突破长序列与低耗部署核心瓶颈!中国科学院发布类脑大模型瞬悉2.0

新智元报道
新智元报道
【新智元导读】中国科学院团队推出类脑大模型「瞬悉2.0」,通过优化架构与编码路径,显著提升了长序列处理效率与低功耗部署能力。该模型在保持高性能的同时,大幅降低训练与推理成本,为人工智能轻量化与多模态应用开辟新方向。
随着大模型上下文长度的快速扩展,代码仓库理解、智能体以及多模态交互等场景对模型的长序列处理能力提出了更高要求。
传统Transformer在推理时的计算开销和显存占用随序列长度不断增长,严重制约其实际部署。
近日,中国科学院自动化研究所李国齐、徐波团队在类脑脉冲大模型「瞬悉1.0」研究基础上,针对当前大模型长序列处理与低功耗部署等核心瓶颈,推出SpikingBrain2.0-5B(简称SpB2.0-5B)模型系列。
该系列模型与瞬悉1.0均以类脑机制为核心,在模型架构、训练算法和应用广度上实现全面升级。研究团队已经开源了瞬悉2.0-5B语言模型与瞬悉2.0-VL-5B视觉语言模型。

论文链接:https://arxiv.org/abs/2604.22575
代码链接:https://github.com/BICLab/SpikingBrain2.0
此次发布的瞬悉2.0以超过瞬悉1.0十倍的训练开销节省,训练数据量从瞬悉1.0的150B降低至瞬悉1.0的14B:
即仅需32张A100显卡,9天内即可完成对当前主流Transformer架构大模型(如Qwen3系列模型)的持续预训练,通用知识(如MMLU、ARC-C、BBH等任务)以及SFT后推理能力(如数学推理GSM8K、MATH,代码HumanEval、MBPP等任务)的表现可与强基线Qwen3比肩且实现比瞬悉1.0更优综合性能;
并在4M序列长度下达到主流Transformer模型Qwen3的10.13倍首Token生成加速,FP8量化路径下4M长度下相比Qwen3 BF16基线提速达15.13倍,整数-脉冲化编码路径下,精度损失仅为0.69%,且脉冲稀疏度高达64.3%
模拟结果显示,该方案在测试场景下相比INT8矩阵乘法基线,有望使得面向类脑大模型的神经形态芯片面积减小70.6%,在250/500MHz工作频率下功耗降低48.1%/46.5%。
瞬悉2.0在长序列处理效率、训练开销、综合Benchmark性能、跨硬件平台适配性及应用场景拓展等方面显著提升,为轻量级、多模态高效脉冲基础模型的研发提供了可行路径,为新一代人工智能创新发展注入新动力。
当前,大模型发展正从「参数和数据规模驱动」逐步延展至「上下文能力驱动」。
在智能体、代码理解、长文档分析等应用中,模型需要处理数十万甚至百万级token。
但传统Transformer在长序列处理及资源受限场景下的部署仍面临诸多痛点。因此,如何以极低成本构建基础模型,打破Transformer在不同序列长度、不同硬件平台下的能耗瓶颈,成为大模型领域的关键探索方向。
针对该问题,团队此前发布的瞬悉1.0已率先尝试将类脑机制与高效大模型相结合,为低耗大模型研发提供了初步探索。此次发布的瞬悉2.0通过引入更丰富的类脑机制——包括稀疏化记忆建模、更精细化的脉冲激活值编码等,在瞬悉1.0的基础上实现全方位升级。
短序列场景中,Transformer的计算瓶颈源于大量前馈矩阵乘法;长序列场景中,计算瓶颈则向注意力模块转移,导致推理效率大幅下降。瞬悉2.0因此对注意力和前馈矩阵乘操作分别做出针对性设计,期望缓解Transformer的能耗问题。
(1)双空间混合稀疏注意力
瞬悉2.0提出双空间稀疏注意力(Dual-Space Sparse Attention, DSSA),用于在层间混合稀疏Softmax注意力MoBA与稀疏线性注意力Sparse State Expansion (SSE)。其中,MoBA对完整的KV cache进行块级稀疏计算,SSE则对压缩式状态表征进行稀疏计算。这一设计对应类脑化的稀疏记忆机制,实现了优良的长序列性能-效率权衡。
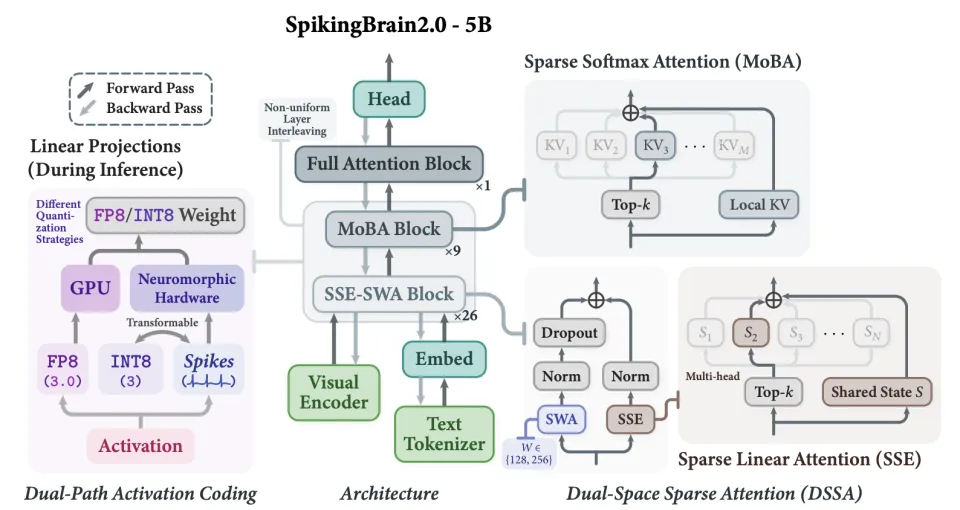
瞬悉2.0架构概览
(2)双路径激活值编码策略
瞬悉2.0采用了包括FP8和INT8-Spiking两种对偶激活值编码路径:
FP8编码路径:利用低比特Tensor Core加速矩阵乘运算,该路径面向工业GPU部署(如NVIDIA Hopper GPU);
INT8-Spiking编码路径:把激活值转为脉冲序列,可将密集矩阵乘法替换为事件驱动的整数累加,大幅降低部署功耗,该路径面向异步神经形态芯片部署。
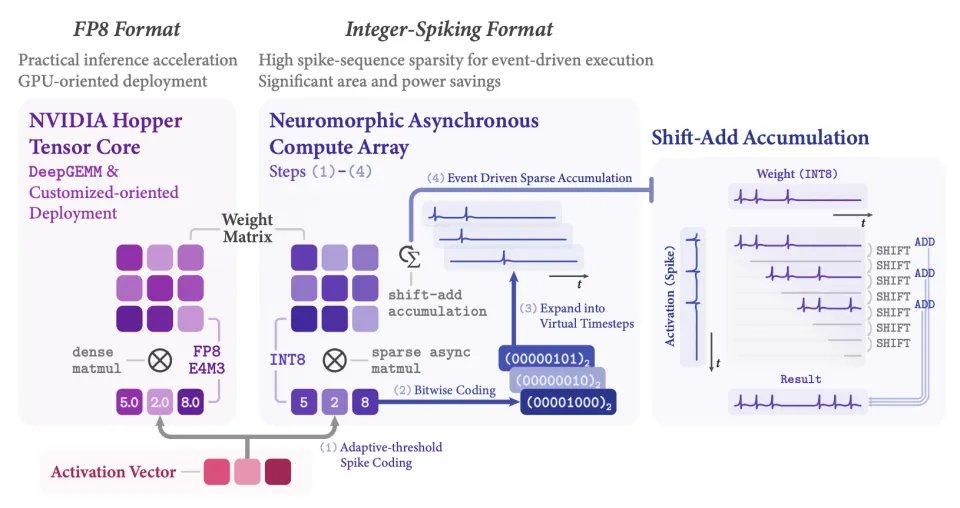
瞬悉2.0对偶编码路径
瞬悉2.0采用比瞬悉1.0更高效、模态更广的架构转换流程(Transformer-to-Hybrid Conversion),依托极少量开源数据和计算资源,分别为语言模型与多模态模型构建两条独立的续训转换路径,大幅降低开发成本。
(1)LLM转换路径:包括短上下文蒸馏、三阶段长上下文扩展(最高至512k)以及两阶段的通用加推理SFT,同时开展了在策略蒸馏探索。
(2)VLM转换路径:包括知识蒸馏与指令微调。本文还同时分享了实践过程中的关键Takeaways,为社区研究提供参考。
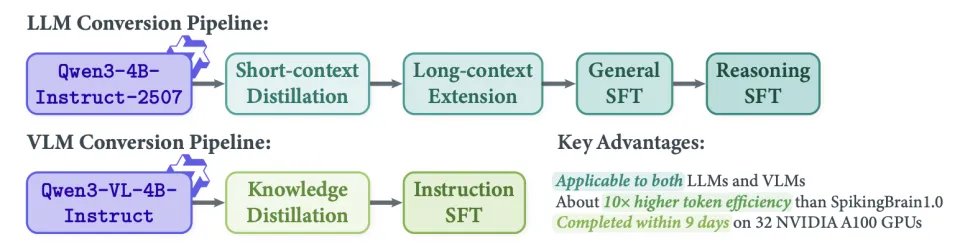
瞬悉2.0转换训练Pipeline
1. 长序列处理效率显著提升
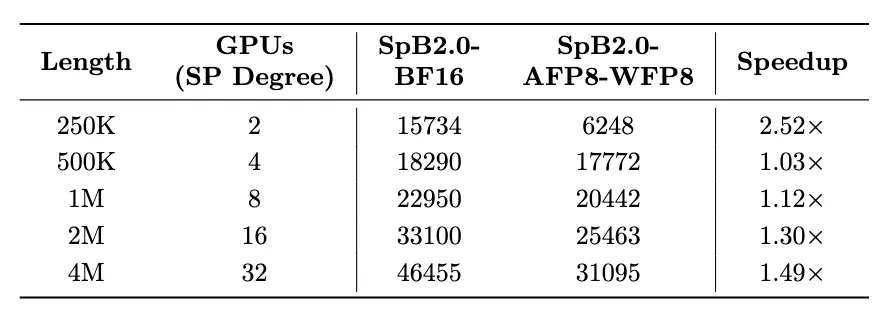
(1)在Huggingface序列并行框架下,瞬悉2.0在4M长度相比Qwen3实现10.13倍的首token生成时延(TTFT)加速(2)在vLLM张量并行框架下,512k长度端到端生成延迟降低4.3倍,128k长度下总吞吐提升1.57倍、请求并发数提升3.17倍;
(3)依托vLLM框架,8卡A100即可支持长达10M序列的推理,而Qwen3基线在4M长度时已超出显存限制,展现出突出的长序列处理优势。
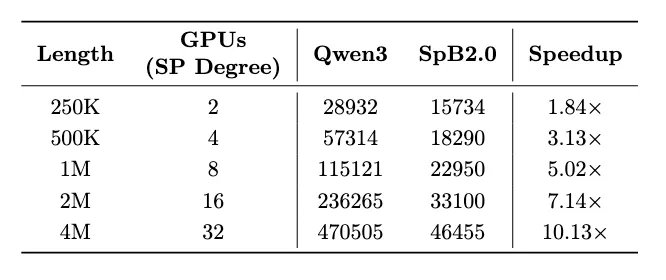
2. 训练成本大幅降低
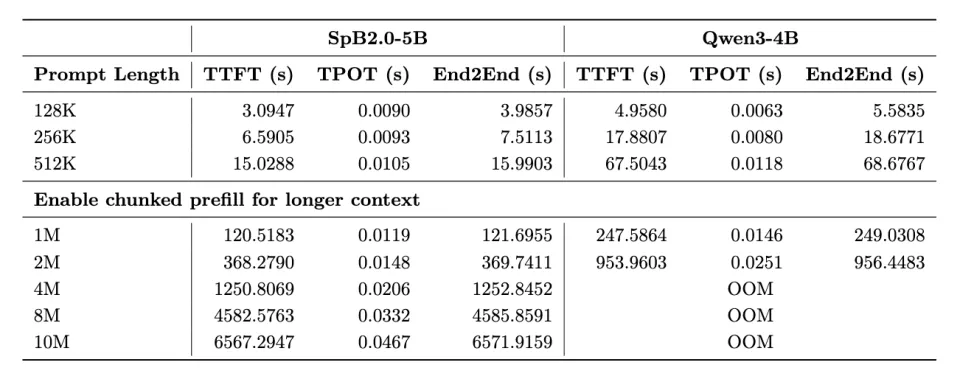
瞬悉2.0-5B语言与多模态模型的总转换开销低至7k A100卡时以下,仅需32张A100,9天内即可完成对Qwen3-4B和Qwen3-VL-4B的全部转换训练,相较于SpB1.0,训练成本减少10倍以上(LLM CPT数据量从150B降至14B),实现了高效低成本的模型开发。
3. 模型性能保持竞争力
(1)瞬悉2.0语言模型在通用知识(如MMLU、ARC-C、BBH等任务)以及SFT后推理能力(如数学推理GSM8K、MATH,代码HumanEval、MBPP等任务)的表现可与强基线Qwen3比肩且实现比瞬悉1.0更优综合性能。
(2)瞬悉2.0-VL模型性能实现对Qwen3-VL的有效恢复,可与强基线Qwen2.5-VL比肩(如图表推理AI2D、通用视觉推理MMStar等任务),在瞬悉1.0的基础上实现了多模态能力的突破。
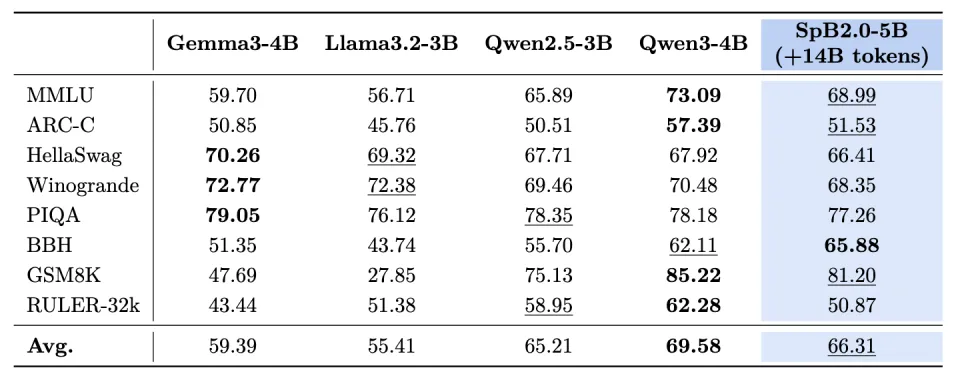
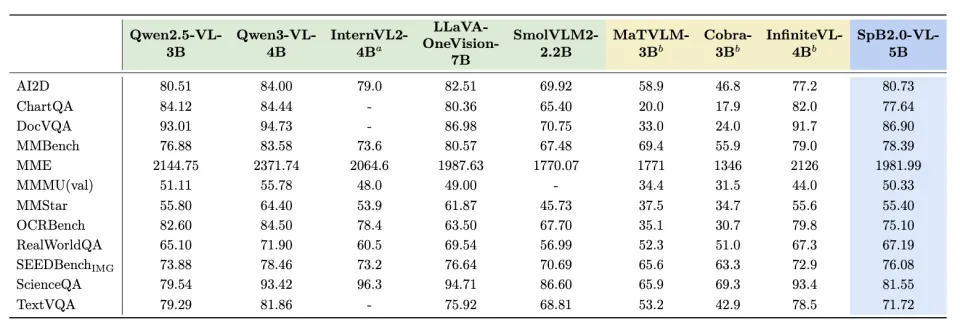
4. 跨硬件平台适配性突出
瞬悉2.0可灵活适配不同硬件平台:
(1)采用FP8路径时,精度损失仅为0.24%;在H100上实测显示,256k序列长度下TTFT提速相比瞬悉2.0 BF16版本超2.5倍,同时在4M长度下相比Qwen3 BF16基线提速达15.13倍;
(2)采用INT8-Spiking路径时,精度损失仅为0.69%,且脉冲稀疏度高达64.3%;后仿模拟结果显示,该方案在测试场景下相比INT8矩阵乘法基线,面积减小70.6%,在250/500MHz工作频率下,功耗降低48.1%/46.5%,有望破解端侧部署的功耗瓶颈。

瞬悉2.0系列模型的发布,为轻量级、多模态高效脉冲基础模型的研发提供了可行路径,进一步验证了类脑机制与高效模型架构结合的广阔前景。
同时,该模型为端侧、资源受限场景的大模型部署提供了高性价比解决方案,也为低功耗神经形态计算的后续研发提供重要参考。研究团队将继续秉承类脑大模型技术「概念一致、迭代升级」的理念,持续研发可比肩主流大模型的低功耗神经形态计算。