端侧 AI 的定义权,面壁智能先拿下了

邮箱|dongdaoli@pingwest.com
刚刚过去的 5 月最后一周,面壁智能做了一件在国内大模型行业颇为罕见的事:办了一场“开源周”,连续密集发布多项开源技术成果。
没有大屏幕,也没有 CEO 的激情演讲,只有一个接一个被推到台前的 GitHub 仓库。
过去三年,中国大模型行业不缺发布会,但真正以“开源周”形式集中释放技术成果的公司并不多。因为这件事的门槛并不低,你不能只有一个爆款模型,还得有一整条能够拆开给外界看的技术链路。
单看清单,面壁这一周发布的内容很容易被理解成一个“模型货架”,这里一个数据集,那里一个训练框架,再加上模型和应用项目。
但如果把它们放到一起看,会发现它们指向的不是几个孤立成果,而是一套正在成形的端侧 AGI 世界底座。
更值得注意的是,这件事发生在一个行业转向节点上。
2023 年,中国大模型公司还在比谁先做出基座模型;2024 年,行业开始卷 API 价格和应用入口;2025 年,端云协同、AI 终端和端侧模型逐渐成为共识;到了 2026 年,真正的问题已经不再是“有没有大模型”,而是这些模型能力如何进入手机、车机、PC、机器人和 AI 眼镜这些真实设备。
谁能把模型能力稳定地放进这些设备,谁才有机会定义下一代 AI 的入口。
面壁的特别之处在于,它不是等到端侧 AI 成为行业共识后才行动,而是在两年前就开始把小参数、高能力、低内存和端侧部署当成主线来押。
1
被误读的端侧 AI
端侧 AI 长期被两种误解包围。
一种说法认为,端侧 AI 就是小模型,把云端模型裁剪一下,参数少一点,能塞进手机、车机就行。另一种说法则认为,端侧 AI 只是云端 API 下放,终端不需要真的跑模型,只要联网调用云端能力。
但真正的端侧模型要面对三道硬约束:功耗、内存和场景。而面壁这次开源周的价值,就是把这些约束背后的工程能力全部公开。
第一道约束是功耗。
云端模型可以用数据中心供电和散热去换性能,终端设备不行。手机要续航,车机要在高温和长时间运行下保持稳定,AI 眼镜要轻薄。
所以端侧模型没有云端大模型那种用海量低质数据摊薄噪声的空间,每一份训练数据的质量都会更直接地影响模型能力。
面壁开源的 UltraData 解决的就是“模型越小,数据越要精”的问题。
UltraData 提出的 L0 到 L4 分级治理体系,本质上是在提高数据密度:L1 做基础清洗,L2 提高信息密度,L3 通过合成与增强强化知识表达和推理能力,L4 面向更高阶的数据编排。
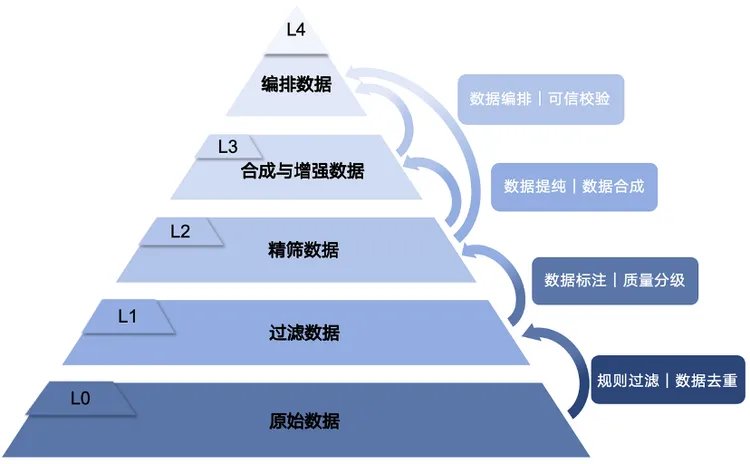
这些数据最终指向的,不是训练一个更大的模型,而是训练一个单位参数智能密度更“高”的模型。
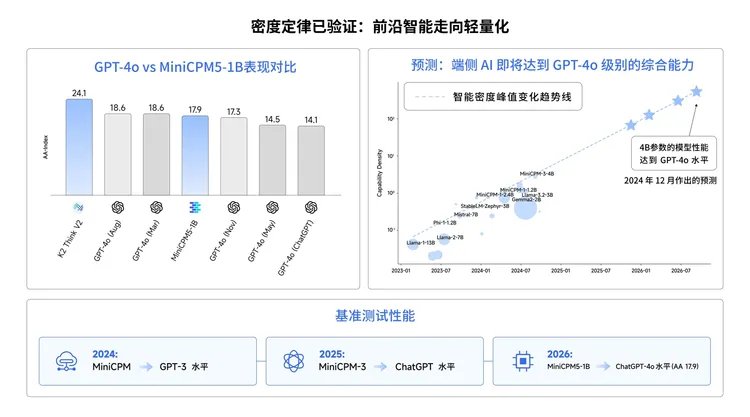
MiniCPM5-1B 证明的,正是这条路线已经可以落地。
面壁智能在 2024 年 12 月曾判断,2026 年会出现端侧 GPT-4o 级别的能力,而从 MiniCPM 到 MiniCPM3,再到 MiniCPM5-1B,端侧模型的演进也确实沿着这条曲线展开:2024 年对标 GPT-3,2025 年追近 ChatGPT,2026 年开始触碰 GPT-4o 部分版本的能力边界。
1B 参数不再是“小而将就”,而是智能密度提升后的结果。端侧模型真正重要的指标,不是参数量有多大,而是单位参数里压进了多少智能。
第二道约束是内存。
端侧推理不是 NPU 算力够就行。模型权重需要内存,KV Cache 需要内存,多模态中间状态也需要内存,内存带宽还会直接影响生成速度。
行业内共识是,端侧 AI 正在被“算力-内存剪刀差”卡住:芯片算力涨得很快,但内存容量、带宽和成本没有同步改善。
面壁智能开源周第一天发布的 BitCPM-CANN,正是面向这道内存约束的技术回应。面壁智能在华为昇腾平台上完成端到端训练,并开源了 1.58-bit 三值大模型,覆盖 0.5B、1B、3B、8B 四个尺寸。
所谓 1.58-bit,不是常规 2bit 量化,而是让每个权重只保留 -1、0、+1 三种状态。
与同尺寸 MiniCPM4 全精度模型相比,BitCPM-CANN 推理阶段只需要约原来 1/6 的显存,相当于节省 5/6 内存,同时保留 90% 到 97.2% 的模型能力。
这意味着,低比特模型可以解决大参数模型上端侧的问题。
2-bit 级压缩可带来约 6 到 8 倍存储收益,4GB 可用内存有机会容纳 16B 级模型,结合 MoE 和激活约束可推到 32B,如果设备内存扩展到主流的 8GB,60B 级的大模型装载到手机端也不是天方夜谭。
第三道约束是场景。
端侧设备要面对断网、弱网、隐私合规、毫秒级响应、多传感器输入。车机不能把每个请求都丢给云,手机里的个人数据不能无限上传,工业终端也常常处在网络不稳定、环境复杂的现场。
更现实的情况是,中国终端芯片生态高度分散。高通、联发科、华为昇腾、寒武纪、地平线等平台的架构和工具链都不一样,适配一款芯片和适配一个生态是两回事。
这也是面壁开源 ForgeTrain 的定位。
它不只是一个训练框架,更像是一套面向端侧模型生产的工程工具。端侧模型很少是“一次训练、到处部署”,不同设备、不同芯片、不同内存规格,都会要求模型在尺寸、精度、训练策略和推理路径上反复调整。一个团队能不能快速把实验结果变成可部署模型,训练框架本身就是关键变量。
ForgeTrain 的特殊之处在于,它是完全由 AI 编写的预训练框架。它在英伟达 H100 上的训练速度比主流 Megatron 快 10%,即使是在华为昇腾平台上,也比华为自己的 MindSpeed 框架快 10%。MiniCPM5-1B 的 Base Model 版本,也由 ForgeTrain 预训练完成。
这件事的意义,不只是“AI 制造 AI”完成闭环,而是训练基础设施的生产权开始发生变化。
过去,大模型训练很大程度上被英伟达的软件栈牵着走:芯片厂商、模型公司想做什么,往往要先看现有框架支不支持。
Forge Engineering 所改变的是,未来不是所有人围着英伟达的软件生态转,而是芯片厂商和大模型公司可以按自己的硬件、模型和训练策略,去“打造”真正需要的软件。想要什么框架,就打造什么框架。这才是“AI 制造 AI”背后更大的叙事。
而 PilotDeck 更像是面壁智能在 Agent 操作层上的一次独立探索。
当端侧模型越来越强,AI 不再只是一个聊天窗口,而是要进入真实工作流时,任务、文件、记忆、工具和权限应该如何被组织起来。
这也能解释面壁智能战略里的两面:一方面,它向端侧深处扎根,解决模型、内存、芯片和工程生产的问题;另一方面,它也在端侧智能之上,探索新的产品形态和 Agent 系统。
大模型行业变化很快,真正能穿越周期的公司,往往要同时抓住“变”与“不变”。不变的是端侧智能会长期存在,变的是它上面会不断长出新的交互方式和操作系统。
所以,端侧大模型的难点不在“把模型做小”,而在于如何在功耗、内存、算力、芯片、系统和应用之间做一整套协同设计。
面壁这次开源周真正释放的信号,不是几个孤立的开源项目,而是建立一套正在成形的端侧 AGI 世界底座。
1
密度战争的面壁胜负手
端侧 AGI 世界底座,听起来很大,落到工程上其实很小。但小不是目的,密度才是。
当大模型行业长期围绕 Scaling Law 竞争时,主流叙事是更大的模型、更大的集群、更长的训练周期。面壁选择的则是另一条路线:在有限算力、有限内存和有限功耗里,让单位参数承载更多智能。
这个想法,被面壁称为“密度定律”。

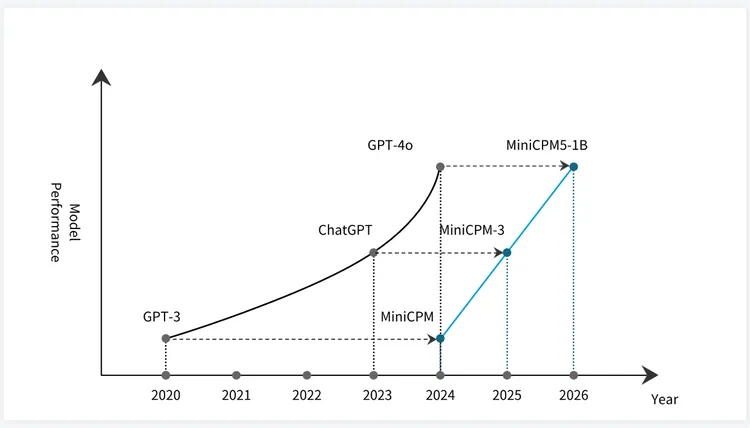
这不是 MiniCPM5-1B 才突然出现的概念。早在 MiniCPM 系列早期,面壁就已经在验证小参数模型的能力上限。
刘知远团队后来把这种思路进一步概括为“密度定律”:模型能力不只会随着参数规模增长,也会随着数据、训练、架构、后训练和推理系统的进步,在单位参数内持续变密。
过去两年,MiniCPM 系列几乎是在按阶段验证这件事:2024 年,MiniCPM 试图用小模型逼近 GPT-3 级别能力,2025 年,MiniCPM-3 把目标推到 ChatGPT 级别,到 2026 年,MiniCPM5-1B 已经开始逼近甚至超过早期 GPT-4o 了。
端侧模型不是永远只能做云模型的“简化版”。只要智能密度继续提升,原本只能放在云端的大模型能力,就会被端侧模型一点点吃掉。
今天吃掉的是摘要、问答、轻量 Agent、本地知识库和离线助手,下一步可能就是设备控制、车机交互、本地办公、个人助理和端侧代码工具。
这次开源周,恰好把“密度定律”拆成了几个可见的工程环节。UltraData 提高的是数据密度。ForgeTrain 提高的是训练密度。MiniCPM5-1B 提高的是参数密度。BitCPM-CANN 提高的是内存密度。PilotDeck 提高的是应用密度。
这套方法论也不是凭空长出来的。面壁的技术根脉可以追溯到 OpenBMB 社区、CPM 系列和 MiniCPM 系列,也可以追溯到 BMTrain 分布式训练框架、BMInf 推理工具、InfLLM 稀疏架构、BitCPM 低比特路线、CPM.cu 推理框架等底层基础设施。
这些项目看起来分散,但指向的是同一件事:让模型在更小的参数、更低的内存、更弱的设备和更真实的应用场景里,尽可能保留更多智能。
这也是面壁智能的特殊之处,它把端侧模型的方法论,变成了自己的公司方法论。模型不靠参数体量取胜,公司也不靠资源体量取胜,它真正押注的,是在有限资源里压进更多智能。
1
面壁的端侧 AI 定义权
现在已经不是 2023 年。大模型的竞争早已越过参数堆叠、榜单卡位和 API 价格战。过去两年,全球 AI 格局最深的结构性变化,是模型能力正从云端系统性地下沉到设备端。
苹果发布 Apple Intelligence 时,把端侧模型与 Private Cloud Compute 并列;微软定义 Copilot+ PC,用 40 TOPS NPU 和本地 AI 能力划出新一代 PC 的准入门槛;高通、联发科这些芯片巨头,也在以季度为单位反复强调 on-device AI 的战略优先级。端侧 AI 早已甩掉“小模型安慰奖”的标签,成为下一代终端体验争夺的核心基础设施。
放到这个背景下,面壁开源周的分量会更清楚。过去三年国内以开源周形式集中发布技术成果的,此前只有 DeepSeek(2025 年 2 月),面壁是第二家。办一场开源周的门槛在幕后,既要有连续稳定交付高质量成果的工程化能力,也要有敢把底牌全摊开的战略自信。面壁这次一口气公开了从数据、训练框架、模型、压缩到 Agent 操作系统的全链路,这本身就是一次能力声明。
面壁在端侧上的布局,比多数人以为的更早。端侧 AI 成为行业共识不过是最近一两年的事,面壁早在 2024 年就把它定为主线,而支撑这条主线的开源底子还要往前推。
2022 年中国大模型尚未真正起势,面壁联合清华 NLP 实验室发起的 OpenBMB 社区就已经运转,做出国内最早一批系统的免费大模型公开课,累计数百万播放,成了不少从业者的入门教程。

OpenBMB 与 OpenAI、英伟达一起赞助小模型黑客松比赛
据公开数据,如今 OpenBMB 在 GitHub 的星标超过 13 万,位列全球开源组织前一百,MiniCPM 全系列全球下载量超过 3000 万次;2024 年 Hugging Face 统计全球最受欢迎的大模型时,OpenBMB 的下载量排在中国区第一。
把开源根基和端侧主线加在一起,面壁在这条路上已经走了四年。
这正是“小钢炮模型团队”和“端侧系统工程公司”的分界。前者的护城河是某一个出色的模型,后者的护城河是一整条短期复制不了的链路。MiniCPM5-1B 的权重是开源的,谁都能下载,但产出它的数据治理、训练框架、压缩方法和多年工程迭代,下载不到。把全套家底摆上台面、还能保持身位,这比任何榜单分数都更能说明底气在哪。
再往深一层,面壁踩中的是一条对中国格外要紧的线。BitCPM-CANN 是在华为昇腾上完成端到端训练的 1.58-bit 低比特大模型,ForgeTrain 在英伟达 H100 上比 Megatron 快约一成,在昇腾上比华为自家的 MindSpeed 还快约一成。这两件事叠在一起,指向一个比工程水平更大的命题,训练基础设施的生产权正在松动。过去做大模型,很大程度上要跟着英伟达的软件栈走,框架支持什么,大家才能做什么;当一家中国公司能在国产算力上把训练框架做到反超原厂,端侧模型、国产芯片和开源就有机会拼成一套不依赖单一软件生态的技术栈。对国内行业来说,这盘棋比一款端侧模型大得多。
汽车、PC、机器人、智能硬件,是这条路线的外显场景。纯端侧汽车助手 cpmGO 把 MiniCPM 推进智能座舱,MiniCPM 进入 OpenVINO 等 AI PC 工具链。目前面壁已与联想、吉利、上汽大众、广汽、马自达、红旗等头部企业建立合作,在汽车、PC、手机和智能硬件等终端场景里,持续检验端侧模型扛不扛得住功耗、延迟、交互和稳定性的压测。
放眼国内,推进端侧适配、推出过轻量模型的公司不少,但能把端侧 AI 当成战略主线持续投入,从数据、训练、压缩、芯片一路打到产业场景的,并不多。面壁真正想拿下的是一个更大的位置,中国端侧 AI 的技术定义权。
端侧 AI 真正的难度,在于要在功耗、内存、算力、芯片、系统和应用之间做一整套协同设计。这种能力买不到,也快不起来,只能一年一年长出来。面壁提前进场换到的,正是这种很难被追平的结构性领先。在这场关于端侧 AI 定义权的竞赛里,时间本身就是护城河。