舞台。”模块三:16 座主办城市 位置:左下 视觉元素:城市天际线、体育场、发光坐标点,表现多城市承办。 文字: “比赛将在 16 座主办城市举行,赛事将连接球场、城市、球迷和转播网络。”模块四:冠军之路 位置:右下 视觉元素:一条发光赛程路径通向金色奖杯轮廓,周围有球员剪影和观众灯光。 文字: “更长赛程、更大规模、更复杂的旅行距离,将考验每支球队的阵容深度与稳定性。”底部放一条简单流程线:“三国主办 → 48 队参赛 → 16 城开赛 → 冠军诞生”
整体完成度较高,符合体育海报要求,深蓝科技感、球场灯光、荧光绿线条、金色奖杯等视觉元素风格统一。四宫格结构清晰,有视觉冲击力,符合公众号文章配图要求。
图片生成后,办公小浣熊还能帮你预测一波哪支球队晋级,继续生成信息图。
我们再测试一张风格更精致的信息图,做一个仿美食杂志风格的高端酒吧菜单设计。

Prompt:
生成一张高级感、现代极简的 Espresso Martini 中文信息图。画面中心是一杯装在浅碟香槟杯中的浓缩咖啡马提尼,非俯视图,微倾角度。酒液呈深浓缩咖啡棕色,顶部有厚实细腻的咖啡脂泡沫,表面放置三颗咖啡豆。玻璃杯有细微冷凝水珠和高光反射,质感真实精致。围绕酒杯做干净的信息图排版。左侧是“配料”,右侧是“步骤”,顶部角落放“信息徽章”。整体层级清晰:主饮品 > 步骤 > 配料 > 数据。配料包括:伏特加 40ml咖啡利口酒 20ml新鲜浓缩咖啡 30ml糖浆 10ml冰块 适量装饰:3 颗咖啡豆步骤包括:将所有液体与冰块加入摇酒壶充分摇匀至起泡双重过滤倒入浅碟香槟杯用三颗咖啡豆装饰信息徽章包括:酒精度约 18%准备时间 5 分钟风味:浓郁、微甜、咖啡香杯型:浅碟香槟杯风格要求:美食杂志排版 + 高端鸡尾酒酒吧菜单设计,写实酒吧摄影与极简矢量信息图结合。色调以深咖啡棕、奶油米色、温暖中性色为主。柔和影棚灯光,留白充足,现代无衬线字体,毛玻璃面板,柔和阴影,高级、艺术、干净。
这次生成的主杯质感明显更好:泡沫层次、深棕色酒液、玻璃高光都有“高端酒单”的质感,整体色调也对——奶油米色背景配深咖啡棕。围绕酒杯做干净的信息图排版,视觉上更接近美食杂志的风格。
接下来测试一下,如果只给一句话 prompt ,模型是如何自由发挥能力的。
Prompt:
做一张漫画风格的,深圳旅游攻略。

基于大模型自身的能力,哪怕你的提示词简单,依然能生成好用的信息图。
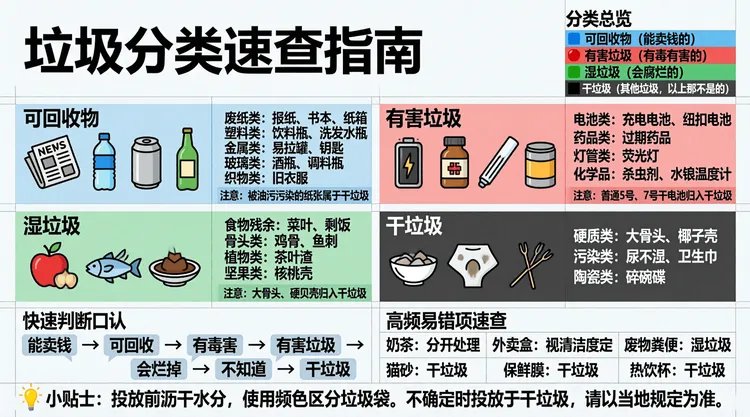
我们还发现,它还可以基于对长文档、数据图表等的数据分析结果,生成高质量的信息图。
Prompt:
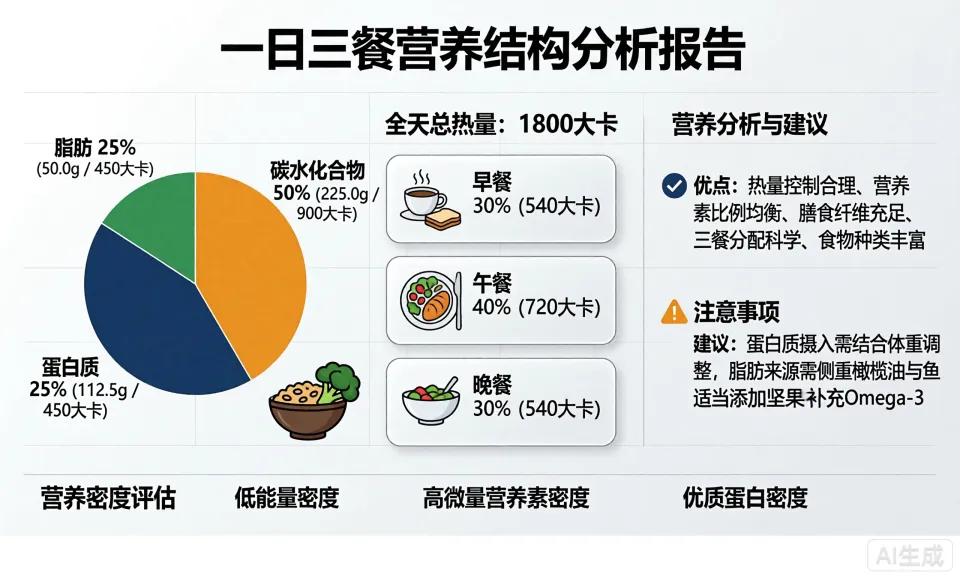
Prompt:
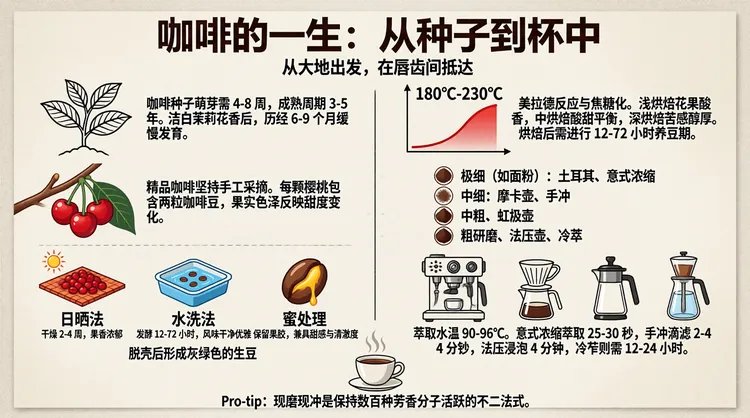
Prompt:
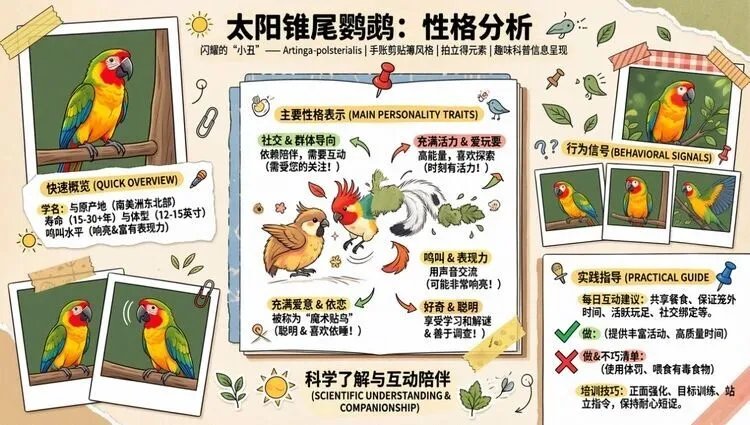
类似的图还有很多玩法,比如教小朋友分辨鹦鹉性格。
给科普文章配图,拆解。 VR头显是如何组成的等。
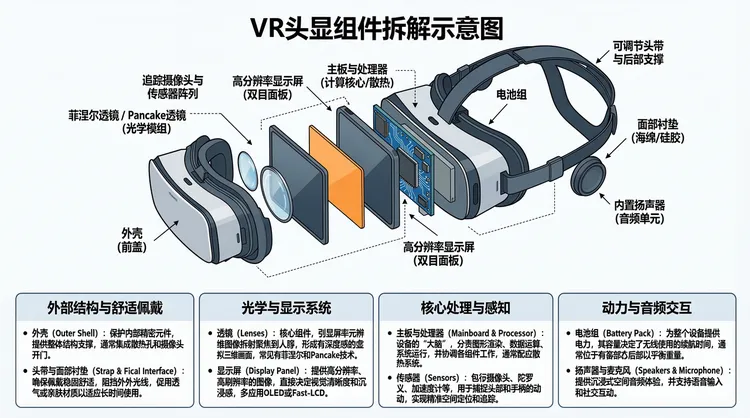
连续图文创作输出
接下来,我们体验了SenseNova U1的另一个亮点能力——连续图文创作输出。
我们制作菜谱教程时候,以往还需要编辑点文字凑凑数,现在可以用SenseNova U1一步搞定,并且可以保持很好的一致性。
Prompt:

除了有教程逻辑外,SenseNova U1还能生成不同摄影风格的图文讲解。
Prompt:

文章配图工作流
我们还尝试了将SenseNova U1 Skill加入办公智能体的工作流。
随着 OpenClaw 等 Agent 的普及,出现了越来越多自动化工作流,比如自动回答用户提问、根据儿童需求生成绘本等。以往这类流程需要先调用大模型处理文章内容,再生成适合生图的提示词;现在只需调用 SenseNova U1 Lite 的 skill,即可完成配图。
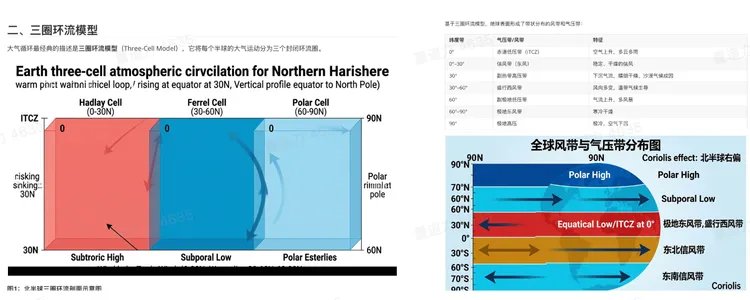
以完成一篇大气循环科普文章为例:

可以看到,无需过多干预,OpenClaw 会自动调用 skill,在合适的位置插入对应的信息图。

效果对比也很明显:以往给文章配图,OpenClaw 通常会调用 Python 画图库生成较为简陋的示意图。接入 SenseNova U1 Lite 的 skill 后,OpenClaw 具备了在合适位置自动插入信息图的能力,大幅减少了用户的手动操作和复杂工作流的编写成本。
1
SenseNova U1 的架构做了什么
U1 系列值得关注的地方,其实不只它会生成信息图,而是它把"看图、理解、推理、生成"统一放进了同一套架构里。
过去的多模态模型更像拼装系统:语言模型负责推理,视觉编码器负责感知,图像生成模块负责输出。每一块都能用,但理解和生成之间始终隔着模态转换,做信息图、图文混排时,容易出现文字不稳、布局混乱、图文关系割裂的问题。
U1 背后的 NEO-Unify 要解决的就是这种割裂。它去掉了传统视觉编码器VE和变分自编码器VAE,以统一表征取而代之,在保留语义丰富性的同时维持像素级视觉保真度。语言与视觉信息不再被分开处理,而是作为一个统一的复合体被直接建模。
这带来了一个关键结果:理解能力和生成能力可以同步增强,而不是此消彼长。
这意味着,图像不只是最后被“画出来”的结果,也可以参与模型的推理过程。所以它能做真正的连续的图文创作输出——在同一个生成过程中,文字输出和图片插入交替进行。做信息图时,它也不只是画得漂亮,而是要理解标题、模块、图标、流程线与信息密度之间的关系。
尤其对内容行业,这一点尤为关键。公众号配图、PPT、产品说明、教程图、商业分析图,很多都不是纯粹的审美问题,而是信息组织问题。SenseNova U1把 AI 生图向“可视化表达工具”又推进了一步。
体验方式:
办公小浣熊:https://office.xiaohuanxiong.com/home
其他测试和体验渠道还包括:
GitHub:https://github.com/OpenSenseNova/SenseNova-U1
Hugging Face:https://huggingface.co/collections/sensenova/SenseNova-U1
调用 SenseNova U1 Skill https://github.com/OpenSenseNova/SenseNova-Skills